
導讀 貨拉拉大數據團隊在成立三年內解決了諸多業內難題,取得了一些階段性成果。在本次分享中,貨拉拉高級大數據工程師朱耀概,深入探討了在工作中遇到的關於大數據基礎架構的挑戰與實踐,以及對未來的展望。
本次分享的主要內容包括:
1. 背景與挑戰
2. 基礎架構實踐
3. 總結與思考
4. 未來展望
分享嘉賓| 朱耀概 貨拉拉 高級大數據工程師
編輯整理|李可欣
內容校對|李瑤
出品社群| DataFun
01
背景與挑戰
1. 貨拉拉介紹

貨拉拉是一家集貨運、搬家、跑腿等業務場景於一體的多邊線上交易平台,成立於2013 年,在粵港澳大灣區取得了飛速發展。目前業務已覆蓋全球 11 個市場,包括中國及東南亞、南亞、南美洲等地區。貨拉拉作為一家擁有 1050 萬月活使用者、90 萬月活司機的貨運物流交易平台,擁有 8 條業務線覆蓋國內 360 個城市,廣闊的業務量帶來巨量的數據,目前 1000 多台機器的儲存量達 20PB+,7 條 IDC 處理日均 20K+ 的任務。龐大業務量能安全、穩定運轉離不開大數據基礎架構的支撐。
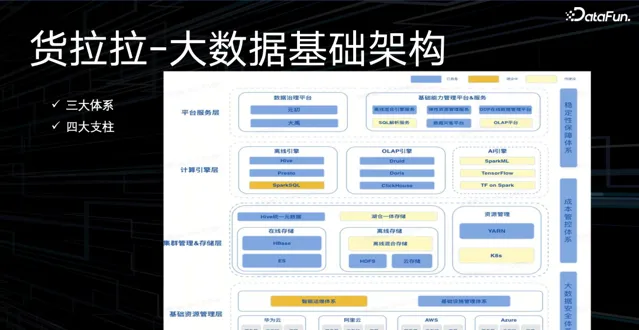
目前貨拉拉大數據團隊已完成三大體系(大數據安全體系、成本管控體系、穩定性保障體系)和四大支柱(平台服務層、計算引擎層、集群管理&儲存層、基礎資源管理層)的大數據基礎架構建設。
平台服務層提供數據 治理能力和基礎平台能力服務;
計算引擎層包含離線引擎、 OLAP 引擎、(規劃中的) AI 引擎;
集群管理 & 儲存層包含線上儲存(如 ES 和 HBase )、離線儲存( HDFS 、雲端儲存)、資源管理( YARN 、規劃中的 K8s );
基礎資源管理層包含基礎設施管理體系(主要是貨拉拉內部連線的各雲廠商提供的物理資源,及對其進行在地化管控的體系),和正在進行中的智慧運維體系。
2. 問題與挑戰
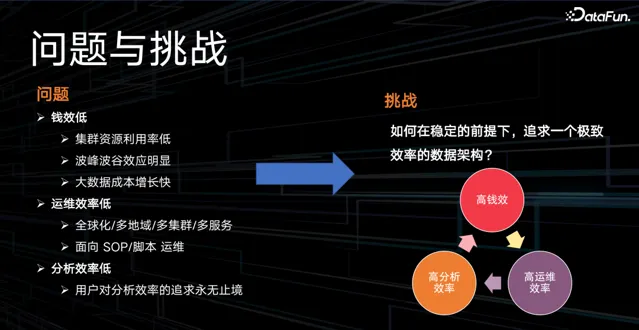
在貨拉拉大數據團隊建設過程中,面臨的問題主要有 3 個:
錢效低,具體表現在:
集群資源利用率低;
波峰波谷效應明顯,采用高峰資源保障,帶來成本浪費;
大數據成本增長快,缺乏對數據的冷熱分層、生命周期的管理;
運維效率低,面對全球化 / 多地域 / 多集群 / 多服務的復雜場景,主要依賴 SOP 和指令碼來保障運維,效率低下; 同時,運維變更的穩定性比較差; 運維人員的工作量繁重,被迫拉長工作時間;
分析效率低,使用者經常吐槽查詢引擎速度太慢,他們對分析效率的追求永無止境。
那麽,如何在保障穩定的前提下,實作高錢效、高運維效率、高分析效率的極致效率數據架構呢?
接下來將分享貨拉拉大數據團隊展開的探索,以及其中的思考與經驗。
02
基礎架構實踐
1. 高錢效
主要從資源彈性、異構計算兩方面實作。
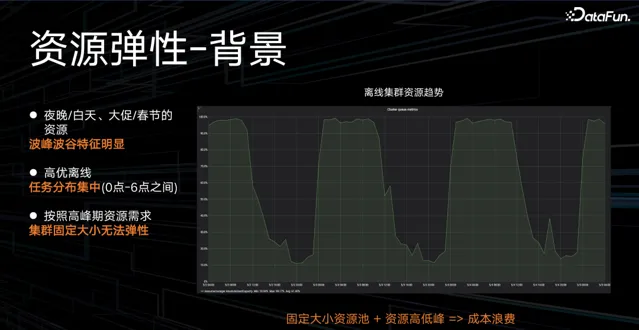
(1)資源彈性
離線計算資源在夜晚/白天、大促/春節等場景下,呈現明顯的波峰波谷特征,離線高優任務的分布也比較集中,主要在淩晨到早上 6 點之間。如果按照波峰的資源水平提供保障,就會造成波谷時段的資源成本浪費。如何讓固定大小的資源池提供彈性的計算資源成為了當務之急。
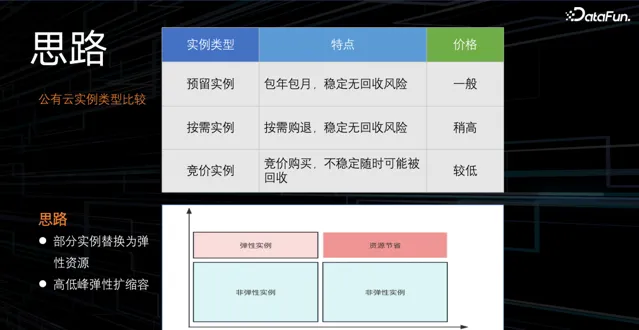
現有公有雲能提供的例項主要分為:預留例項、按需例項、競價例項,相應特點及價格如上。根據各雲廠商能提供的例項特點及價格,貨拉拉大數據團隊將一部份資源例項替換成彈性例項,形成高低峰彈性擴縮容的策略機制。在淩晨至 12 點交易高峰期擴容彈性例項,12 點過後,回收部份彈性例項,進而節省資源。
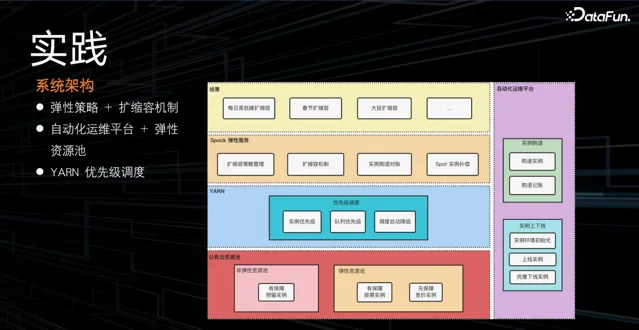
基於上述策略,透過系統架構實作彈性擴縮容服務,系統包含彈性擴縮容策略和機制的管理,並對彈性例項進行購退對賬,防止因遺忘退訂彈性例項而造成的資源浪費;結合自動化運維平台,對彈性例項進行購退和上下線;對 YARN 進行優先級排程的改造,調整例項優先級、佇列優先級,出現問題時進行排程降級,保證任務穩定性。
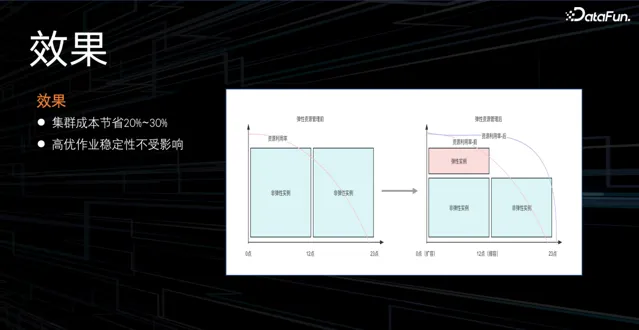
透過資源彈性的管理,集群成本節省 20%~30%,並且保證高優作業的穩定性,同時,也提高了彈性資源的利用率。
(2)異構計算

在計算降本方面,除了資源彈性、計算超賣、計算資源治理外,還有什麽可最佳化的手段嗎?我們將計算節點機型由 x86 替換為了 ARM,以下是 ARM 和 x86 的優劣勢對比:

ARM 在成本和功耗上具有顯著優勢:ARM 的單核成本相較 x86 至少低 15%,且功耗較低,大量套用於移動端。
但 ARM 的整體軟體相容性較差,部份需要適配;同時業內伺服端使用較少。
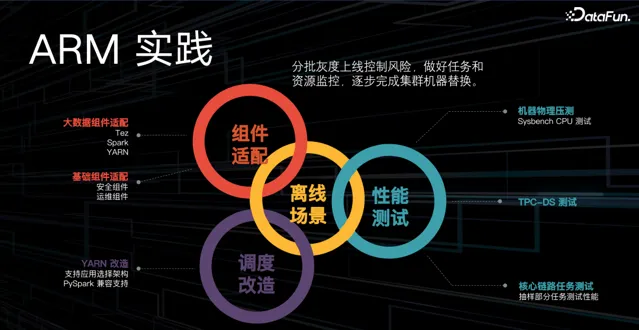
貨拉拉大數據團隊將 ARM 成功套用到大數據架構中,主要做了三部份工作:
首先,元件適配,包括大數據元件適配,例如目前主要使用的計算引擎 Tez 、 spark 、 YARN (某些 java 包等); 和基礎元件適配,例如公司級的安全元件、運維元件等。
第二,在排程改造方面,支持使用者在套用層選擇架構,同時也完成了對 PySpark 的相容支持;
最後在機器物理資源壓測、 TPC-DS 壓測、核心鏈路任務的抽樣測試後發現,使用 ARM 節點後集群效能沒有明顯下降。
整體 ARM 實踐的上線策略遵循分批灰度上線,控制風險,並對任務和資源進行監控,最後逐步完成了集群機器替換。
這裏分享一個問題:在灰度上線的過程中,團隊發現帶視窗函式的 SQL 在物理資源使用正常的情況下,task 的執行時長會被拉長 10 倍。
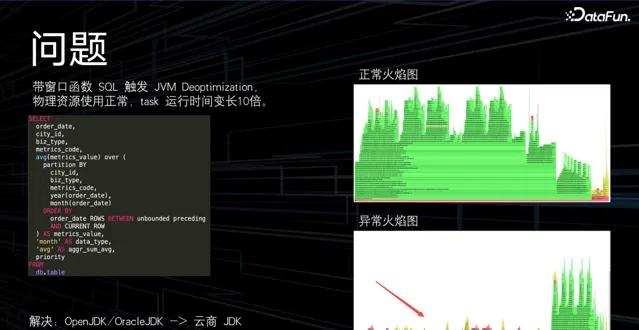
透過對比火焰圖,發現這種 SQL 觸發了 JVM 的逆最佳化,導致大部份 CPU 時間消耗在 JVM 的程式碼中。對於此問題的一個解決方案是,將 ARM 的資源版本替換為雲廠商的版本。
最終在團隊的努力下,完成了離線計算 50%ARM 機型的替換,集群成本節省 10%(大概百萬/年的水平),之所以替換 50%,是因為受限於雲廠商的供給。上線 ARM 機型後,未出現高優作業的延遲故障。
2. 高運維效率
主要從大數據自動化運維、大數據雲原生兩方面實作。
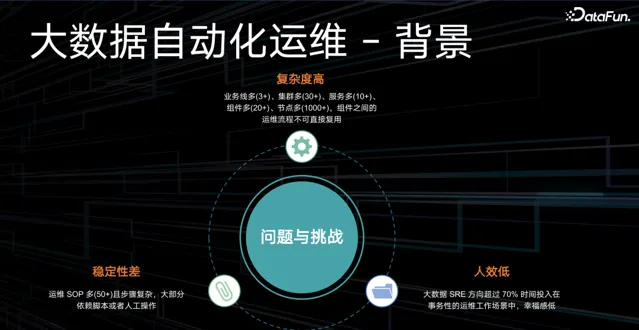
(1)大數據自動化運維
團隊內部大數據運維復雜度很高,面對的是 3 個業務線、30 多套集群、20 多個服務元件、上千個節點的復雜環境,且元件之間的運維流程不能復用;在如此復雜的場景下,運維主要依賴大量的 SOP,步驟復雜、人工操作、指令碼不靈活;使 SRE 方向的同事超過 70% 的工作時間投入到事務型的運維工作場景中,員工幸福感很低。
根據下圖可以感受一下運維場景的復雜度,如 HBASE 版本釋出的工作流:
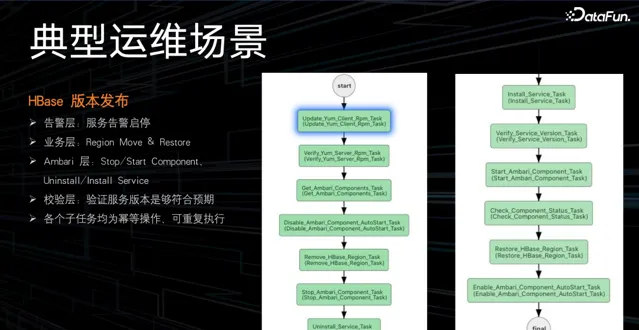
在如此復雜、低效的場景下,如何盡快實作自動化運維呢?
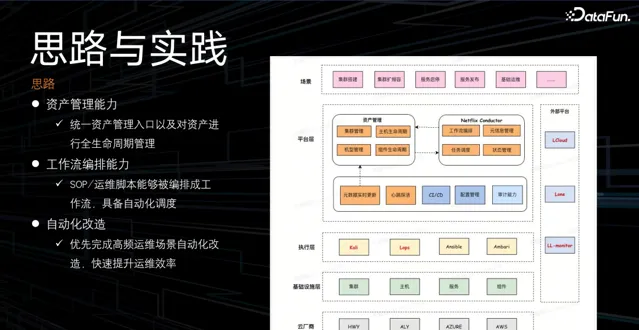
首先,需要構建集群的資產管理能力,可以統一資產管理入口,並對資產進行全生命周期管理;
然後,在工作流編排能力上,將 SOP 和運維指令碼固化成工作流,使其具備分布式排程執行的能力;
最後,優先完成高優高頻場景的自動化改造,快速提升運維效率。
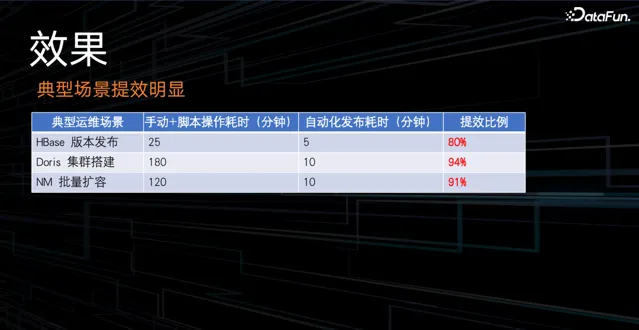
透過實作大數據自動化運維在典型的場景上提效非常明顯。
(2)大數據雲原生
大數據領域主要關註的問題就是容器化和 DevOps,相對應的就是成本和效率。在成本方面,將 YARN 替換成 K8s,統一在離線資源池,為在離線混部打下基礎;運維效率方面,面向 K8s 的運維比面向傳統機器的運維要方便很多。
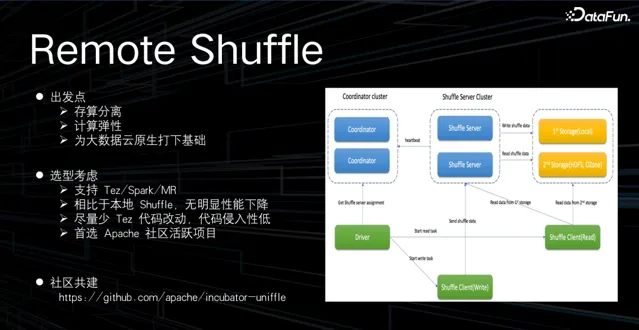
之所以做 Remote Shuffle 框架,主要基於以下考慮:
出發點是將計算節點原生的 shuffle 數據保存到遠端,原生的計算節點就可以實作無狀態化,計算節點便可進行容器化部署,為大數據雲原生打下基礎。
因為貨拉拉使用 Tez 計算引擎,在選型方面主要考慮: 通用性,能支持 Tez 、 Spark 、 MR ; 相比本地 shuffle ,無明顯效能下降; 提供高可用的能力,且對 Tez 源碼盡量少改動、侵入; 首選 Apache 社群活躍計畫。
經過對業界 RSS 框架的對比,與社群進行深度共建,最終選擇騰訊開源的 Uniffle 框架,團隊牽頭設計 Tez Client 方案,向社群貢獻了近 2 萬行程式碼,成功讓 Uniffle 框架支持 Tez。目前 RSS 在公司內部逐步灰度上線中。除了 RSS 外,團隊還實施了 Flink on YARN 替換成 Flink on K8s 的方案。
3. 高分析效率
即引擎提效。
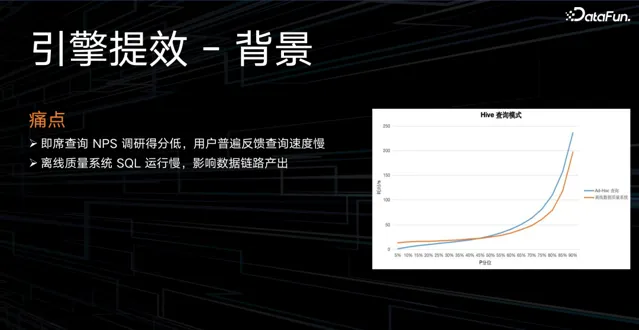
使用者在即席查詢過程中,經常遇到的一個痛點就是查詢速度慢。在離線 ETL 鏈路中,團隊會對一些庫表進行數據品質的校驗,如果 SQL 執行慢,也會影響數據鏈路的產出。
針對使用者的痛點,團隊開發了離線混合引擎服務。
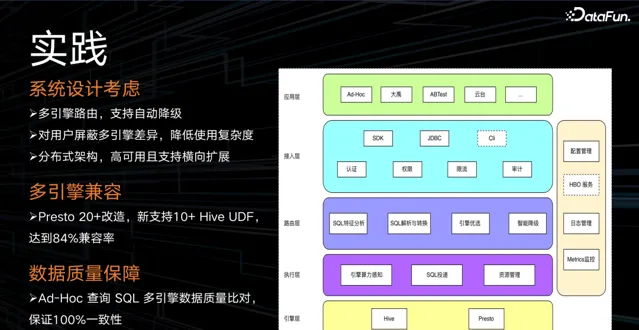
在系統設計時,主要考慮以下三點:
多引擎路由,支持自動降級。 主要思想是根據各引擎優缺點,將 SQL 路由到最適合它的計算引擎上。 透過觀測 SQL 的執行計劃,查詢數據掃描量和算子分布,匹配路由策略,最終分配到合適的計算引擎上。 如果 SQL 執行失敗,將自動降級到其他引擎。 若所有引擎都執行失敗,由 Hive 做兜底,保證執行成功。
對使用者遮蔽多引擎差異,降低使用復雜度。 不會更改使用者使用習慣,使用者以 Hive 語法編寫 SQL ,後台進行 SQL 轉化,對使用者遮蔽多引擎語法的差異。
分布式架構,高可用且支持橫向擴充套件。 為了應對未來的大規模需求。
另外,實作了多引擎相容。透過對 Presto 進行 20+ 改造,包括 Hive 隱式轉換的適配、Hive 檢視的適配、對齊 Hive 的 UDF 語意等,最後達到了 84% 的相容率。
數據品質保障方面,系統在灰度上線之前,將線上真實的 Ad-Hoc 的 SQL 查詢進行多引擎數據對比,保證 100% 透過數據品質校驗。
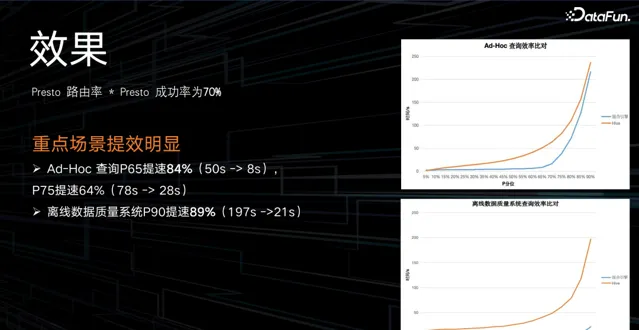
目前 Presto 路由率 * Presto 成功率能夠達到 70%,並且在重點場景提效明顯。
03
總結與思考
高錢效、高運維效率、高分析效率這三大目標驅動了貨拉拉大數據基礎架構的演進。
實踐證明,要透過明確的收益驅動基礎架構演進,引入新技術前多思考,不能貿然引進一些火熱的新技術。目前貨拉拉還未引進湖倉一體,因為其收益尚未明確。在成本和穩定性的基礎上,只要領先業務「半步」即可,不需要過度演進。
04
未來展望
最後,對未來工作的規劃主要包括以下幾大方面:

1. 引擎提效
離線計算引擎由 Hive 遷移到 Spark。
2. 極致彈性
根據負載壓力更精準、及時地彈性伸縮。
3. 大數據智慧化運維
繼續完善對雲原生場景的支持,實作數智化運維(AIOps),做到故障自愈、全鏈路診斷。
4. 離線混部
完善大數據全面雲原生化,繼續探索符合業務場景的在離線混部策略。
5. 流批一體&湖倉一體
進一步探索符合業務需求的落地場景。
以上就是本次分享的內容,謝謝大家。
分享嘉賓
INTRODUCTION
朱耀概
貨拉拉
高級大數據工程師
本科畢業於華南理工大學,先前就職於 vivo,從事過萬億級 vivo 使用者畫像建設,目前就職於貨拉拉,主要從事大數據平台、大數據自動化運維體系建設以及 HBase 穩定性建設,Apache HBase/Kyuubi/Uniffle Contributor 。
往期推薦
點個 在看 你最好看











