背景
知乎Hadoop集群上每天執行著大量的Spark作業,包括排程平台送出的例行作業、Kyuubi送出的Spark SQL作業,每天Spark作業的Shuffle量達到3PB以上,單個Spark作業Shuffle量最大接近100TB,單個Stage 50TB。 同時Hadoop集群上每天有1PB左右的MR作業Shuffle,以及DataNode的磁盤IO。
Sp ark ESS Shuffle在大作業穩定性上更有優勢,在Executor意外結束或者GC嚴重時,已經完成的Map端的Shuffle數據,可以繼續被下遊讀取,不受影響,所以知乎使用的是ESS(External Shuffle Service)作為Spark的Shuffle服務。
但是ESS也有自己的局限性,ESS Shuffle過程中,每個Reducer Task需要去每個上遊Mapper Task的輸出檔中讀取屬於自己的Block,從而產生大量的網路連線以及隨機IO,大量的隨機IO會導致容易達到磁盤的IOPS瓶頸,作業效能和穩定性都會明顯下降 [1][2]。在知乎,經常遇到IO負載高的節點導致個別Spark作業Shuffle Read耗時不穩定甚至超時導致的作業執行耗時不穩定、失敗等問題。下圖可以清楚的描述ESS Shuffle過程中的磁盤讀取及網路連線情況:
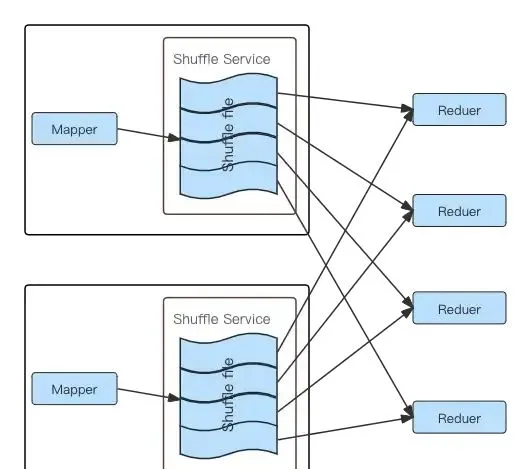
Spark ESS Shuffle 流程圖
為了更好的表述ESS Shuffle存在的問題,借用LinkedIn論文中的一張Shuffle數據統計圖,圖中很清楚的描述了使用ESS Shuffle時,5000個樣本作業不同Shuffle Stage的平均Shuffle Read Block大小分布,以及作業平均Shuffle Read Block大小與作業Task Shuffle Read耗時關聯關系。從圖中不難看出,存在大量的KB級別的Shuffle Read Block(每個Block至少會一次磁盤IO),而且Shuffle Read Block越小,整體Shuffle Read耗時更長。
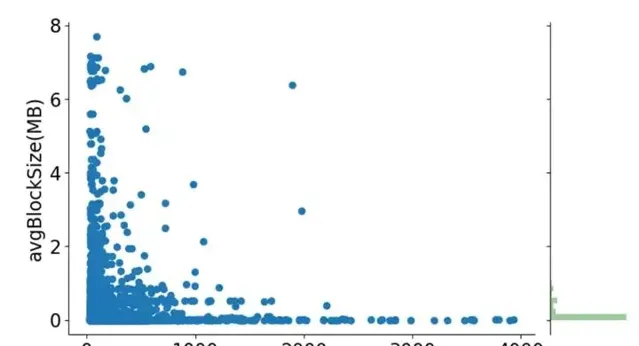
作業ShuffleBlock大小均值、Task Shuffle Read耗時均值的分布
ESS生產環境個別Task ShuffleRead 10M數據10min+
針對ESS 的問題,業界提出了Push Based Shuffle方案,核心思路是Mapper Task Shufle數據不寫本地磁盤,而是寫入一個遠端Shuffle服務(RSS),同一個Reducer Task的數據寫入到同一個遠端節點,遠端Shuffle節點對同一個Reducer Task的數據進行合並,當Reducer Task讀取數據時只需從一個節點的連續的磁盤空間讀取,下圖清楚的描述了RSS在Shuffle過程中磁盤讀取時與ESS的不同:
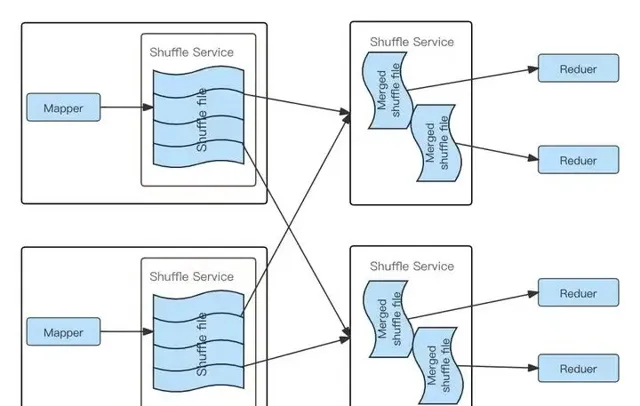
Spark RSS Shuffle流程圖
Spark RSS 實作調研
RSS有不少開源實作,我們主要關註了兩個國內大廠的開源實作,騰訊開源的Apache Uniffle以及阿裏開源的Apache Celeborn。Uniffle在知乎之前的在離線混部計畫中有使用,當時的Celeborn版本還不支持MR作業,而我們需要同時把符合條件的MR、Spark作業排程到混部Hadoop集群,該計畫就選擇了Uniffle,很好地支持了知乎的在離線混部計畫,參考【知乎k8s在離線混部-離線篇】。
在本次大數據作業遷移RSS計畫中,我們跟Celeborn社群進行了一次交流,Celeborn社群給介紹了下Celeborn的特性,發現Celeborn具有一些吸引我們的特性,比如平滑升級、磁盤容錯、基於磁盤負載的排程等,同時Celeborn也已經支持了MR作業,於是我們重新對ESS、Uniffle、Celeborn做了一次對比測試。
我們在測試環境中使用TPC-DS 3000sf數據集進行了ESS、Celeborn、Uniffle對比測試,在我們的測試場景Celeborn、Uniffle查詢效能相比ESS都有明顯優勢,Celeborn與Uniffle差距不大,同時Celeborn的記憶體消耗更低,下圖是在測試環境ESS與Celeborn的耗時比值,數值是ESS耗時相對Celeborn耗時的倍數,大於1代表ESS更慢:
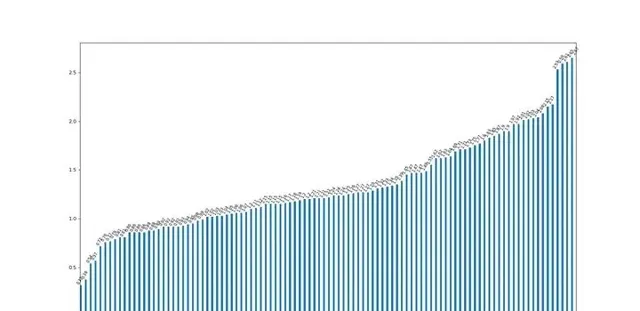
ESS與Celeborn查詢耗時比值(大於1表示ESS耗時高於Celeborn)
線上環境相對測試環境磁盤負載要高很多,我們線上環境目前確實存在嚴重的隨機Shuffle問題,理論上線上環境RSS相對ESS的優勢會更大一些,所以選擇RSS勢在必行;另外,考慮到我們在測試中Celeborn相對Uniffle的記憶體消耗優勢,以及Celeborn社群介紹的平滑升級、磁盤容錯、基於負載的排程的特性,最終我們選擇了線上上環境部署Celeborn。
Celeborn 上線
Celeborn 部署
在Celeborn之前,知乎使用ESS為Spark、MR作業提供Shuffle服務,ESS嵌入在NodeManager服務中,為了更好的ESS效能,緩存更多的Shuffle 分區後設資料資訊到記憶體,給NodeManager配置了比較高的記憶體。
我們上線RSS的目標除了解決Spark作業Shuffle穩定性和效能問題,同時希望不增加額外的機器成本,最終RSS可以完全平替ESS,所有作業遷移到RSS後,下線ESS,降低NodeManager的資源配置,整體不因為部署RSS增加資源開銷。所以我們最終確定Celeborn跟Hadoop集群混合部署,每一台Hadoop節點部署一個Celeborn Worker服務。
為了保障Spark作業遷移到RSS過程的穩定性,作業分批進行灰度遷移,前期只在部份機器上部署Celeborn Worker服務,同時為了驗證Spark作業遷移到RSS後是否確實有收益,在灰度上線階段,避免ESS和RSS共用磁盤互相影響,我們對RSS使用的磁盤及ESS使用的磁盤進行了隔離,每台Hadoop機器有12塊磁盤,DataNode依然同時使用所有磁盤,但是配置ESS只使用其中的10塊磁盤,RSS使用另外2塊磁盤,整體部署架構如下:
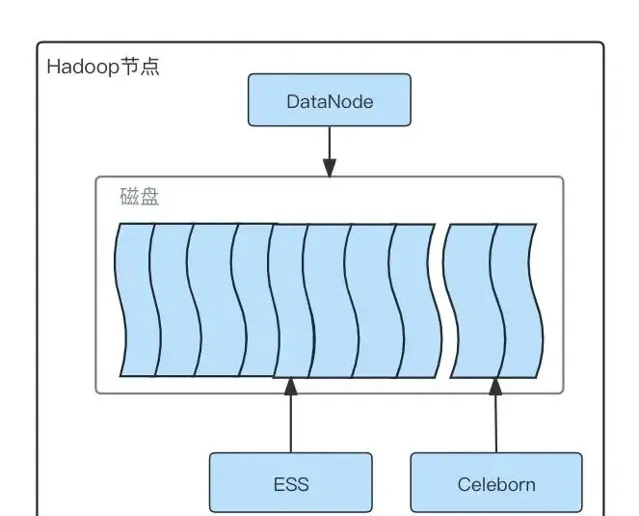
Celeborn部署磁盤分配圖
Spark 作業遷移 Celeborn
遷移Spark作業到Celeborn Shuffle,需要解決兩個問題:
1. 在灰度遷移過程中,如何對遷移的作業自動添加Celeborn相關Spark參數,如設定CelebornShuffleManger、Celeborn Master地址等,異常時支持快速回滾,避免人工手動修改;
2. 哪些作業更適合優先灰度遷移到Celeborn Shuffle。
針對自動修改Spark作業Celeborn參數問題,知乎之前做過一個Spark作業自動最佳化資源參數的計畫,該計畫支持透過規則自動修改Spark作業參數。在該計畫中,透過改造Spark Launcher模組的邏輯,在Spark Launcher模組中采集使用者Spark作業參數,使用采集的參數請求作業最佳化服務,作業最佳化服務基於不同規則計算新的Spark作業參數返回給客戶端,客戶端在收到返回的新參數後,修改使用者原始參數,並使用新參數送出Spark作業。這個計畫正好可以用到我們灰度遷移Spark 作業到Celeborn上,透過增加新的參數修改規則,以及黑白名單控制該規則對哪些佇列、哪些作業生效,即可做到對我們預期的作業自動增刪Celeborn參數。整體流程如下:
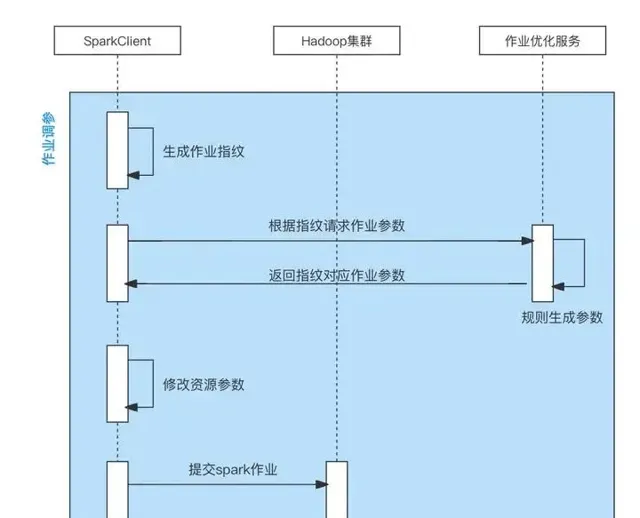
自動調整Spark作業Celeborn參數
在選擇哪些作業優先灰度到RSS時,我們綜合考慮了作業的優先級、作業Shuffle Read Block數、作業Shuffle Read Block平均大小(我們在Spark作業自動調參計畫中采集了每個作業Shuffle Read大小、Shuffle Read Block數等Metric資訊),為了降低RSS異常時對業務的影響以及盡快減少ESS磁盤IO壓力,前期我們優先遷移的是作業優先級低的、Shuffle Read Block數多的、平均Shuffle Read Block Size小的作業,灰度幾個批次後,符合條件的作業都已經遷移完成,後期就直接按照佇列和作業優先級遷移了。
Celeborn 升級
知乎最初部署Celeborn時,是基於社群Release 0.3.1之後的main分支部署的,截止到我們遷移完所有Spark jar包型別的作業,我們部署的Celeborn已經落後社群最新程式碼幾百個Commit,有些急迫的特性我們透過patch的方式在我們公司用了起來,但我們也想追齊社群最新的程式碼,包括一些bug的修復以及新特性。中間穿插著patch過幾個社群的修補程式,繼續patch剩余修補程式會有大量沖突,我們最終選擇了使用社群最新程式碼直接替換我們在用的程式碼。
這樣要面臨一次整體集群的升級,Celeborn 支持捲動升級,無論是升級還是下線,都能夠在不影響當前正在執行的作業的情況下進行。這種優雅的升級和下線方式,保證了業務的連續性和穩定性,避免了長尾作業的等待時間,提高了運維效率。
而且在部署層面,運維的感知就是部署了一個程式,然後檢測到程式啟動即可,很多的狀態等等恢復工作 Celeborn 都會自動完成,不需要運維幹預,相較於常規部署與升級 Hadoop 要簡單很多。
同時這次的升級我們全程都在正常的工作時間進行,搭配自身的 Ansible 運維平台,我們只需極低的運維開發就可以實作數千個 Celeborn Worker 節點的運維。
Celeborn 相容 Spark1.6
前面介紹過,我們最終的目標是期望Celeborn可以平替ESS,所有Spark作業的Shuffle都遷移到Celeborn,但是Celeborn官方不支持Spark1.6(發現所有的RSS開源實作都沒有支持Spark1.6版本)。跟Celeborn社群交流後得知Celeborn之所以沒有支持Spark1.6,是因為目前使用Spark1.6的公司已經很少,並不是無法支持。
但是知乎還有不少歷史作業是使用Spark1.6實作的,每天大概600個作業,當時評估推動業務方升級作業Spark版本到Spark2、Spark3很困難,為了把所有Spark作業都遷移到RSS,我們自己實作了Celeborn Spark1.6的客戶端,支持Spark1.6作業。
Spark1客戶端相對於Spark2、Spark3版本最主要的不同在於處理Stage重試相關邏輯。Celeborn Spark高版本客戶端在發生Shuffle Fetch Failed異常觸發Stage重試時,透過Spark的MapOutputTracker介面清理異常Stage上遊所有Map的輸出,依賴TaskContext中的stage重試次數資訊,決定是否生成新的Celeborn內部ShuffleID。Spark1中MapOutputTracker介面、TaskContext欄位資訊跟高版本不同,針對Spark1的Stage重試,我們在Celeborn側ShuffleWriter嘗試獲取ShuffleID時,是否生成新的ShuffleID不依賴Stage重試資訊,而是依賴當前Stage在用的ShuffleID是否發生了ShuffleFetch異常,發生過異常,則在後面同一個Shuffle Stage的Write任務申請ShuffleID時,分配新的ShuffleID;Spark側在開啟Celeborn Shuffle的情況下,發生Stage重試時,內部直接清理Shuffle Stage Output資訊,保障重試時上遊Stage所有Task的重新送出。
目前已經在所有Spark1.x作業上線,執行穩定,並且遇到異常Celeborn Worker節點導致FetchFailed時,可以觸發Stage重試並成功。
遇到的問題
Kyuubi Spark SQL上線Celeborn後無法建立執行緒
知乎使用Kyuubi管理支持Spark SQL Adhoc查詢的不同租戶的Spark引擎,在兩台高配伺服器上部署了Kyuubi服務,Kyuubi服務在兩台伺服器上啟動不同租戶的多個Spark Yarn Client模式的例項用於支持公司所有使用者的Spark SQL Adhoc查詢。我們將Kyuubi啟動的Spark作業Shuffle也遷移到了Celeborn。
在一次Celeborn服務從500節點擴容到700節點後,每當使用者查詢高峰時間段,所有Spark Driver日
誌中都會有
OutOfMemoryError: unable to create new native thread
線
程建立異常的報錯,導致大量使用者查詢失敗,此時機器及Jvm記憶體都遠沒有達到上限。
透過跟Celeborn社群的交流,以及統計分析Spark Driver的執行緒棧,發現Celeborn針對每個Shuffle Stage都會啟動新的執行緒池用於向分配給當前 Stage Shuffle資源的節點建立連線、預留Slot、送出Commit數據,而在我們的Kyuubi Spark Adhoc場景,每個Spark作業中可能同時執行大量SQL,大量的Shuffle Stage,單個Driver行程執行緒數高峰可能達到接近1w+個,其中Celeborn InitWorker、ReserveSlot、CommitFiles相關的執行緒累計8k+,當Worker節點是500時,因為需要連線的Worker相對少,擴容到700後,需要建立更多執行緒連線更多的Worker節點,懷疑執行緒數達到了上限。
在該問題發生時,我們檢查了機器作業系統配置的執行緒數、行程數上限,分別是400w+、30w+,機器上實際啟動的執行緒數並沒有達到這個上限。在知乎,Kyuubi服務是透過Systemd啟動的,Spark Driver行程都是Kyuubi的子行程,我們最終發現達到的上限是Systemd的DefaultTasksMax限制的,該配置會限制Systemd啟動的服務以及該服務所有子行程可以使用的執行緒數上限(所有子行程累加),因為問題發生時,機器記憶體、CPU等資源還很富裕,所以我們增加了Systemd DefaultTasksMax的配置暫時解決了這個問題。
後續Celeborn社群對執行緒池建立相關邏輯進行了最佳化,不同Shuffle復用同一個InitWorker、ReserveSlot、CommitFiles執行緒池,目前該最佳化也已在知乎上線,大幅最佳化了建立的執行緒數。
Spark 作業設定 Celeborn 參數後不生效
對於遷移到Celeborn的作業,我們關閉了ESS,灰度遷移過程中,我們發現有個別作業執行更不穩定了,排查日誌發現作業實際Shuffle的時候,並沒有使用Celeborn,而是用了Spark原生Shuffle,Executor多次被驅逐導致作業不穩定。之所以開啟了Celeborn Shuffle,最終卻沒有使用Celeborn Shuffle的原因是我們透過--jars參數配置的Celeborn客戶端Jar,同時使用者作業設定了參數 spark.executor.user classPathFirst=true 。同時設定該參數以及開啟Celeborn Shuffle後,完整的Shuffle處理流程是:
1. Spark Executor啟動的時候,檢查到spark.executor.user classPathFirst配置為True,則初始化ChildFirstURL classLoader並在建立Task執行執行緒的時候設定執行緒 Context classLoader 為 ChildFirstURL classLoader 。
2. Executor使用Context classLoader中的ChildFirstURL classLoader反序列化接收到的Spark Task資訊,其中就包括Task相關的RDD、ShuffleDependency等,ShuffleDependency中包含了ShuffleHandle例項
3. ChildFirstURL classLoader的實作截斷了Java classLoader的雙親委托模型,優先使用ChildFirstURL classLoader自身去載入類,載入不到的情況下,才透過父載入器去載入,所以ChildFirstURL classLoader反序列化Task資訊的時候,載入了CelebornShuffleHandle,並反序列化了ShuffleHandle例項。
4. Spark Executor預設的類載入器還是java預設的App classLoader,所以當直接參照CelebornShuffleHandle類時(
instanceof
檢查時),會使用App classLoader載入CelebornShuffleHandle類。
5. Celeborn SparkShuffleManager 在建立 ShuffleWriter、ShuffleReader 時,會檢查當前 ShuffleHandle 例項是否是 CelebornShuffleHandle 型別,然而因為當前 ShuffleHandle 例項是透過 ChildFirstURL classLoader 載入建立的,而 SparkShufflleManager 內部的 CelebornShuffleHandle 類是使用 App classLoader 載入的,兩邊 CelebornShuffleHandle 是使用的不同類載入器載入的,檢查結果是 False ,最終使用了 Spark 原生的 Shuffle。
跟業務溝通後,發現業務作業可以去掉spark.executor.user classPathFirst=true參數配置,最終該問題透過修改作業參數解決。
Spark 作業中包含 GlobalLimit 算子時使用 RSS 問題
Spark Adhoc查詢Shuffle切換到RSS後,業務反饋有個Spark SQL查詢執行多次,總是失敗。透過檢視作業執行計劃以及作業執行日誌,發現因SQL語句中包含了Insert Hdfs Directory以及Limit邏輯,生成的作業執行計劃中包含了GlobalLimit算子,而GlobalLimit算子會觸發Shuffle,並且Shuffle下遊並列度是1,同時該SQL作業結果在Limit之前的數據規模很大,TB級別。
在切換到RSS之前,GlobalLimit算子在進行Shuffle的時候,每個上遊Task數據都是寫本地,下遊Task在Shuffle Read到Limit限制的數據後就結束了;切換到RSS之後,上遊Task數據是寫到RSS節點,並且屬於同一個Reduce Task的數據會寫到同一個RSS節點,也就是TB級別的數據會寫同一個RSS節點,直接導致該RSS節點因數據寫入太快,記憶體使用過高被Exclude,SQL執行失敗。
GlobalLimit算子問題在我們這邊是普遍存在的,在知乎Spark是Adhoc的底層查詢引擎之一,每天會有大量的Spark SQL Adhoc查詢,大量的Spark SQL查詢復用一批Spark執行環境,節約啟動耗時。為了減少復用的Spark環境的Driver記憶體壓力,我們會自動修改使用者的SQL,添加查詢結果Insert Hdfs Directory的邏輯,查詢平台再從Hdfs上讀取結果給使用者展示,同時在使用者沒有主動添加Limit的情況下,我們會自動給使用者添加Limit限制。
這個問題不能透過修改單個SQL進行解決,我們調研發現Spark中有一個LocalLimit算子,該算子可以限制每個Spark RDD Partition的結果數據行數,於是我們的解決思路,就是給Spark添加一個執行計劃最佳化規則,當執行計劃中包含GlobalLimit算子,並且GlobalLimit算子的上遊是一個Project算子(即Select)的情況下,自動在GlobalLimit算子前添加一個LocalLimit算子。
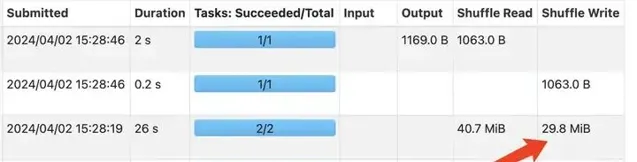
增加LocalLimit之前GlobalLimit算子Shuffle數據量
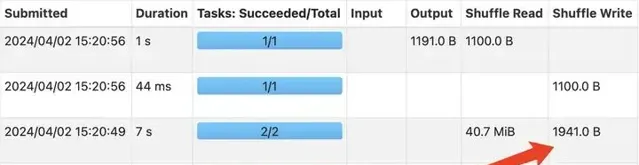
增加LocalLimit之後GlobalLimit算子Shuffle數據量
上面兩張圖是使用測試查詢驗證規則上線前後的效果對比情況,該規則上線後,GLobalLimit算子觸發的Shuffle中,每個上遊Task只需要Shuffle Write Limit限制的條數數據到RSS節點,不會再導致RSS節點Exclude,Limit前TB級數據規模的查詢也可以正常執行,這種Case查詢效能和穩定性都明顯最佳化。
節點負載高導致 Shuffle 不穩定
知乎Celeborn是跟Hadoop部署到同一批機器上的,在作業灰度遷移的過程中,偶爾會發生個別機器負載很高,導致Commit超時或者Spark跟Celeborn通訊超時,觸發Shuffle異常,影響了作業執行穩定性,針對該問題,我們做了幾個調整
增加Celeborn Shuffle RPC、Commit超時時間;
增加Worker Flush Buffer Size,從256K調整到1M,最佳化Commit耗時;
上線Celeborn基於磁盤負載的排程,所有磁盤分5組,每組之間Slot分配比例差距1.1倍,計算磁盤負載時Fetch、Flush耗時系數都是0.5;
打Celeborn社群Stage重試的修補程式,當發生Shuffle 異常時,觸發Stage重試,而不是App重試。
Celeborn Worker 連線數過高
灰度上線過程中,我們發現每個Worker節點的連線數很高,高峰時有的Worker 連線數達到1w個左右,跟社群溝通後,我們限制了每個作業最大使用的Worker節點數為500個,在後續我們持續擴容Worker節點數、遷移作業過程中,連線數基本穩定,沒有持續增長。
celeborn.master.slot.assign.maxWorkers 500
收益
目前RSS使用1/6的集群磁盤資源,接入集群1/3+的Shuffle流量,作業遷移到RSS Shuffle後,作業執行效能明顯最佳化,每天所有作業99分位數耗時提升30%以上;在持續有新作業上線的情況下,作業資源占用呈現下降的趨勢。
作業效能最佳化
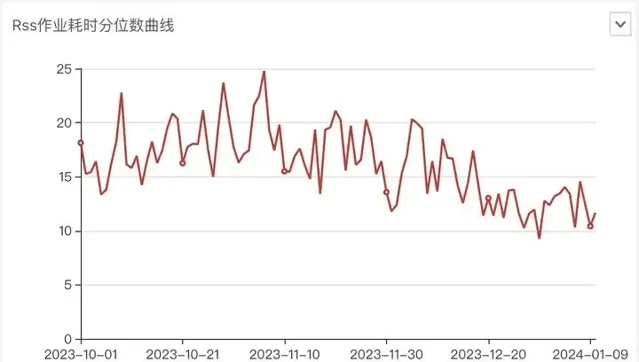
遷移RSS過程中 Spark作業耗時均值變化

遷移RSS過程中 Spark作業耗時99分位數變化
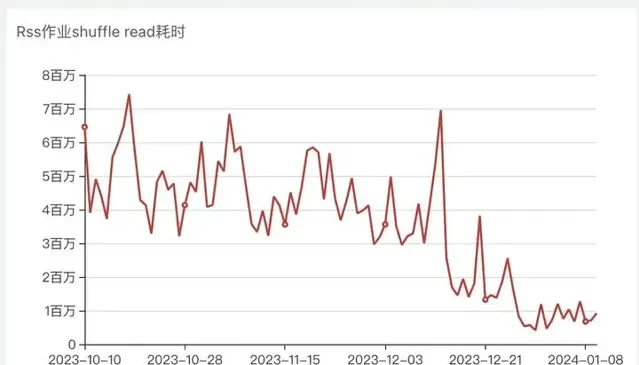
遷移RSS過程中 Spark作業Shuffle Read耗時變化
從作業整體分位數耗時、Shuffle耗時曲線看最佳化明顯,大作業提速明顯,所有作業99分位數耗時最佳化30%以上。
從使用者反饋看,已經接入RSS Shuffle的作業,在效能和穩定性上都有了明顯最佳化,業務方主動反饋作業變快了,近期我們也已經基本沒有再收到使用者反饋的shuffle耗時不穩定、shuffle連線異常等問題。
因為1/3以上的Shuffle流量切到了RSS,但是給RSS的磁盤只有整個集群的1/6,所以對於沒有接入RSS的作業,也有明顯的最佳化,公司核心例行作業結束時間提前了一個小時以上。
資源使用最佳化
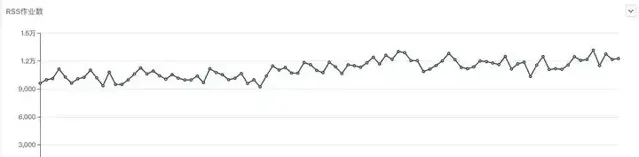
遷移RSS過程中 Spark作業每日作業數變化
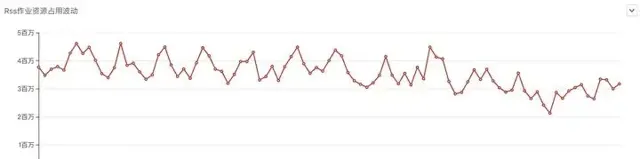
遷移RSS過程中 Spark作業每日記憶體資源占用變化
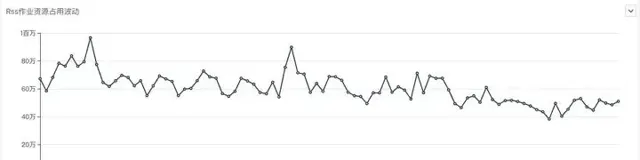
遷移RSS過程中 Spark作業每日CPU資源占用變化
從作業資源占用的角度看,也是有一些最佳化的,從截圖中,可以看出,在RSS上線遷移過程中,公司一直有新作業上線,及時新增作業的情況下,所有作業CPU、記憶體占用有明顯的下降趨勢。
總結與展望
目前所有Spark Jar包、Spark SQL Adhoc作業均已接入RSS,並且取得了不錯的效果,後續我們想在RSS方向繼續做的事情包括:
Spark SQL ETL作業接入Celeborn
MR作業接入Celeborn
下線ESS服務,降低NodeManager記憶體占用
Celeborn更好的相容高負載節點
參考
2. 知乎k8s在離線混部-離線篇
https://zhuanlan.zhihu.com/p/636970123
3. Magnet: Push-based Shuffle Service for Large-scale Data Processing
https://www.vldb.org/pvldb/vol13/p3382-shen.pdf











