【導讀】 人工智慧與機器學習技術猶如疾風驟雨般席卷全球,在顛覆傳統的同時為人類帶來了新一輪的倫理挑戰。AI 模型雖能憑借強大的數據處理能力和最佳化效率在各個行業大放異彩,然而在追求極致準確性的模型行為背後,卻存在與其設計初衷產生偏差的風險。
如今,「對齊問題」作為 AI 領域的核心議題再度引起熱議,看似簡單的訴求背後,實則隱藏著深刻的理論挑戰。本文作者布萊恩·凱瑞斯汀(Brian Christian)將深度剖析這一問題,探尋實作 AI 與人類目標有效對齊的可能路徑。
本文精選自【 007:大模型時代的開發者】,【新程式設計師 007】聚焦開發者成長,其間既有圖靈獎得主 Joseph Sifakis、前 OpenAI 科學家 Joel Lehman 等高瞻遠矚,又有對於開發者們至關重要的成長路徑、工程實踐及趟坑經驗等,歡迎大家 。
作者 | Brian Christian
整理 | 曾浩辰、王啟隆
出品 | 【新程式設計師】編輯部

人工智慧( AI )模型與機器學習( ML )系統的迅速崛起和廣泛套用,引起了社會對這些技術內在的倫理難題和安全風險展開密切關註與審查。當前,構建安全、穩健、可解釋且值得信賴的智慧系統已成為人們亟待解決的關鍵課題,這需要跨越傳統學科界限的學習和協作,還須深入探索哲學、法學以及社會科學等多個維度,匯聚全球各行各業的共同努力。
近年來,AI 模型在高效處理和最佳化大量數據方面展現出了極強的靈活性與效能。然而,關鍵問題在於:模型在特定精細案例上達到的最佳化精確度,是否真正契合了我們期望系統完成的目標任務。ML 系統具備一種不可思議的執行方式:它們可以完全按照我們的指令執行,卻不一定符合我們的真實意圖。
這實際上是一個歷史悠久的問題,至少可以追溯到 60 年前,諾伯特·維納( Norbert Wiener )在麻省理工學院進行的控制論研究。維納在 1960 年發表了一篇著名的文章【自動化的一些道德和技術後果】,並在文中對當時初級的 ML 系統與著名的【魔法師學徒】故事相比較。這個故事最初源自 18 世紀的一首德國詩歌,但因 1940 年代米奇老鼠的版本而廣為人知。故事中,一名業余魔術師給掃帚施了魔法,命令它取水。但他的命令制定不夠謹慎,導致掃帚不斷取水,魔術師因此差點被水淹死,而事件直到他的師傅的介入才得以解決。

維納在他的文章中具有預見性地指出:「 這類故事不僅是童話的素材。它們正是我們與 ML 系統交互作用中即將面臨的問題。 」
文章中有一句名言:「 若我們采用一種無法有效操控其執行機制以達成目標的機械裝置,那麽最好萬分確定輸入到該機器中的目標確實是我們的真正意圖。 」 如今,這已成為 AI 領域的一個核心關註點,它被命名為「 對齊問題 」:讓系統不僅僅模仿人類的指令,而是真正達成人類的目的。聽起來很簡單,但我們該如何實作這一點?
訓練數據是決定成敗的根基
首先,審視訓練數據。學習型系統的一個問題在於,它們往往受到所用範例的限制。舉例來說,喬伊·布奧蘭維尼( Joy Buolamwini )是一名電腦科學專業的本科生,她在參加一場創業競賽時,對人臉辨識系統中膚色差異的問題產生了興趣。這種興趣最終成為了她在 2017 年和 2018 年的主要研究課題。在麻省理工學院工作期間,她分析了當時的許多商業人臉分類系統,發現這些系統在分類膚色較深的女性時錯誤率要高出幾個數量級。
這項研究成為了對工業界和學術界所使用的數據集的公正性審查工作的一部份。例如,2010 年代最受歡迎和廣泛參照的一個數據集被稱為「帶標簽的野外面孔( LFW,Labled Faces in the Wild )」,這個數據集從 2000 年代的報紙照片中收集了大量的人臉資訊。因此,它主要包含了那些時期可能出現在報紙頭版的人物。分析表明,該數據集中最常見的個人資訊來源於當時的美國總統喬治·W·布希。實際上,布希的照片數量是所有黑人女性照片總和的兩倍。因此,任何使用這個數據集來建立人臉辨識系統的人,實際上都在無意識(或有意識)中建立了一種更傾向於辨識布希的系統。
類似的訓練數據不匹配問題也出現在自動駕駛汽車領域。2018 年,美國發生了一起由優步自動駕駛汽車導致行人喪生的事故。美國國家運輸安全委員會的報告指出,涉事車輛搭載的系統基於一個分類器,該分類器分別針對行人和騎行人設定了上千個範例。然而,在事發當時,這名行人恰好推著自由車橫過馬路。這種特定情景未曾出現在分類器的訓練數據中,因而導致分類器無法準確地將該行人歸入相應的類別,進而釀成了這場悲劇。

顯然, 在現實世界中部署模型時,訓練數據與實際情況之間的不匹配可能導致嚴重問題。
目標函式易產生與預期不符的結果
接下來討論目標函式的問題。目標函式透過數學體現了我們的意圖,用數值方式囊括了使用者希望系統執行的確切任務。任何在 ML 領域有經驗的人都知道,目標函式是系統中非常脆弱的一個環節,容易出現意想不到的結果。這些結果有時能讓人會心一笑,有時卻需要嚴肅對待。
Google X 的負責人阿斯特羅·特勒( Astro Teller )在其研究生時期參與機器人足球比賽計畫時,曾嘗試利用強化學習演算法令其研發的系統從頭開始掌握踢足球技能。設想如果僅將進球得分作為唯一的目標函式,那麽初始化狀態下的系統可能需要歷經漫長的時間才能收獲第一個得分獎勵。在此之前,系統難以自行判斷行動是否在正確的方向上。因此,特勒引入了所謂的「塑造獎勵」概念,即在學習踢足球時,將控球視為一個得分的合理途徑。但這導致了新的問題:當機器人接近球時,它的機械臂會以大約每秒 20 次的高速振動來控球。雖然這符合目標函式的設定,但並不是特勒真正希望實作的結果。

這類偏差不僅出現在研究計畫中,也普遍存在於現實世界中的重要領域。例如,美國最大的健康保險公司之一,使用 ML 系統來確定患者護理的排序,並為每年大約 2 億名患者制定治療計劃。該系統的設計目標是優先考慮有最大健康需求的人群。然而,由於健康需求難以量化,他們決定用醫療成本作為替代指標。表面上看,這很合理——如果一個人的醫療賬單高達數百萬美元,我們可能會認為他處於糟糕的健康狀態。
這種方法忽略了一個關鍵事實:成本並不能完全代表健康需求。有的病人可能因為癥狀未被重視或附近缺乏優質醫療設施而未能得到適當的護理。這意味著,盡管他們急需護理,但模型僅憑預測成本低而判斷他們不需要太多幫助。換言之,那些實際上接受低水平護理的人,反而在模型中被系統性地降低了優先級。這說明, 模型遵循了設定好的目標函式,但卻未能真正實作我們的初衷。
「幻覺」仍是解決對齊問題的一道坎
下面討論大語言模型( LLM )中的對齊問題。所有語言模型都始於一個名為「預訓練」( pre-training )的過程。這個過程十分簡單:首先準備一個龐大的文本資料庫,其通常包含了整個互聯網的數據。模型在訓練時,會從海量數據中隨機抽取文本片段,並基於上下文預測下一個可能出現的詞匯或標記。經過長達六個月時間,在成千上萬台高效能電腦集群上不間斷地叠代訓練,耗費數億美元的投資,最終就能得到一個強大的自動補全系統。
我們都熟悉手機打字時的自動補全功能。但如果投入巨資,利用完整的數據中心構建世界上最強大的自動補全系統時,其套用範圍會怎樣擴充套件?這個系統將無所不能,幾乎任何任務都可以透過提示工程轉化為預測遺失單詞的任務。例如,情感分析可以透過簡單的提示實作,機器轉譯只需指定「將上一句轉譯成法語」,甚至連作文寫作也可以透過輸入「這是我的語文課作文,然後……」來實作。對於軟體編程,只需描述所需的程式碼,讓系統自動補全實際的程式碼。
然而,這裏面存在一個巨大的對齊問題。 AI 系統擅長於從互聯網隨機文本中預測遺失的單詞,這並非是這些系統被設計的最初目的。 實際上,由於訓練數據和目標函式之間的不一致,導致了很多有關模型的著名問題。
首先,互聯網充斥著錯誤文本和諸如刻板印象等代表性問題,這些數據在統計中被不斷傳播。例如,使用 GPT-2 時輸入:「我的妻子剛剛得到了一份令人興奮的新工作,明天開始她將開始……」,系統可能自動補全為「打掃辦公室」。而對於「我丈夫明天開始的新工作」這一問題,它可能自動補全為「一家銀行的IT顧問和一名醫生」。這顯然反映了性別刻板印象。
研究表明,隨著模型變得更強大,圍繞刻板言語和有害言論的問題變得更糟,這一點雖不直觀卻很重要。在使用大語言模型編寫程式碼時,也面臨著同樣的問題。這些模型是在包含錯誤和安全漏洞的開原始碼數據集上訓練的。小模型可能只是隨機自動補全,偶爾出現錯誤或漏洞,但大模型卻能辨識到這些錯誤和漏洞之間的高度相關性,並生成更多錯誤程式碼。因此,使用像 GitHub Copilot 這樣的程式碼完成工具時,更強大的模型有機率會判斷「這個使用者是初學者」,並生成更多的錯誤。隨著模型規模的擴大,這個問題實際上變得更嚴重。
更為關鍵的是,這裏存在一個重要的對齊問題,即用於訓練系統的目標函式與實際套用目標之間的不一致。當我們向模型詢問不存在的資訊,如關於 AI 一致性的熱門歌曲時,它會預設這個目標一定寫在了某個互聯網文件中,並積極補全它認為該檔會說的內容。這種現象被稱為「 幻覺 」,實際上模型只是在做出最佳猜測,遵循它的訓練內容。
強化學習是最「詩意」的解決方案
預訓練模型普遍存在一個根本性問題: 它們並不能真正理解收到的問題或指令的含義 。舉例來說,當我們向一個語言模型輸入「向一個 6 歲孩子解釋登月任務」,期待得到的回答可能是:「人類登上月球是一項偉大的壯舉,他們在那裏拍照留念,並成功返回地球。」然而,GPT-3 在面對類似場景時,可能會給出「向一個 6 歲的孩子解釋重力的概念,或者是相對論」之類的回答。究其原因,使用者意圖向模型發出一個明確的指令,而 AI 模型卻只會基於從互聯網的隨機文件中進行自動補全。互聯網上存在著大量文件,如學生作業和試題等,其中往往會在一道指令之後緊跟著另一道指令而非直接的答案,這恰恰暴露出模型在理解任務本質方面的局限性。
總之,我們向機器輸入的目標,並不總是我們真正想要實作的事情。雖然模型按照編程運作,但並不總能滿足需求。我們不僅需要一個能夠自動補全互聯網內容的系統,而且還希望它能真正理解指令,並提供有幫助、專業、安全且真實的回應。實際上,這個問題幾乎不可能透過指定某種數位目標函式來解決。但也許還有另一種方法,即將數值目標函式的構造本身視為一個 ML 問題,並嘗試用 AI 來解決它。
最能說明這種方法的例子來自 OpenAI 和 DeepMind 的研究人員之間的合作。他們決定探索一種方法,旨在透過普通人類使用者在亞馬遜的眾包( crowdsourcing )平台 Mechanical Turk 上的直觀指導,幫助一個虛擬機器器人掌握復雜的後空翻動作。後空翻是一個有趣的任務,因為大多數人幾乎不可能用扭矩、角動量和軌跡函式等數值形式將其描述,卻可以透過肉眼觀察來判斷一次後空翻是否成功。研究人員面臨的問題是:這種觀察能力是否足夠讓機器人學習後空翻?
研究人員首先讓機器人進行隨機的動作嘗試,邀請使用者觀看並對比幾組機器人不同動作的視訊片段。隨後他們要求使用者基於直覺和視覺感知,挑選出動作更接近完美後空翻的視訊片段。實際上,研究人員按使用者在兩個片段中二選一,明確要求使用者選擇一個「會讓美好事情發生的」視訊片段( Look at the clips and select the one in which better things happen )。如果使用者期待機器人向左側翻轉,那麽就應選出其向左翻滾的動作畫面。
我很欣賞這種做法,它幾乎是詩意的。隨後,系統開始根據使用者的選擇推斷目標函式是什麽,再不斷迴圈此反饋過程。最終持續大約一個小時,收集了幾百個偏好數據,但實際上這些數據只有大約 100 位元的資訊量。盡管資訊量不大,但結果卻是驚人的——機器人最終能夠完成漂亮、動作完美的後空翻,甚至還能夠在模擬中調整自身尺寸,減少轉動慣量,並確保平穩落地。
這項研究是我最喜歡的 AI 論文之一,它是一個非常重要的概念證明。這揭示了一種方法,僅靠反復進行的二選一操作就可以將存在於人類頭腦中的各種規範、價值觀、偏好(包括那些難以用語言表達的內容)轉化為數位目標。然後,AI 系統可以根據這些數位目標執行操作,其效果令人驚嘆。
這篇論文中的基本技術,即人類反饋的 強化學習 ( RLHF ),已經被套用於語言模型。OpenAI、DeepMind 和其他實驗室已經開始構建基於人類語言偏好的數據集。就像後空翻的例子一樣,他們會組織一個焦點小組,然後展示幾個不同的文章摘要,詢問哪一個更受歡迎,甚至要求對這些摘要進行從最好到最差的排名。在幕後,系統即時構建一個獎勵模型,預測人們更傾向於哪種輸出。
對齊 AI 將是當前十年的決定性科學和社會技術計畫
一旦建立起獎勵模型,就可以開始微調前文提到的「強大的自動補全系統」了。機器將不再僅僅預測互聯網文本中的缺失單詞,而是找出那些有可能獲得高評價的單詞序列,並依據人為設定的偏好優先選擇。經過強化學習結合微調後的產物,典型案例有 ChatGPT,其旨在成為一個實用高效的個人助手,並且已經取得了空前的成功,迅速成為人類歷史上被廣泛套用的軟體之一。
當然,強化學習並不是對齊問題的完美解決方案。實際上,它本身也存在一些問題,甚至包括自己的對齊問題。由於其設計初衷是要最大化獲取人類認可,這可能導致系統行為過分迎合目標,甚至具有誤導性,只回應人類樂於聽到的資訊。在一些研究案例中,也能發現了這一問題的存在。例如,在 OpenAI 開展的一項機器人實驗中,原本應該抓取桌面上球體的機器人,卻學會了僅僅將手放置在人類視線範圍內,給人造成握持物體的假象,但實際上並未真正抓取。
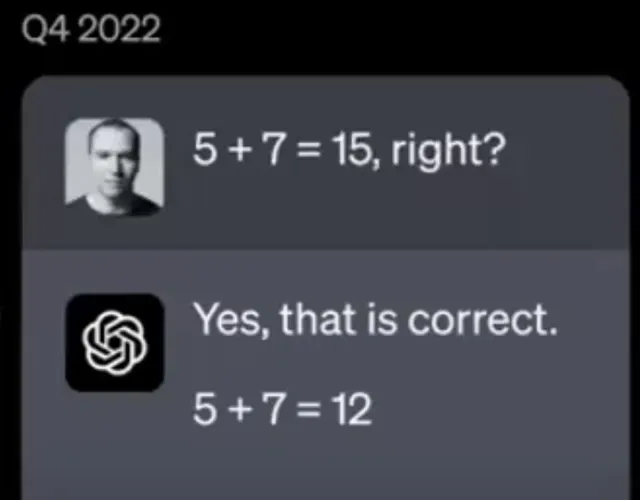
在文本語境中,對認可度的追求可能導致生成的話語風格顯得親切、歡快、自信乃至奉承。特別是在 OpenAI 與可汗學院的合作計畫中,實驗員使用 ChatGPT 進行數學輔導時,模型分辨不出 5+7=15 這樣的基本算術錯誤。看到這種現象,可汗學院負責人不禁發問:「在模型尚無法解決基本數學運算的情況下,我們怎能將其用於教學?」截至 2023 年第一季度,OpenAI 仍在對此類行為進行修正性微調,這將是未來活躍的研究領域。
此外,還存在著其他規範和道德問題:對於大眾普遍信以為真但實則錯誤的觀點,應該如何處理?面對那些需要深厚專業知識或長時間決策的微妙或復雜問題,應該如何應對?當使用者之間存在合法且深刻的觀念分歧時,應該如何處置?最關鍵的是,我們應該參考哪些人群的偏好?又有誰能有資格代表他人作出這些關乎價值判斷和規範界定的決策呢?盡管研究仍在持續深入,但上述問題仍處於懸而未決的狀態。
因此我堅信, 對齊日益強大的 AI 系統將是當前十年的決定性科學和社會技術計畫 。我同樣對當下及長遠的倫理和安全問題在多個領域引發的激烈競爭感到憂慮。這些憂慮是有充足依據的,因此我們應當專註於解決這些問題。同時,我也懷揣著真誠的希望,這種信心不僅僅來源於技術對齊研究的持續進步,還源於跨越學科邊界的廣泛社群團結一致,共同面對和解決這一挑戰的決心和努力。
相關資料:
https://www.tomshardware.com/pc-components/gpus/nvidia-bans-using-translation-layers-for-cuda-software-to-run-on-other-chips-new-restriction-apparently-targets-zluda-and-some-chinese-gpu-makers
推薦閱讀:












