經過演算法的改進和機器學習專用硬體的顯著提升,我們現在能夠構建比以往任何時候都更為強大的通用機器學習系統。
演講者 | Jeff Dean
整理 | 王啟隆
自從 2017 年谷歌發表了題為 「Attention is All You Need」 的重磅論文,其中提出的「自註意力」這一革命性的概念成為 Transformer 模型的核心部份,引領了我們目前正在經歷的 AIGC 革命。
然而,當前的大模型領域似乎並不是姓「谷」的,反倒是有種微軟一手遮天,谷歌和其他公司在後追趕的感覺。
為什麽現在會出現這種「逆轉」的情況呢?谷歌現在都做了些什麽工作?為了解答這個問題, 谷歌首席科學家 Jeff Dean 於 2 月 13 日在美國萊斯大學 進行了一場 1 小時 12 分鐘的公開演講, 突出展示人工智慧和機器學習領域中幾個令人振奮的趨勢,並介紹了谷歌在人工智慧時代的過去、現在與未來所做的工作,還概述了大家都很感興趣的 Gemini 系列多模態模型。
這場演講的時間很有意思,因為 ,搶盡風頭。
要弄懂這場演講,首先就得了解 Jeff Dean。他於 1999 年加入谷歌,目前擔任谷歌首席科學家,專註於 Google DeepMind 和 Google Research 的人工智慧進展。他的研究重點包括機器學習和人工智慧,以及將人工智慧套用於以有益於社會為基礎的問題。他的工作對谷歌搜尋引擎的多個版本、其初期廣告服務系統、分布式計算基礎設施( 如 BigTable 和 MapReduce )、TensorFlow 開源機器學習系統以及許多庫和開發者工具都產生了重要影響。
Jeff Dean
本文將整理 Jeff Dean 這場演講的內容( 有部份刪改 ),讓我們一起看看谷歌在 AI 時代已經做了什麽,未來又有哪些計劃。
演講視訊地址:https://www.youtube.com/watch?v=oSCRZkSQ1CE&t=1354s
Dean 觀察到的「質變」與「增長」
我將為大家介紹機器學習中令人興奮的趨勢。這將是一場廣泛而不深入特定領域的演講,其重點是讓你們了解這個領域的發展歷程以及其中的激動人心之處。同時我們也需要認識到其中的機遇,以及在為大家構建這項技術時應該註意的事項。
我會分享谷歌許多人的工作,其中有些是我親身參與並共同撰寫的,而有些則是我認為值得大家了解的優秀工作。
讓我們從一些觀察開始。在近些年,我認為機器學習真的改變了我們對電腦能力的期望。如果回想一下十年前,語音辨識技術只能稱得上「 勉 強 能 用 」,但並不是非常流暢,會產生很多錯誤;電腦對影像並不能做到真正理解,無法從像素水平理解影像中的內容;在語言方面,自然語言處理領域當時已有一些工作,但機器對語言概念和多語言數據的深刻理解並不是很明顯。
現在,機器學習已經從那個階段轉變到了一個比十年前的期望更好的狀態,電腦已經能夠看到和感知到我們周圍的世界,而這創造出了更多機會。
讓我們想象一下,當動物突然之間前進演化出眼睛時會發生什麽? 我們 目前在 計算領 域就有點類似於這 個階段。 我們現在有了能夠看到和感知的電腦,這是一個完全不同的局面。

AIGC 繪制圖片
另一個觀察是規模的增長,比如計算資源使用的大幅增加以及專用電腦技術的廣泛套用。我註意到數據集在不斷擴大,不僅更加豐富多元,而且愈發引人關註;同時,機器學習模型的構建規模也在不斷突破以往。這種規模的增長往往能夠帶來效能上的顯著提升,過去 10 至 15 年的發展歷程已經對此進行了有力驗證: 每當我們將規模進一步擴大,無論是解決問題的能力還是結果的準確性,都會實作一個質的飛躍 。原本無法觸及的精度閾值被逐漸突破,新的功能和套用也隨之應運而生,使得以前難以企及的事物變得觸手可及。
這種基於全新機器學習範式的計算需求與傳統的、依賴於人工編寫的復雜 C++ 程式碼大相徑庭,現有的許多 CPU 設計初衷是為了高效執行此類傳統程式碼。鑒於此,為了更有效地執行這類新型計算任務,我們需要尋求不同型別、更為適應的硬體解決方案。
實際上,我們可以透過聚焦於電腦需要執行的一系列更為專一的任務,並針對這些任務最佳化硬體效能,使其在特定領域內表現出卓越的效率。這樣一來,當我們需要擴充套件規模時,就能夠更加便捷且高效地實作這一目標。
電腦技術的十年飛躍
我剛剛應 該帶大家回想了一下十年前,事實上 計 算機技術在過去的十年 間確實取得了令人矚目的飛躍,特別是在機器學習和人工智慧領域。從影像辨識到語音處理、轉譯以及生成式模型的運用,這些進步都極大地拓寬了我們與電腦互動的可能性。
電腦視覺、語音辨識和自然語言處理技術在過去的十年間取得了令人矚目的進步 。十年前,電腦難以從原始影像像素中準確辨識並歸類到成千上萬的不同類別中,但現在這一任務對它們來說已不再是難題。音訊處理方面也有了顯著提升,現今的電腦不僅能透過分析音訊波形來理解並轉寫 5 秒內的語音內容,而且語音辨識系統的準確率和即時性相較於過去有了大幅提升。
在轉譯領域,機器轉譯的進步使得諸如將英語的打招呼自動準確地轉換為法語這樣的任務變得輕而易舉,這對於跨越語言障礙、促進全球溝通具有重要意義。
更令人驚奇的是,我們不僅實作了從影像到標簽或文本描述的轉化,比如能詳細描繪出一張獵豹站在吉普車頂的度假照片中的場景,而且還能夠逆轉這些過程:從一個簡單的類別標簽生成多樣的相關圖片,或者根據一句關於溫度的描述生成逼真的音訊表達,這是文本轉語音技術在不斷提升後的成果。
此外,還出現了從文本描述生成影像甚至視訊剪輯的能力,以及基於文本描述合成特定聲音片段的技術,這標誌著跨模態理解和生成技術的重大突破。這些能力的出現無疑極大地拓寬了電腦構建和套用的可能性, 與十年前的技術水平相比,我們現在可以利用這些先進技術創造出更加豐富多元的套用和服務,前景令人振奮不已。

史丹佛大學推出的 ImageNet 基準測試計畫是一個標誌性事件,該計畫涉及從包含大約一百萬張彩色影像及其對應的一千個類別標簽的訓練數據集中學習,並要求參賽系統對未見過的新影像進行準確分類。在 2011 年首屆競賽中,最佳系統的辨識準確率僅為 50.9%。
轉折點發生在次年, Alex Krizhevsky 和 Jeffrey Hinton 合作發表了一篇具有裏程碑意義的論文,推出了名為 AlexNet 的深度神經網路模型,該模型在比賽中取得了飛躍式的進展,將準確率提高了約 13%,這一突破性成就使得神經網路成為了主流選擇。當時,在所有 28 個參賽作品中,只有他們的團隊采用了神經網路技術,這標誌著一個革命性的轉變——從手動設計特征轉向直接從原始數據中學習模式,比如如何區分豹子與其他如長頸鹿或汽車等物件,這是手工設計方法難以企及的復雜度。
自那以後,進步的步伐並未減緩。 Ima geNet 挑戰賽中的準確率已經從 63% 躍升至當前的 91%,這一數值甚至超過了人類在此類任務上的平均表現,考慮到有 1,000 多個類別以及諸如 40 多種不同犬種這樣細微的區分難度,這樣的提升是極其顯著的。
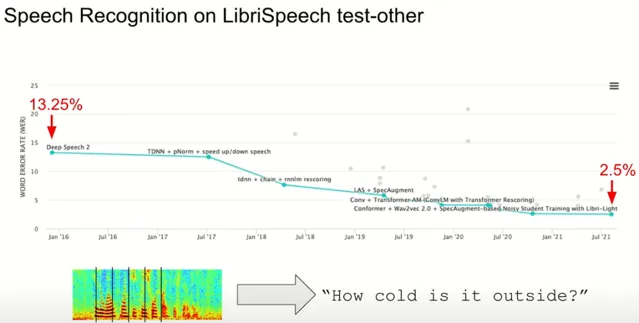
與此同時,語音辨識技術也經歷了類似的增長。以一個廣泛套用的開源基準測試為例,衡量標準為詞錯誤率( WER ),即錯誤辨識單詞的百分比。短短五年內,這項指標從 13.25% 下降到了驚人的 2.5%,意味著 原本每六七個詞就有一個錯誤的情況,現在變成了大約四十個詞才出現一次錯誤 ,極大地提升了語音辨識系統的可靠性和可用性,使之能夠支持諸如電子信件口述等實際套用。
此外,技術進步還體現在硬體最佳化和能效提升上。隨著更高效、針對機器學習最佳化的硬體不斷叠代更新,我們在保持相同計算資源消耗或能源使用的情況下,得以構建出品質更高、規模更大的模型,從而推動了電腦設計方式的根本變革。這些不斷提升的效率不僅改變了模型的品質,也為未來實作更加經濟和節能的人工智慧發展奠定了堅實基礎。
神經網路的獨特優勢
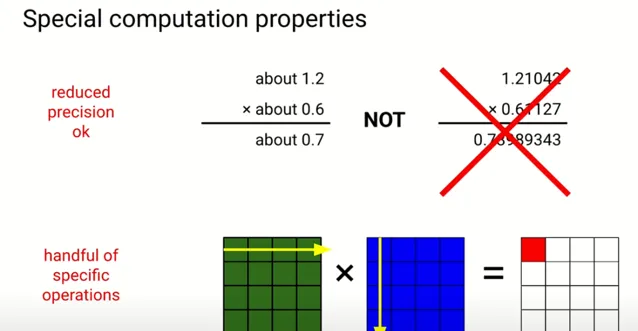
神經網路作為廣泛套用的機器學習模型,具備兩個特別的優勢。首先,它對計算精度的要求並不苛刻,在很多情況下,將模型中的浮點運算精度從六位數降低到一到兩位數是可以接受的,甚至 有 助於提升模型的學習效果 。某些最佳化演算法會特意引入雜訊以增強模型的學習能力,而降低精度在某種程度上類似於向學習過程中添加一定量的雜訊,有時候反而能帶來更好的訓練結果。
其次,神經網路中的大多數計算和演算法本質上都是線性代數操作的不同組合,例如矩陣乘法和各種向量運算等。如果能夠設計出專精於低精度線性代數運算的電腦硬體,就能夠 以更低的計算成本和能源消耗構建出高品質的模型 。
為此,谷歌研發了 張量處理單元 ( TPU ),這是一種專門針對低精度線性代數最佳化的系統架構。最初的 TPU V1 版本主要用於推斷階段,即當模型已經訓練完成並套用於實際產品環境時,比如辨識影像內容或語音辨識。與當時使用的 CPU 相比,TPU V1 在能耗和計算效能方面實作了 30 至 80 倍的提升。
TPU V2 和 V3 版本不僅提升了單個芯片的效能,還開始關註大規模系統的設計,支持多個芯片協同工作進行模型的訓練和推斷。其中,TPU V3 采用了水冷技術來提高散熱效率,而 TPU V4 則在外形設計上增添了時尚元素,加了一些五顏六色的酷炫電線( 觀眾大笑 )——其實還真挺酷的。

這三個叠代版本的芯片設計成能夠組裝成更大的系統,我們稱之為 Pod 。
第一代 Pod 的網路結構簡單,但頻寬高,采用 2D 網格布局,每個芯片與其四個相鄰芯片直接相連,確保了高速、低成本的數據傳輸。隨著技術進步,Pod 的規模不斷擴大,第二代擴充套件到了 1,024 個芯片,分布於八個機櫃中;而更進一步的版本則利用 64 個機櫃,每個機櫃有 64 個芯片,提供了超過 1.1 太赫茲的低精度浮點運算能力,共計 4,096 個芯片。

最近公開披露的 TPU v5p 系列有兩種型號,一種用於推斷,為擁有 256 個芯片的 Pod;另一種 v5p 芯片記憶體更大、芯片間頻寬更高、記憶體頻寬更充足,其 16 位浮點效能接近半 petaflop,並且混合精度效能是其兩倍。最大的 v5p Pod 包含了近 9,000 個芯片,可提供 exaflop 級別的強大計算能力, 為機器學習和人工智慧的發展帶來了前所未有的硬體支撐 。

語言模型的十五年征程
現在我 們來深入探討語言處理領域。 在影像辨識和語音辨識取得顯著進步的同 時,我認為語言領域是人們見證電腦能力發生最大變革的領域之一 。
2007:自然語言處理中的 N-gram 模型
早在神經網路廣泛套用之前,我就對語言模型抱有極大興趣。我曾與谷歌轉譯團隊合作,他們構建了一個用於研究競賽的高品質系統,雖然只能處理少量句子( 例如兩周內轉譯約 50 句話 ),但可以透過尋找大約 20 萬條 N-gram 實作高品質轉譯。盡管如此,我還是設想將這種高精度轉譯套用到實際場景中。
為此,我們建立了一個提供 N-gram 模型服務的系統,統計了超過 2 萬億個標記中每個五個詞序列出現的頻率,從而產生了大約 3000 億種獨特的五詞組合,並將其儲存在多台電腦的記憶體中以並列查詢。為了解決數據稀疏問題,我們創新地提出了一種名為「Stupid Backoff」的演算法,在找不到匹配 N-gram 時,會逐步嘗試尋找字首直至找到合適的詞匯序列。
這個經歷讓我深刻認識到, 大量數據只要結合簡單技術就可以產生驚人效果。
在我的職業生涯中,一直有類似的經驗:只需采取非常簡單的策略,就能讓數據自身揭示答案。

2013:Word2Vec 模型
隨後,我的同事
Tomas Mikolov
開始關註
分布式表示
的概念,即將單詞從離散表示轉變為高維向
量空間中的連續表示,
如使用百維向量來表示不同的單詞。
透過訓練過程,我們將出現在相似上下文中的單詞調整至彼此靠近的位置,並將出現在不同上下文中的單詞分隔開來。當在一個相對簡單的訓練目標下對海量數據進行訓練時,使得相似語境下的詞向量相互接近、不相似的則遠離,就能夠在高維空間中發現優秀的特征結構。在這個難以直觀理解的百維空間裏,類似概念的詞語會聚集在一起,例如山、小山丘和懸崖這些詞都會相鄰。更有趣的是,在高維空間中的方向也具有意義,比如國王與女王之間的向量差值指向的方向大致反映了男性與女性的一般區別。其他諸如動詞現在時態到過去時態的變化也有其特定的方向。 這些 分布式表示 蘊含著強大的力量, 能在單詞的百維向量編碼中 包含 多種型別的資訊。

2014:Sequence to Sequence(序列到序列)模型
後來,我的同事 Ilya, Oriol 和 Quoc( 編者註:這 裏面的 Ilya Sutskever 後來成為 ChatGPT 的頭號功臣;Oriol Vinyals 加入 Deepmind 成為首席科學家;Quoc V. Le 留在谷歌創造了 LaMDA )開發了一個被稱為「Sequence to Sequence」的模型,該模型利用神經網路,其中輸入一個英語句子,透過遞迴神經網路( 具體來說是長短時記憶網路 )逐詞更新狀態,形成與先前所見單詞對應的分布式表示。
當遇到句子結束標記時,模型被訓練輸出該句子的轉譯結果。在大量雙語平行語料上重復訓練後,模型能夠準確地從英語句子轉譯成法語句子。

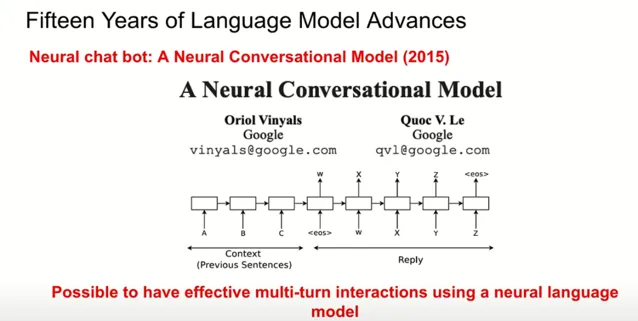
一年後,Oriol 和 Quoc 進一步發表了一篇研討會論文,展示了如何在多回合對話中運用上下文資訊。借助 Sequence to Sequence 模型,機器可以基於之前多個互動回合的上下文生成恰當回復。
2017:Transformer 問世
之後,谷歌的其他研究人員與一名實習生共同提出了「Transformer」模型,這一創新在於摒棄了傳統遞迴模型的順序依賴性,轉而采用並列處理輸入中的所有單詞,並透過註 意力機制聚焦於文本的不同部份,而非強制單個狀態按照順序處理每一個單詞。這不僅大 大提升了計算效率,而且在相同計算資源條件下提高了轉譯準確性高達 10 到 100 倍。
隨著硬體效能的不斷提升以及此類演算法改進的不斷湧現,大規模模型得以發展,變得更加強大。人們開始廣泛采用 Transformer 模型替代遞迴模型,不僅用於轉譯任務,還套用於對話式數據的訓練,取得了相當優異的結果。評估標準包括回應的恰當性和針對性,確保聊天機器人能針對互動內容給出具體有意義的回答。

2020- :百花齊放的大模型時代
在這一系列開發中,神經語言模型和神經對話模型日臻成熟,如 Meena、 OpenAI 的 GPT 系列,以及谷歌去年釋出的 Bard 等。在此基礎上,出現了基於 Transformer 架構的大型語言模型計畫,如 GPT-3/4,谷歌研究院的 PaLM,DeepMind 的 Chinchilla,谷歌研究院的 PaLM 2 以及由我和我的同事 Oriol Vinyals 共同領導的 Gemini 計畫。
在谷歌的多個研究辦公室中,有許多團隊成員致力於構建強大的多模態模型。一年前啟動 Gemini 計畫時, 我們的目標是訓練全球最佳的多模態模型,並在谷歌內部廣泛套用 。有關 Gemini 計畫的更多資訊,可以在相關部落格和由 Gemini 團隊釋出的技術報告中檢視,我有幸成為該計畫的一員,並對此深感自豪。
Gemini:「 天生 」的多模態大模型
Gemini 計畫自始便以實作真正的多模態處理為核心目標 。我們不僅局限於文本資訊,還致力於整合影像、視訊以及音訊等多種數據型別。首先,我們將這些不同模態的數據轉換成一系列標記,並基於此訓練 Transformer 架構的模型。該模型具有多個解碼路徑:一條路徑用於學習生成文本標記;另一條則是透過初始化解碼器的狀態,利用 Transformer 學到的知識從該狀態生成完整的影像像素集合。值得一提的是,Gemini 支持交錯式輸入序列,比如在處理視訊時,可以交替輸入視訊幀和描述幀內容的文本,或者是將音訊字幕嵌入到文本中,使得Transformer能夠跨多種模態構建共享的語意表示。
Gemini V1 版本提供了三種不同的規模選擇。其中,V1 Ultra 是規模最大且功能最強大的模型;V1 Pro 則適合數據中心部署,適用於各種產品環境;而 V1 Nano 模型專為行動裝置最佳化,能在手機或膝上型電腦上高效執行,進行量化處理後體積更小,適應力更強。( 編者註:在這場演講之後釋出的最高配置版本 Gemini 1.5 Pro 支持高達 1,000,000 token 的超長上下文,主打多工處理。 )
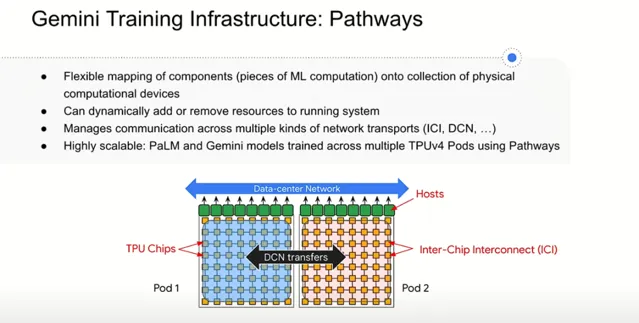
關於訓練基礎設施,我們追求高度可延伸且靈活的架構設計 。使用者只需指定高級別的計算需求,系統會自動將其對映到可用硬體資源上。我們采用 Pods 的方式組織計算資源,系統能智慧決定各個部份的最佳放置位置及芯片間的通訊方式,依據高速網路拓撲結構確保高效的數據傳輸。這樣,研究人員和開發者無需關心底層細節,只需關註模型效能特征差異即可。
在大規模模型訓練過程中,故障管理至關重要。隨著模型規模擴大,機器故障難以避免,如 TPU 芯片過熱等。因此,減少人為操作引起的故障並最佳化修復與升級流程至關重要。例如,在涉及大規模平行計算時,我們會選擇同時關閉所有相關機器進行內核升級,而不是逐個更新導致持續故障。此外,我們關註「 有效產出 」( good put )指標,即模型實際獲得有用進展的時間百分比,努力縮短恢復時間以加快整體訓練速度。
在訓練數據方面,為了打造一個多模態的模型,我們采用了大量多元化的數據集,包括網路文件、各類書籍、不同程式語言的程式碼以及影像、音訊和視訊數據。我們運用一系列啟發式方法過濾數據,並結合基於模型的分類技術來篩選高品質的內容。
具體做法是, 在較小規模模型上使用不同比例的數據混合進行訓練,並根據廣泛評估指標調整策略,例如增加特定領域的數據占比 。此外,我們計劃引入更多多語言數據以提升模型的跨語言能力。我們認為,數據品質的研究極為關鍵且有趣,高品質數據對模型在任務上的表現有著顯著影響,有時甚至比模型架構本身更重要。 在 未來,我們研究的一個重要方向將是模型如何自動學習辨別高品質範例與低品質範例的能力 。
驚動 AI 界的「 大模型 思維鏈」
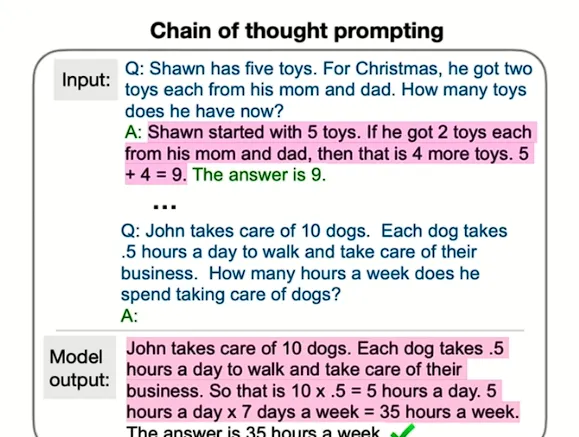
我的一些同事曾提出了一項名為「 Chain-of-Thought 」( 思維鏈 )的技術( 編者註:此處的同事指曾在 Google Brain 工作的 OpenAI 研究員 Jason Wei,谷歌在 2022 的年度開發者大會上特意對這一研究成果進行過宣傳 ),這種技術與我們小學三年級時數學課上老師的教學方法相呼應 。那時,老師總是強調展示解題步驟的重要性,這不僅是為了讓老師改卷時了解我們的思考路徑,也鼓勵了我們學會將復雜問題拆解為更易處理的小步驟。
在向模型提問時,通常我們會提供一個樣例問題和相應的正確答案,然後提出新的問題並要求模型 作答。 舉例來說,對於某個數學問題,如果模型僅僅被訓練來直接輸出答案,可能會得出錯誤的結果。如下圖所示,直接問問題會讓模型得出 50 這個錯誤答案。

然而,當采用思維鏈的方式時,透過向模型展示逐步的解決過程,比如「尚恩起初有五個玩具,每次獲得兩個新玩具,所以總數是五個加上四個,等於九個...」,可以使模型被激發,去采取漸進的方式找到答案。說白了,就像幼教一樣 ( 觀眾大笑 ) 。
這種方法使模型有更多的時間去思考並正確解決問題,從而產生了顯著的效果。
這展示了同一底層模型在不同規模下的表現差異,面對數學問題時,僅使用標準提示的情況下,模型的解答品質較差。但隨著模型規模增大到一定程度後,在套用「思維鏈」的策略時,準確率就有了大幅提升。
我認為這揭示出一個有趣的科學領域: 如何恰當地向這些模型提問,使其不僅能給出可解釋的答案,而且更有可能得出正確的結果 。
接下來順著這個話題,我想談論的是 Gemini 模型中的多模態推理能力。比方說,我們可以給模型提供一個多模態輸入,包括一張學生手寫的物理問題解決方案圖片、相關的問題圖片以及關於能量守恒的文字描述;然後, 用「思維鏈 」風格要求模型逐步分析這個問題,判斷學生的答案是否正確,並在答案錯誤時指明錯誤之處及提供正確解答,同時要求在數學部份使用 LaTeX 格式並將最終答案精確到小數點後兩位。
接下來,在一個具體的實操案例中,我們輸入包含一張手寫物理習題解答的照片,以及一幅描繪滑雪者從坡道滑下的影像,附加有關能量守恒的文本說明。
Gemini 的模型分析結果顯示,學生在計算坡道起始處的勢能時犯了錯誤,誤用了斜面長度而不是高度進行計算。模型給出了糾正後的正確解決方案,並以排版良好的形式呈現出來。

這意味著 Gemini 能夠接受復雜的多模態輸入並執行所需的推理操作 。雖然它並不總能達到預期效果,但它無疑已經具備了這樣的潛力。這種能力令人驚嘆,完全可以用於教育。設想一下,一名學生拍下自己的解題照片,系統能夠幫助他們找出錯誤並予以修正,或授權以接近實作類似個人化輔導的效果。
在對 Gemini 模型進行評估的過程中,我們發現其在多個特征上都表現出卓越的能力。評估有助於我們辨識模型的優點和不足,監測訓練進度,並據此決定改進方向,比如當我們發現數學效能低於期望時,可能需要增加數學相關的訓練數據。但這樣做也可能影響多語言效能,其間存在著許多復雜的權衡。我們在訓練初期做出某些決策,同時線上監控並在必要時基於原則或直覺調整策略,以對比和理解模型相對於其他模型的能力差異。
總體來看,Gemini 在研究涉及的 32 項學術基準測試中,於 30 項測試達到了最先進的水平。特別是在針對數學問題、一般推理或文本導向基準等方面,Gemini Ultra 與之前的最先進技術 GPT-4 相比,往往能取得更好的成績。例如,在八個八年級數學問題上,最先進技術的準確性達到了 90%,而在 MMLU 這樣涵蓋化學、數學、國際法、哲學等 57 個學科的廣泛問題集上,Gemini 的表現甚至超越了人類專家水平。
我想強調的是,評估團隊在全面理解並評測這些模型能力方面付出了巨大的努力,他們的工作非常出色,讓我們對 Gemini 模型的強大功能有了深入的認識。
不斷前進演化的 AI 影像創作技術
接下來讓我們聊一聊 AIGC 模型在影像和視訊創作方面的進展。當前有許多模型( 如 Parti, Imagen )可以實作根據使用者輸入的描述自動生成影像,這些模型能夠接受對視覺內容的文字提示,透過理解並編碼句子的含義,進而生成對應的影像像素。
例如,「 一列蒸汽火車穿越一座巨大的圖書館,畫面采用林布蘭油畫風格」,或者「由玉米、煎餅、壽司或沙拉材料構成的一條巨型眼鏡蛇 」——我覺得其中生菜造型的眼鏡蛇頗具創意,而玉米材質的也很有趣。
當然,還可以描述出非常細節豐富的場景:「 一張客廳照片,內有一張白色的沙發和壁爐,墻上掛著一幅抽象畫,明亮陽光透過窗戶灑入室內。 」
對於演示或其他用途所需的圖片,這樣的模型可以輕松建立符合要求的內容。甚至可以生成像這樣詳盡描述的畫面:「 一張黑白高對比度照片中,一只戴著巫師帽、正在閱讀書籍的熊貓騎在馬背上,背景為灰色混凝土墻,墻上有彩色花朵和‘和平’字樣裝飾,照片模擬單眼相機日間拍攝效果。 」
這種技術現已整合到 Bard 中,伊利諾州的 K-12 公立學校機構就利用此功能創造出了他們的吉祥物 Hyperlink the Hedgehog 的各種形象,比如下圖這只在 AI 浪潮上沖浪的刺猬。
讓我簡要概括一下影像生成的工作原理:首先,使用者輸入提示語,模型基於分布式向量表示來理解句子,然後生成一個小規模的初步影像;接著,另一個專門用於提高分辨率的模型會在低分辨率影像的基礎上,結合文本嵌入資訊生成更高畫質的像素;最後再次使用更大尺寸的影像和文本條件,生成完整的 1024x1024 像素的高畫質影像。
如上圖所示,以四個參數量從 350 萬至 200 億不等的模型為例,給它們相同的提示:「 一只穿著橙色連帽衫、藍色太陽鏡的袋鼠站在雪梨歌劇院前的草地上,胸前掛著一塊寫著‘歡迎朋友’的牌子。 」隨著模型參數量的增加,生成結果的品質也隨之變化。較小規模的模型能夠捕捉到袋鼠的部份特征和橙色元素,以及牌子的存在,但處理文字時稍顯吃力。當模型規模增大時,袋鼠的形象更為逼真,也更好地描繪了雪梨歌劇院的大致輪廓,不過細節欠佳,牌子上的文字也未能完美展現。
然而,當達到足夠大的規模時,模型能生成包含雪梨歌劇院和清晰袋鼠形象的高品質影像,並準確地展示了「歡迎朋友」( Welcome friends! )的文字。這表明模型規模的重要性 ,過去十年中規模的擴大以及更好的訓練方法和演算法的進步,共同推動了生成結果品質的顯著提升 。
我還觀察到另一個不可忽視的重要方向,即 機器學習如何悄無聲息地融入人們的日常生活,特別是在智慧型手機套用中發揮關鍵作用 。現代智慧型手機網路攝影機功能的巨大提升得益於計算攝影技術和機器學習演算法的深度融合。例如,iPhone 的肖像模式利用這一技術實作背景虛化,使前景人物更加突出,為拍攝藝術感十足的人像照片提供了便捷工具。而夜間模式則允許使用者在極低光照環境下也能拍出高品質的照片,透過軟體處理傳感器捕捉到的大量數據,模擬出比實際環境更為明亮的成像效果,這不僅有助於拍攝清晰的星空照片,還支持人像模糊、色彩增強等高級編輯功能,在特定場合下顯得尤為實用。
此外,一些手機上的「魔法橡皮擦」功能能讓使用者輕松移除圖片中的特定物體。比如,如果你不希望自己拍的美景中出現某個電線桿或者人群,只需指示系統輕松擦除他們,以保持照片的純凈度。
智慧型手機上搭載的許多智慧服務都聚焦於資訊或狀態的轉化與傳遞 。有時候我們可能不方便接聽電話,這時就可以啟用由電腦生成語音代答的功能,它會詢問來電者的意圖,並將通話內容轉寫為文字供你檢視,以便決定是否回撥。這一類「代聽」功能在撥打銀行客戶服務熱線時特別有用,可以讓 AI 代替人類一直線上等待,並記錄對方反饋的資訊。
即時字幕功能同樣展現了強大的實用性,它可以自動為我們播放的手機視訊提供同步的文字轉錄。當我們身處圖書館或其他安靜場所,不想打擾他人時,這個功能就顯得格外貼心。
同時,對於視聽障礙人士以及需要跨語言交流的使用者來說,手機網路攝影機結合閱讀和轉譯功能也帶來了革命性的進步。只需對準文本或指向螢幕上的內容,手機就能朗讀所指內容;如果遇到非母語文本,手機還能幫助朗讀並即時轉譯,極大地提高了溝通效率和便利性。
機器學習在我們看不見的地方同樣發光發熱
我在大模型領域觀察到的另一個重要發展趨勢是 將通用模型進一步最佳化,轉化為領域專用模型 。
我的一些同事在 PaLM 和升級版的 PaLM 2 模型的研究基礎上,取得了一項顯著成果。PaLM 2 作為一個通用文本訓練模型,經過針對醫學數據集(包括醫學問題和文章)的深化訓練與微調後,產生了 Med-PaLM 模型,並且該模型首次在醫學考試中超越了及格線。六個月後,他們又推出了 Med-PaLM 2,在特定醫學考試任務上實作了專業級別的表現。 這個 例子確實證明了先擁有強大的通用模型,再進行領域適應力訓練的巨大潛力。
此外,我覺得 材料科學 是一個極其有趣的領域。在這個領域中,機器學習已經開始深刻影響科研行程。 透過自動化探索科學假設空間以及構建快速、高效的模擬器,機器學習正在以前所未有的方式推動材料科學的進步 。在某些情況下,機器學習能夠生成與人工編碼模擬器功能相當但速度卻高出幾十萬倍的模擬工具,這使得科學家能夠在短時間內篩選數以百萬計的化合物或材料,並行現具有獨特性質和潛力的新物質。
DeepMind 等研究團隊正致力於研發創新方法,利用圖神經網路( Graph Neural Networks,GNN )對潛在材料進行表示,透過結構變異來尋找相鄰且可能具備新穎特性的材料結構。結合已知材料資料庫中的能量模型,這些研究工作已經成功地自動發現了超過 220 萬個新的晶體結構,從而為實驗室合成提供了一批具有實際套用前景的候選材料。
在 醫療保健 方面,機器學習同樣展現了巨大的套用潛力。特別是在醫學影像分析和診斷上,機器學習技術已經在處理從二維影像到三維醫學成像( 如 CT 掃描 )等各種復雜問題上取得了顯著成效。其中,糖尿病性視網膜病變的篩查就是一個重要的套用場景。這是一種如果早期發現並治療則可有效控制病情的眼科疾病,但如果延誤診斷,則可能導致嚴重的視力損害甚至失明。然而,全球範圍內具備解讀視網膜影像能力的眼科醫生資源有限,難以滿足大規模篩查需求。
機器學習在此領域的介入極大地提高了篩查效率和準確性。透過對經過眼科醫生標註的視網膜影像數據進行訓練,可以構建出與專業眼科醫生水平相當的 AI 模型,用於辨識視網膜病變的不同階段。當進一步使用視網膜專家級別的標註數據進行訓練時,模型的表現甚至可以媲美經驗豐富的視網膜專家。 這意味著只需在普通膝上型電腦上配備 GPU,就可以實作與頂級專家同等水平的篩查品質 。 目前,相關研究機構已經與印度的眼科醫院網路、泰國政府以及其他歐洲國家的組織合作,開展大規模的糖尿病性視網膜病變篩查計畫。
此外,在 皮膚科學 領域,機器學習同樣大有作為,因為它允許透過簡單的照片采集來分析皮膚病癥狀。部署的相關系統可以基於大量的皮膚科影像資料庫,幫助使用者判斷其皮膚病癥狀的嚴重程度和可能的病因,從而為患者提供了初步評估及決策支持。
結語
總的來 說,我認為現在是電腦領域極為振奮人心的時代。
我們正見證從手寫編碼軟體系統向學習型系統的轉變過程,這些系統能夠以多種有趣的方式與世界互動,並與人們進行有趣的交流。
如今,電腦能夠處理、理解和生成的媒介型別正在不斷擴充套件,我相信這將使電腦的使用變得更加無縫和自然。很多時候,我們僅局限於鍵盤輸入等互動方式,但現在,我們已具備了以非常自然的方式與計算系統交談的能力,它們能理解我們的言語表達,並能夠根據需求以自然的聲音作出回應或生成精美的影像。這一切都讓人感到無比激動。
當然,巨大的機遇面前也伴隨著巨大的責任。如何推進這項工作,確保其對社會有益,並真正為世界帶來積極影響,是我們需要深思並付諸實踐的問題。
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的「 全球機器學習技術大會 」將在上海環球港凱悅酒店舉行,特邀近 50 位技術領袖和行業套用專家,與 1000+ 來自電商、金融、汽車、智慧制造、通訊、工業互聯網、醫療、教育等眾多行業的精英參會聽眾,共同探討人工智慧領域的前沿發展和行業最佳實踐。 歡迎所有開發者朋友存取官網 http://ml-summit.org、點選「閱讀原文」或掃描下方海報中的二維碼 ,進一步了解詳情。











