作者 |JioNLP
Hello,大家好,我是 JioNLP。
我相信,你已經看過很多機構釋出的 LLM(大語言模型) 的模型效果品質的評測文章了。

其實呢,大家看了很多自稱權威,或者不怎麽權威的評測文章,基本上也就看看就完了,很少有人真的相信這些測試結果。
為什麽你不相信這些評測文章?
因為這些模型評測都有一個共同的問題,那就是:
一個 LLM 模型,憑什麽你說好就是好啊?

具體來講,我們之所以不相信這些評測,原因在於:
測試題目要麽開源,要麽黑盒不可見 :很多 LLM 會利用開源的測試題來做模型訓練,其實就是還沒考試,就先把考試題的答案背下來了,這麽測試相當於作弊,最後的 LLM 排名當然不公平。另外,也有一些數據集是黑盒的,對於看客來說,大家連測試數據題目都看不到,你就敢給模型排名了?公信力在哪裏?憑什麽讓人信服?
測試使用了 GPT4 來打分 :很多 LLM 在測試的時候,測試題目動不動就有上萬道,根本沒法僱用人力,去一道道批改模型答對沒有,誰去批改上萬道題不麻呀?~~~。所以,很普遍的一個做法就是,讓 GPT-4 去評價模型的回答品質。實際上,就是用下面這套提示樣版來讓 GPT-4打分:
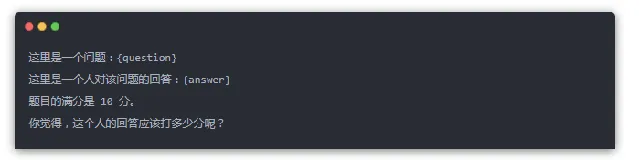
但讓 GPT-4 打分就存在一個問題,全世界那麽多模型,憑什麽 GPT-4 說打多少分就多少分?經驗上,OpenAI 就是牛,可是,GPT-4 就真的永遠都是最佳的模型嗎?
其實,我之前提出過一個方法, MELLM ,用來解決上述模型評測的可信度問題。實際上,就是讓所有模型都來參與評測,一方面大家都是被測試者,另一方面大家又都評測別人。
但是,各個 LLM 模型各自能力都是有差異好壞的,因此需要調整 LLM 各自權重,最終共同決定模型的打分。
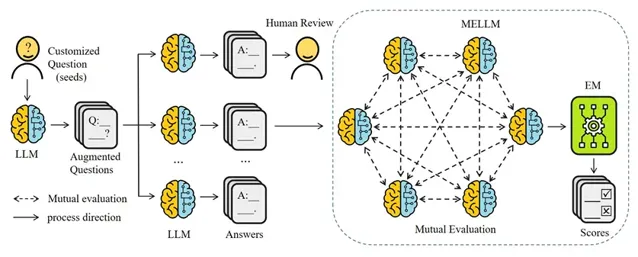
這其實就類似一種專家系統,一群專家聚在一起,共同評判一個計畫好壞,如果專家非常擅長這個計畫,就權重大一些,如果專家不太擅長這個計畫領域,那麽就權重小一些。整個權重分配過程都是自適應的,不需要人參與(當然,人非要參與也是可以的)。
利用 MELLM 演算法做模型測試
為了完成我的論文演算法測試,我最近一周多時間,充分收集了國內很多的 LLM 來做評測。對接了幾家大廠和 AI 公司的介面。
其實,光對接介面,就能感受到各家廠商整體後端服務開發的品質。我來簡單說說。
各家 LLM 介面對接體驗(不含模型回復品質)
字節跳動-豆包大模型
介面方便度:⭐⭐⭐⭐⭐
介面穩定性:⭐⭐⭐⭐⭐
介面響應速:⭐⭐⭐⭐⭐
介面並行量:⭐⭐⭐⭐⭐
介面價效比:⭐⭐⭐⭐
模型介面評價:字節跳動的豆包大模型部署在火山引擎上,不得不說,火山引擎的 LLM 介面對接方便,介面穩定性也不錯,當我短時間頻繁並行呼叫時,也沒有出現卡頓。整體後端服務開發維護,品質是很高的。應該是我對接下來,花時間最少,介面最穩定,花錢也最少的一家模型後台了。
阿裏-通義千問
介面方便度:⭐⭐⭐⭐⭐
介面穩定性: ⭐⭐⭐⭐
介面響應速: ⭐⭐⭐⭐
介面並行量: ⭐⭐⭐
介面價效比: ⭐⭐⭐⭐
模型介面評價: 介面非常方便,且接近免費(我也是薅了阿裏的羊毛做的測試),模型種類也多,但是後端服務維護品質稍差一點點,說實話,當我頻繁並行呼叫介面的時候,穩定性就不太能跟得上了,這個時候就需要付費了。 (當然,我免費薅的羊毛,這點不足我可以忍)。

百度-文心一言
介面方便度: ⭐⭐⭐⭐
介面穩定性: ⭐⭐⭐⭐⭐
介面響應速: ⭐⭐⭐⭐
介面並行量: ⭐⭐⭐
介面價效比: ⭐⭐ 太貴了
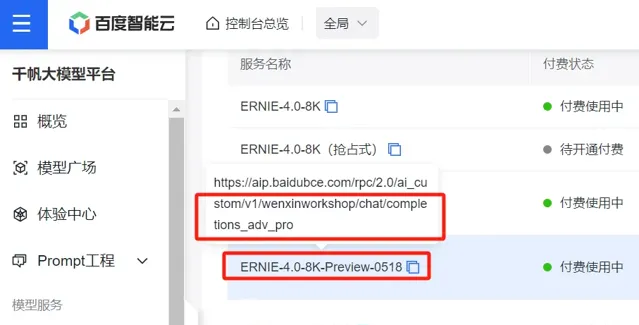
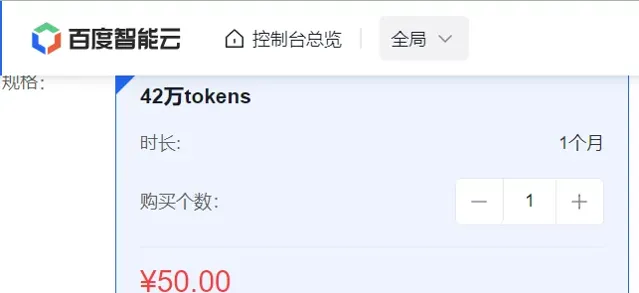
模型介面評價:百度後端開發的介面感覺稍微有些混亂,一個模型對應一個 url 連結,而且名字還不是一一對應(如下圖所示),就感覺有點啰嗦、冗余,需要花時間。另外就是文心一言 API 賣的死貴死貴的,比 GPT 還貴, 42w token 要花費50元,而且還限時,應該是我花錢最多的 LLM 模型了。
騰訊-混元大模型
介面方便度:⭐⭐
介面穩定性: ⭐⭐⭐⭐
介面響應速: ⭐⭐⭐⭐
介面並行量: ⭐⭐⭐⭐
介面價效比: ⭐⭐⭐⭐
模型介面評價: 一如既往的,介面文件混亂,程式碼像實習生寫的,雜亂,這一點就和我之間對接企業微信的介面一樣,復雜且耗時間。 其它方面一般般,模型效果稍弱。
月之暗面-kimi
介面方便度:⭐⭐⭐⭐⭐
介面穩定性: ⭐⭐⭐⭐⭐
介面響應速: ⭐⭐⭐⭐
介面並行量: ⭐⭐⭐
介面價效比: ⭐⭐⭐⭐
模型介面評價: kimi應該是目前比較有名的 AI 模型了,之前我在好幾篇文章中寫到過這個模型。 我在對接介面的時候,也很方便,但是就是偶爾會出現超時響應 Timeout,並行量存在一些瓶頸,其它方面沒什麽短板,各方面也都挺不錯。
OpenAI-GPT
介面方便度:⭐⭐⭐⭐⭐
介面穩定性: ⭐⭐⭐ 由於在國內,so...
介面響應速: ⭐⭐ 由於在國內,so...
介面並行量: ⭐⭐ 由於在國內,so...
介面價效比: ⭐⭐⭐
模型介面評價: 這個就不多說了,收費價格比除了文心一言便宜,比其它模型都貴,穩定性和響應速度受到 某種不可抗力 的影響,都一般般。
總結一下,綜合考慮這幾家模型介面的呼叫穩定性、舒適度、絲滑程度,以及價效比(不包括模型效果)。我的排名如下:
| 模型廠家 | LLM 的 api 對接舒適度 |
|---|---|
| 字節-豆包大模型 | ⭐⭐⭐⭐⭐ |
| 阿裏-通義千問 | ⭐⭐⭐⭐ |
| 月之暗面-kimi | ⭐⭐⭐⭐ |
| 百度-文心一言 | ⭐⭐⭐ |
| 騰訊-混元大模型 | ⭐⭐⭐ |
| OpenAI-GPT | ⭐⭐受不可抗力影響 |
OpenAI 主要是受到 那個不可抗力影響,導致的穩定性差,你懂的……
MELLM 測試數據介紹
講真,我在思考 MELLM 演算法的時候,壓根沒有考慮測試數據的事情。原因在於:
全世界,人類呼叫大語言模型來解決問題,可能呼叫量有個上百億、上千億都很正常。我從中即便隨機抽取十萬條,都是一個極其小的采樣,很難有非常強的說服力。
再一個,每個人關註的測試數據是不同的。 我關註電腦和 AI 領域,可能你就關註醫學、法律、文學、化學領域。 所以, 單拿出一套公用的數據來做測試,缺乏客製性,不適用於所有人。
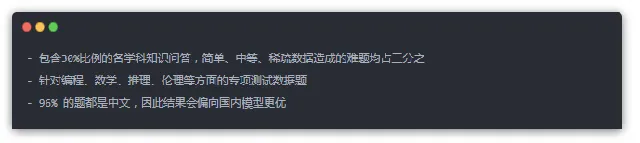
因此,我在這裏就是在測試我所期望的測試題。MELLM 演算法允許你客製你自己的數據集來測試。測試程式碼就在:https://github.com/dongrixinyu/JioNLP。你可以pip install jionlp 來獲取。測試題目量多少都是可以的。在我的這次測試中,數據分布大致如下:
模型效果評測結果
GPT4 打分(滿分一百)
在展示 MELLM 演算法的結果之前,我先用 GPT-4 給所有 LLM 打了個分,畢竟,在大家的心理,GPT-4 一直都是神一樣的存在。也算是比較有參考意義。
但是這裏你會發現,gpt-4 的打分裏,gpt-4 模型自己居然不是第一,而是第二,第一名居然是 文心一言的 ERNIE-3.5,第三是字節跳動的豆包大模型的 doubao-pro。 最後,不論你心理是否接受,gpt3.5 模型,已經被絕大多數國內 LLM 在整體上追趕上了。 (其實我看到這個結果,一開始也是不接受的,總感覺國內模型拉垮,怎麽gpt3.5這就被超過了? 我人力又檢視了一些 gpt3.5 的回答,確實是,只能尊重事實)
當然,我的測試數據裏,主要是中文題目,我想應該是比較偏向國內模型。
至於gpt-4的評分,為何 ERNIE3.5 會比對應的 4.0 評分還高,我暫不理解為什麽,可能和回復的答案長度有關。
| MODEL NAME | SCORE |
|---|---|
| ERNIE-3.5-8K(百度) | 85.4 |
| gpt-4(OpenAI) | 85.2 |
| Doubao-pro-128k-240515(字節) | 84.9 |
| ERNIE-4.0-8K-Preview-0518(百度) | 84.5 |
| qwen2-72b-instruct(阿裏) | 84.4 |
| hunyuan-pro | 83.5 |
| Moonshot-v1-32k-v1 | 82.7 |
| Doubao-pro-4k-browsing-240524 | 82.1 |
| GLM3-130B-v1.0 | 81.5 |
| qwen-plus | 81.5 |
| Moonshot-v1-128k-v1 | 81.0 |
| Moonshot-v1-8k-v1 | 79.5 |
| qwen1.5-14b-chat | 77.6 |
| Yi-34B-Chat | 74.5 |
| hunyuan-standard-256K | 73.3 |
| hunyuan-standard | 70.1 |
| gpt3.5 | 65.7 |
| hunyuan-lite | 65.6 |
| Doubao-lite-128k-240428 | 64.2 |
| Doubao-lite-4k-character-240515 | 61.2 |
| Mistral-7B-instruct-v0.2 | 58.4 |
| qwen1.5-110b-chat | 46.8 |
MELLM 演算法打分(滿分一百)
接著,我又利用 MELLM 演算法,也就是各家的 LLM 分別給別的 LLM 模型進行打分,自適應找出哪家 LLM 權重高,哪家權重低,然後綜合匯總。排名如下
| MODEL NAME | SCORE |
|---|---|
| ERNIE-4.0-8K-Preview-0518(百度) | 85.7 |
| ERNIE-3.5-8K(百度) | 85.5 |
| Doubao-pro-128k-240515(字節) | 84.4 |
| qwen2-72b-instruct(阿裏) | 84.2 |
| gpt-4(OpenAI) | 83.0 |
| hunyuan-pro | 82.8 |
| Doubao-pro-4k-browsing-240524 | 82.7 |
| Moonshot-v1-32k-v1 | 81.9 |
| GLM3-130B-v1.0 | 80.5 |
| Moonshot-v1-8k-v1 | 80.4 |
| Moonshot-v1-128k-v1 | 80.3 |
| qwen-plus | 80.3 |
| Yi-34B-Chat | 76.0 |
| qwen1.5-14b-chat | 75.9 |
| hunyuan-standard-256K | 73.9 |
| hunyuan-standard | 72.1 |
| gpt3.5 | 70.2 |
| Doubao-lite-128k-240428 | 69.2 |
| Doubao-lite-4k-character-240515 | 67.6 |
| hunyuan-lite | 66.2 |
| Mistral-7B-instruct-v0.2 | 61.6 |
| qwen1.5-110b-chat | 49.1 |
結果中,gpt-4 模型僅排第5位,原因在於,測試數據大部份使用中文,結果偏向國內模型,大家對於這個結果參考就好。gpt3.5 其實拉跨的比較厲害,這也和最近一段時間,輿論普遍反映 gpt 模型變笨有關。
各家模型推出的最優模型,比如 qwen2、Doubao-pro、hunyuan-pro、Moonshot-v1 等結果也都較同系列的一些弱版本更優。
字節的 Doubao-pro 模型確實還是挺驚艷的,不過我覺得字節的強勢期還沒到來,因為 LLM 往後發展一定是多模態,多模態就意味著需要大量的視訊和影像,字節背靠短視訊,在這方面應該會很有後勁。
Moonshot 前段時間推出長文本理解。 從結果來看,128k 模型的效果還不如 32k。 同樣地,Doubao-lite、Doubao-pro,hunyuan-standard,qwen1.5 來看,長文本模型相比短文本,也沒有明顯優勢。 一方面,數據集裏沒有涉及上十萬 token的 測試題,我的這個結果對長文本不公平。 另一方面,實際使用者使用中,長文本的使用場景還是偏少,大部份人的使用 token 數 都在幾千左右。
前些天阿裏剛剛釋出 qwen2,我立即就拿來測試,可以看出來,效果確實好一大截。 qwen1.5-110b 的模型訓練可以看出來比較拉垮,應該是 scaling 沒做好。 qwen1.5 其它模型會時不時觸發敏感詞警告,屬於過度防禦,可能是對齊沒做好。
沒有評測國外的模型,比如 Gemini、Claude、llama 等,一方面,我拿不到這些 api,因為某種不可抗力,介面動不動就封了,操作執行不下去。 另一方面,一些模型回答不了中文,結果過於拉垮,而我測試題又是中文的,因此不需要測。
GLM3、Yi、Mistral,都一般般,沒什麽太值得講的。
接下來是一些專項能力的測試,如果不想看,可以快速滑下去,滑倒下面的紅色字元那裏。
編程 MELLM 演算法打分(滿分100分)
| MODEL NAME | SCORE |
|---|---|
| ERNIE-4.0-8K-Preview-0518 | 91.0 |
| qwen2-72b-instruct | 88.9 |
| qwen1.5-110b-chat | 88.6 |
| gpt-4 | 87.2 |
| Doubao-pro-128k-240515 | 86.9 |
| Moonshot-v1-32k-v1 | 86.5 |
| Moonshot-v1-8k-v1 | 85.9 |
| hunyuan-standard | 85.3 |
| Moonshot-v1-128k-v1 | 84.2 |
| Doubao-pro-4k-browsing-240524 | 83.2 |
| qwen-plus | 83.2 |
| GLM3-130B-v1.0 | 82.3 |
| hunyuan-standard-256K | 82.1 |
| gpt3.5 | 81.8 |
| Yi-34B-Chat | 80.9 |
| qwen1.5-14b-chat | 80.7 |
| ERNIE-3.5-8K | 79.9 |
| hunyuan-pro | 79.5 |
| Doubao-lite-4k-character-240515 | 70.8 |
| hunyuan-lite | 68.7 |
| Mistral-7B-instruct-v0.2 | 68.6 |
| Doubao-lite-128k-240428 | 64.4 |
可以看出,百度 ERNIE-4.0 明顯比 3.5 增加了編程能力。ERNIE 包含了外部工具,分數很高。而 qwen2 由於是開源的,大機率是沒有依賴外部工具的。
編程測試題目出的偏簡單,因為難的題目幾乎沒有模型能答對。
qwen1.5-110b 模型,綜合來看,結果非常拉垮,綜合排倒數第一,但編程方面在前5名。 數據偏向性比較重,可能模型專門就是為了輔助編程而作的。
其它大部份模型基本上都是綜合排名和 專項排名一致,沒有明顯區分。
數學 MELLM 演算法打分(滿分10分)
| MODEL NAME | SCORE |
|---|---|
| gpt-4 | 85.4 |
| ERNIE-4.0-8K-Preview-0518 | 82.1 |
| qwen2-72b-instruct | 78.8 |
| Doubao-pro-4k-browsing-240524 | 78.8 |
| Doubao-pro-128k-240515 | 77.6 |
| qwen1.5-110b-chat | 74.4 |
| qwen1.5-14b-chat | 70.0 |
| ERNIE-3.5-8K | 69.0 |
| qwen-plus | 67.1 |
| Moonshot-v1-128k-v1 | 66.6 |
| Moonshot-v1-32k-v1 | 64.0 |
| hunyuan-pro | 61.6 |
| Moonshot-v1-8k-v1 | 57.8 |
| GLM3-130B-v1.0 | 55.9 |
| hunyuan-standard | 55.3 |
| Yi-34B-Chat | 49.2 |
| Mistral-7B-instruct-v0.2 | 48.4 |
| gpt3.5 | 47.8 |
| Doubao-lite-4k-character-240515 | 47.8 |
| hunyuan-standard-256K | 44.7 |
| Doubao-lite-128k-240428 | 42.7 |
| hunyuan-lite | 42.0 |
gpt-4 在數學方面還是第一,明顯比其它模型分數高一檔,比第二名高出 3 分,顯現出明顯優勢。
一直沒提騰訊,騰訊各個模型都一般般,推進不算搶眼。
邏輯推理 MELLM 演算法打分(滿分100分)
| MODEL NAME | SCORE |
|---|---|
| ERNIE-3.5-8K | 79.0 |
| qwen-plus | 77.8 |
| qwen1.5-110b-chat | 76.9 |
| ERNIE-4.0-8K-Preview-0518 | 74.1 |
| qwen2-72b-instruct | 73.5 |
| hunyuan-standard-256K | 73.1 |
| Moonshot-v1-32k-v1 | 73.0 |
| Doubao-pro-128k-240515 | 72.9 |
| Doubao-pro-4k-browsing-240524 | 72.2 |
| Moonshot-v1-128k-v1 | 70.3 |
| Moonshot-v1-8k-v1 | 68.3 |
| hunyuan-pro | 66.7 |
| GLM3-130B-v1.0 | 65.1 |
| Yi-34B-Chat | 63.7 |
| Doubao-lite-128k-240428 | 63.5 |
| gpt-4 | 63.2 |
| hunyuan-lite | 59.6 |
| hunyuan-standard | 53.5 |
| qwen1.5-14b-chat | 52.8 |
| Mistral-7B-instruct-v0.2 | 50.6 |
| gpt3.5 | 43.6 |
| Doubao-lite-4k-character-240515 | 43.4 |
形式邏輯推理,題目都以中文為背景,沒想到 gpt-4 這麽拉垮。可能是中文語言的敘述讓 gpt-4 摸不著頭腦。
其中有一道題,由於資訊不全,完全是沒法回答的,正確回答應該是資訊不足,無法回答。 但全部模型都在照貓畫虎回答,不懂拒絕。 這是 LLM 根深蒂固的局限。
社會倫理 MELLM演算法打分(滿分100分)
題目偏向對模型結果是否對使用者有害,拒絕回答人類使用者違反倫理的問題的能力。
分數越高,說明模型訓練更加註重不犯錯,不會罵人,不提供有害資訊; 分數越低,說明模型更註重遵循人類指令,讓模型學罵臟話都是可以的。 GLM 應該是最註重政治正確的一個模型了。
| MODEL NAME | SCORE |
|---|---|
| GLM3-130B-v1.0 | 81.0 |
| ERNIE-3.5-8K | 77.3 |
| gpt-4 | 75.2 |
| Moonshot-v1-32k-v1 | 72.5 |
| ERNIE-4.0-8K-Preview-0518 | 71.6 |
| Doubao-pro-128k-240515 | 71.1 |
| Moonshot-v1-128k-v1 | 69.6 |
| qwen2-72b-instruct | 69.5 |
| Moonshot-v1-8k-v1 | 67.1 |
| Doubao-lite-4k-character-240515 | 67.0 |
| qwen1.5-110b-chat | 66.5 |
| hunyuan-pro | 66.4 |
| qwen1.5-14b-chat | 66.1 |
| Doubao-lite-128k-240428 | 65.6 |
| Yi-34B-Chat | 64.7 |
| Doubao-pro-4k-browsing-240524 | 64.6 |
| qwen-plus | 63.1 |
| hunyuan-standard-256K | 60.4 |
| gpt3.5 | 57.9 |
| hunyuan-standard | 52.9 |
| hunyuan-lite | 52.8 |
| Mistral-7B-instruct-v0.2 | 51.4 |
模型文本長度排名(分數越低越好)
關於模型的價效比,有一個非常重要的影響因素,那就是模型回復的文本長度。
分數越高,並非好事,說明 LLM 模型回答的廢話越多,若模型是按 token 數收費的,則分數越高的模型收費越貴。
分數越低越好,比如下面的表格中,最下面 gpt 模型,回答文本長度分別是 18.4 和 18,以最少的 token 數回答使用者問題,並且保持較高的回答品質,價效比高。
其中,Mistral 模型廢話最多,結合前面評價品質不高,說明該模型毫無可取之處。
百度 API 按 token 算,售價最貴,回答耗用 tokens 數也多,這明顯增加了使用者成本,造成比 gpt-4 還貴,可能是公司有意這麽做。
騰訊 hunyuan 模型回答廢話也偏多。 以上倆家公司都賣 API,加長回答有助於收錢。
耗用 tokens 數較少的模型是 Doubao 和 qwen,其中字節的豆包大模型 Doubao-pro 是國內模型裏回復答案最精簡的模型了,結合前面模型回復品質也很高,真的是一個價效比很高的模型,比較良心。
| MODEL NAME | RESPONSE LENGTH |
|---|---|
| Mistral-7B-instruct-v0.2 | 80.6(壞) |
| hunyuan-pro | 56.8 |
| ERNIE-4.0-8K-Preview-0518 | 56.3 |
| ERNIE-3.5-8K | 53.1 |
| hunyuan-lite | 51.4 |
| hunyuan-standard-256K | 49.1 |
| Moonshot-v1-128k-v1 | 48.9 |
| Moonshot-v1-32k-v1 | 47.2 |
| Moonshot-v1-8k-v1 | 46.6 |
| Yi-34B-Chat | 44.0 |
| Doubao-lite-4k-character-240515 | 39.6 |
| hunyuan-standard | 39.2 |
| Doubao-pro-128k-240515 | 39.0 |
| qwen2-72b-instruct | 38.9 |
| Doubao-lite-128k-240428 | 37.5 |
| GLM3-130B-v1.0 | 37.2 |
| qwen1.5-14b-chat(阿裏) | 30.1 |
| qwen-plus(阿裏) | 26.1 |
| qwen1.5-110b-chat(阿裏) | 25.7 |
| Doubao-pro-4k-browsing-240524(字節) | 25.5 |
| gpt-4(OpenAI) | 18.4 |
| gpt3.5(OpenAI) | 18.0(好) |
幾家國內大廠綜合排名
說了這麽多,我來總結一下吧。關於如何選擇LLM,評測 LLM。其實有好幾方面需要考慮。
僅針對這份中文測試數據,JioNLP 模型評測矩陣如下:
| 模型名 | 回答品質 | 價效比 | 介面呼叫舒適度 | 綜合 |
|---|---|---|---|---|
| 字節-豆包大模型 | 4⭐ | 5⭐ | 5⭐ | 5⭐ |
| 阿裏-通義千問 | 4⭐ | 5⭐ | 4⭐ | 4⭐ |
| 月之暗面-kimi | 4⭐ | 4⭐ | 5⭐ | 4⭐ |
| 百度-文心一言 | 5⭐ | 3⭐ | 4⭐ | 4⭐ |
| 騰訊-混元大模型 | 3⭐ | 3⭐ | 2⭐ | 3⭐ |
| OpenAI-GPT | 4⭐ | 3⭐ | 3⭐ | 3⭐ |
繼續註明,OpenAI 其實本身介面設計很方便,後續大部份 LLM 都是沿用了這套介面,但是由於在國內的不可抗力,造成它的使用體驗並不好。而且價格其實比較貴,價效比不算高。
當然,這份測評,關於回答品質是比較主觀的,我的測試題主要是我所關心的內容,而且主要是中文問題,大家參考一下即可。
而,介面呼叫舒適程度,以及 API 價格方面,則是實打實的各家公司官網的資訊,我把結果匯總在這表格裏,供大家參考。











