ClickHouse 是2016年開源的用於即時數據分析的一款高效能列式分布式資料庫,支持向量化計算引擎、多核平行計算、高壓縮比等功能,在分析型資料庫中單表查詢速度是最快的。2020年開始在滴滴內部大規模地推廣和套用,服務網約車和日誌檢索等核心平台和業務。本文主要介紹滴滴日誌檢索場景從 ES 遷移到 CK 的技術探索。
背景
此前,滴滴日誌主要儲存於 ES 中。然而,ES 的分詞、倒排和正排等功能導致其寫入吞吐量存在明顯瓶頸。此外,ES 需要儲存原始文本、倒排索引和正排索引,這增加了儲存成本,並對記憶體有較高要求。隨著滴滴數據量的不斷增長,ES 的效能已無法滿足當前需求。
在追求降低成本和提高效率的背景下,我們開始尋求新的儲存解決方案。經過研究,我們決定采用 CK 作為滴滴內部日誌的儲存支持。據了解,京東、攜程、B站等多家公司在業界的實踐中也在嘗試用 CK 構建日誌儲存系統。
挑戰
面臨的挑戰主要來自下面三個方面:
數據量大 : 每天會產生 PB 級別的日誌數據,儲存系統需要穩定 地 支撐 PB 級數據的即時寫入和儲存。
查詢場景多 :在一個時間段內的等值查詢、模糊查詢及排序場景等,查詢需要掃描的數據量較大且查詢都需要在秒級返回。
QPS 高 :在 PB 級的數據量下,對 Trace 查詢同時要滿足高 QPS 的要求。
為什麽選 Clickhouse
大數據量 :CK 的分布式架構支持動態擴縮容,可支撐海量數據儲存。
寫入效能 :CK 的 MergeTree 表的寫入速度在200MB/s,具有很高吞吐,寫入基本沒有瓶頸。
查詢效能 :CK 支持分區索引和排序索引,具有很高的檢索效率,單機每秒可掃描數百萬行的數據。
儲存成本 : CK 基於列式儲存,資料壓縮比很高,同時基於HDFS做冷熱分離,能夠進一步 地 降低儲存成本。
架構升級
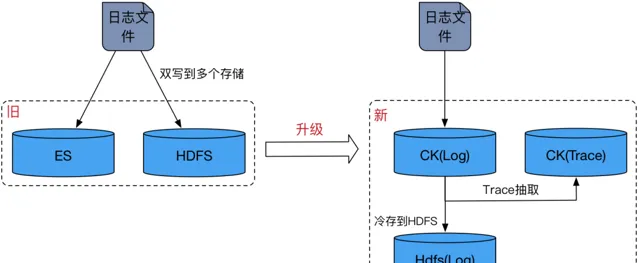
舊的儲存架構下需要將日誌數據雙寫到 ES 和 HDFS 兩個儲存上,由ES提供即時的查詢,Spark 來分析 HDFS 上的數據。 這種設計要求使用者維護兩條獨立的寫入鏈路,導致資源消耗翻倍,且操作復雜性增加。
在新升級的儲存架構中,CK 取代了 ES 的角色,分別設有 Log 集群和 Trace 集群。Log 集群專門儲存明細日誌數據,而 Trace 集群則專註於儲存 trace 數據。這兩個集群在物理上相互隔離,有效避免了 log 的高消耗查詢(如 like 查詢)對 trace 的高 QPS 查詢產生幹擾。此外,獨立的 Trace 集群有助於防止trace數據過度分散。
日誌數據透過 Flink 直接寫入 Log 集群,並透過 Trace 物化檢視從 log 中提取 trace 數據,然後利用分布式表的異步寫入功能同步至 Trace 集群。這一過程不僅實作了 log 與 trace 數據的分離,還允許 Log 集群的後台執行緒定期將冷數據同步到 HDFS 中。
新架構僅涉及單一寫入鏈路,所有關於 log 數據冷儲存至 HDFS 以及 log 與 trace 分離的處理均由 CK 完成,從而為使用者遮蔽了底層細節,簡化了操作流程。
考慮到成本和日誌數據特點,Log 集群和 Trace 集群均采用單副本部署模式。其中,最大的 Log 集群有300多個節點,Trace 集群有40多個節點。
儲存設計
儲存設計是提升效能最關鍵的部份, 只有經過最佳化的儲存設計才能充分發揮 CK 強大的檢索效能 。 借鑒時序資料庫的理念,我們將 logTime 調整為以小時為單 位進行取整,並在儲存過程中按照小時順序排列數據。這樣,在進行其他排序鍵查詢時,可以快速定位到所需的數據塊。例如,查詢一個小時內數據時,最多只需讀取兩個索引塊,這對於處理海量日誌檢索至關重要。
以下是我們根據日誌查詢特性和 CK 執行邏輯制定的儲存設計方案,包括 Log 表、Trace 表和 Trace 索引表:
Log 表
Log 表旨在為明細日誌提供儲存和查詢服務,它位於 Log 集群中,並由 Flink 直接從 Pulsar 消費數據後寫入。每個日誌服務都對應一張 Log 表,因此整個 Log 集群可能包含數千張 Log 表。其中,最大的表每天可能會生成 PB 級別的數據。鑒於 Log 集群面臨表數量眾多、單表數據量大以及需要進行冷熱數據分離等挑戰,以下是針對 Log 表的設計思路:
CREATETABLE ck_bamai_stream.cn_bmauto_local(`logTime` Int64 DEFAULT0, -- log打印的時間`logTimeHour` DateTime MATERIALIZED toStartOfHour(toDateTime(logTime / 1000)), -- 將logTime向小時取整`odinLeaf`StringDEFAULT'',`uri` LowCardinality(String) DEFAULT'',`traceid`StringDEFAULT'',`cspanid`StringDEFAULT'',`dltag`StringDEFAULT'',`spanid`StringDEFAULT'',`message`StringDEFAULT'',`otherColumn`Map<String,String>,`_sys_insert_time` DateTime MATERIALIZEDnow())ENGINE = MergeTreePARTITIONBY toYYYYMMDD(logTimeHour)ORDERBY (logTimeHour,odinLeaf,uri,traceid)TTL _sys_insert_time + toIntervalDay(7),_sys_insert_time + toIntervalDay(3) TO VOLUME 'hdfs'SETTINGS index_granularity = 8192,min_bytes_for_wide_part=31457280
分區鍵 :根據查詢特點,幾乎所有的 sql 都只會查1小時的數據,但這裏只能按天分區,小分時區導致 Part 過多及 HDFS 小檔過多的問題。
排序鍵 : 為了快速定位到某一個小時的數據,基於 logTime 向小時取整物化了一個新的欄位 logTimeHour,將 logTimeHour 作為第一排序鍵,這樣就能將數據範圍釘選在小時級別,由於大部份查詢都會指定上 odinLeaf、uri、traceid,依據基數從小到大分別將其 作 為第二、三、四排序鍵,這樣查詢某 個 traceid 的數據只需要讀取少量的索引塊,經過上述的設計所有的等值查詢都能達到毫秒級。
Map 列: 引入了 Map 型別,實作動態的 Scheme,將不需要用來過濾的列統統放入 Map 中,這樣能有效減少 Part 的檔數,避免 HDFS 上出現大量小檔。
Trace 表
Trace 表是用來提供 trace 相關的查詢,這類查詢對 QPS 要求很高,建立在 Trace 集群。數據來源於從 Log 表中提取的 trace 記錄。Trace 表只會有一張,所有的 Log 表都會將 trace 記錄提取到這張 Trace 表,實作的方式是 Log 表透過物化檢視觸發器跨集群將數據寫到 Trace 表中。
Trace 表的難點在於查詢速度快且 QPS 高,以下是 Trace 表的設計思路:
CREATETABLE ck_bamai_stream.trace_view(`traceid`String,`spanid`String,`clientHost`String,`logTimeHour` DateTime,`cspanid` AggregateFunction(groupUniqArray, String),`appName` SimpleAggregateFunction(any, String),`logTimeMin` SimpleAggregateFunction(min, Int64),`logTimeMax` SimpleAggregateFunction(max, Int64),`dltag` AggregateFunction(groupUniqArray, String),`uri` AggregateFunction(groupUniqArray, String),`errno` AggregateFunction(groupUniqArray, String),`odinLeaf` SimpleAggregateFunction(any, String),`extractLevel` SimpleAggregateFunction(any, String))ENGINE = AggregatingMergeTreePARTITIONBY toYYYYMMDD(logTimeHour)ORDERBY (logTimeHour, traceid, spanid, clientHost)TTL logTimeHour + toIntervalDay(7)SETTINGS index_granularity = 1024
AggregatingMergeTree : Trace 表采用了聚合表引擎,會按 traceid 進行聚合,能很大程度的聚合 trace 數據,壓縮比在5:1,能極大 地 提升 Trace 表的檢索速度。
分區鍵和排序鍵 :與 Log 的設計類似。
index_granularity :這個參數是用來控制稀疏索引的粒度,預設是8192,減小這個參數是為了減少數據塊中無效的數據掃描,加快 traceid 的檢索速度。
Trace 索引表
Trace 索引表的主要作用是加快 order_id、driver_id、driver_phone 等欄位查詢 traceid 的速度。為此,我們給需要加速的欄位建立了一個聚合物化檢視,以提高查詢速度。數據則是透過為 Log 表建立相應的物化檢視觸發器,將數據提取到 Trace 索引表中。
以下是建立 Trace 索引表的語句:
CREATETABLE orderid_traceid_index_view(`order_id`String,`traceid`String,`logTimeHour` DateTime)ENGINE = AggregatingMergeTreePARTITIONBY logTimeHourORDERBY (order_id, traceid)TTL logTimeHour + toIntervalDay(7)SETTINGS index_granularity = 1024
儲存設計的核心目標是提升查詢效能。接下來,我將介紹從 ES 遷移至 CK 過程中,在這一架構下所面臨的穩定性問題及其解決方法。
穩定性之路
支撐日誌場景對 CK 來說是非常大的挑戰,面臨龐大的寫入流量及超大集群規模,經過一年的建設,我們能夠穩定的支撐重點節假日的流量高峰,下面的篇幅主要是介紹了在支撐日誌場景過程中,遇到的一些問題。
大集群小表數據碎片化問題
在 Log 集群中,90%的 Log 表流量低於10MB/s。若將所有表的數據都寫入數百個節點,會導致大量小表數據碎片化問題。這不僅影響查詢效能,還會對整個集群效能產生負面影響,並為冷數據儲存到 HDFS 帶來大量小檔問題。
為解決大規模集群帶來的問題,我們根據表的流量大小動態分配寫入節點。每個表分配的寫入節點數量介於2到集群最大節點數之間,均勻分布在整個集群中。Flink 透過介面獲取表的寫入節點列表,並將數據寫入相應的 CK 節點,有效解決了大規模集群數據分散的問題。
寫入限流及寫入效能提升
在滴滴日誌場景中,晚高峰和節假日的流量往往會大幅增加。為避免高峰期流量過大導致集群崩潰,我們在 Flink 上實作了寫入限流功能。該功能可動態調整每張表寫入集群的流量大小。當流量超過集群上限時,我們可以迅速降低非關鍵表的寫入流量,減輕集群壓力,確保 重保表 的寫入和查詢不受影響。
同時為了提升把脈 的寫入效能, 我們基於 CK 原生 TCP 協定開發了 Native-connector。相比於 HTTP 協定,Native-connector 的網路開銷更小。此外,我們還自訂了數據型別的序列化機制,使其比之前的 Parquet 型別更高效。啟用 Native-connector 後,寫入延遲率從之前的20%降至5%,整體寫入效能提升了1.2倍。
HDFS 冷熱分離的效能問題
用 HDFS 來儲存冷數據,在使用的過程中出現以下問題:
服務重新開機變得特別慢且 Sys cpu 被打滿,原因是在服務重新開機的過程中需要並行的載入 HDFS 上 Part 的後設資料,而 libhdfs3 庫並行讀 HDFS 的效能非常差,每當讀到檔末尾都會丟擲異常打印堆疊,產生了大量的系統呼叫。
當寫入歷史分區的數據時,數據不會落盤,而是直接往 HDFS 上寫,寫入效能很差,並且直接寫到 HDFS 的數據還需要拉回本地 merge,進一步降低了 merge 的效能。
原生的 Part 路徑和 HDFS 的路徑是透過 uuid 來對映的,所有表的數據都是儲存在 HDFS 的同一路徑下,導致達到了 HDFS 目錄檔數 100w 的限制。
HDFS 上的 Part 檔路徑對映關系是儲存在原生的,如果出現節點故障,那麽檔路徑對映關系將會遺失,HDFS 上的數據遺失且無法被刪除。
為此我們對 HDFS 冷熱分離功能進行了比較大的改造來解決上面的問題,解決 libhdfs3 庫並行讀 HDFS 的問題並在本地緩存 HDFS 的 Part 後設資料檔,服務的啟動速度由原來的1小時到1分鐘。

同時禁止歷史數據直接寫 HDFS ,必須先寫本地,merge 之後再上傳到 HDFS ,最後對 HDFS 的儲存路徑進行改造。由原來數據只儲存在一個目錄下改為按 cluster/shard/database/table/ 進行劃分,並按表級別備份原生的路徑對映關系到 HDFS。這樣一來,當節點故障時,可以透過該備份恢復 HDFS 的數據。
收益
在日誌場景中,我們已經成功完成了從 ES 到 CK 的遷移。目前,CK 的日誌集群規模已超過400個物理節點,寫入峰值流量達到40+GB/s,每日查詢量約為1500萬次,支持的 QPS 峰值約為200。相較於 ES,CK 的機器成本降低了30%。
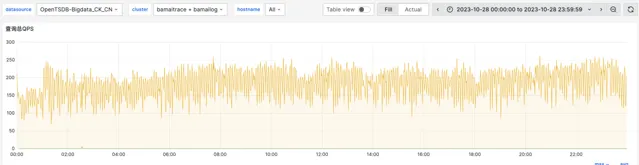
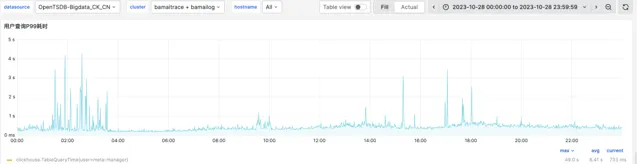
查詢速度相比 ES 提高了約4倍。下圖展示了 bamailog 集群和 bamaitrace 集群的 P99 查詢耗時情況,基本都在1秒以內。
總結
將日誌從 ES 遷移至 CK 不僅可以顯著降低儲存成本,還能提供更快的查詢體驗。經過一年多的建設和最佳化,系統的穩定性和效能都有了顯著提升。然而,在處理模糊查詢時,集群的資源消耗仍然較大。未來,我們將繼續探索二級索引、zstd 壓縮以及存算分離等技術手段,以進一步提升日誌檢索效能。











