導讀
在當今快速發展的大數據時代,數據平台的效能和效率對於企業來說至關重要。雲器Lakehouse的Multi-Cluster彈性架構為我們提供了一種全新的視角,以應對數據湖上高並行和低延遲分析的挑戰。本文將深入探討雲器Lakehouse如何透過其獨特的技術理念和架構設計,實作在數據湖上進行高效能實分時析的目標。
本次分享會圍繞以下幾方面展開:
面客實分時析場景對數據平台的要求
基於數據湖實作高效能實分時析的挑戰
雲器Lakehouse存算分離架構下實作高效能實分時析
典型案例分析
總結
面向客戶的實分時析場景對數據平台的要求
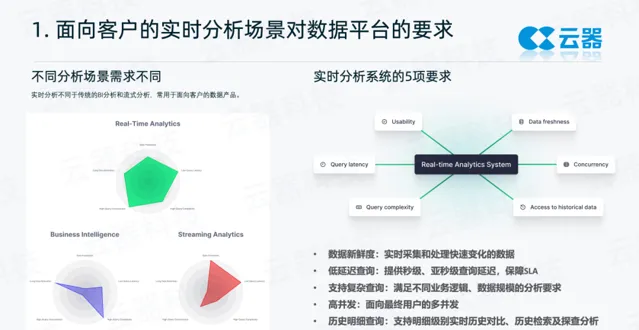
實分時析不同於傳統的BI分析和流式分析,常用於面向客戶的數據產品。常見的分析場景主要有以下三類:
BI分析:常見的 BI 分析場景對並行要求不高,分析相對比較復雜(如鉆取),對查詢的要求相對中等。
流式分析:比如常見的風控即時大屏,對數據的時延要求非常敏感,但對並行要求不高,數據處理規模通常不會特別大。
實分時析:要求數據要及時,查詢很快能拿到結果,同時能夠支撐比較大的並行,很可能有成百上千人在同時使用這個數據產品。另外,查詢有簡單的查詢,也會有較為復雜的查詢,要求數據範圍更廣。
本文重點介紹的是實分時析場景,實分時析常見於面客(Customer-facing)的數據產品,對查詢數據的新鮮度、查詢時延、並行、即時和歷史數據的即時對比分析都有很高的要求。
基於數據湖實作高效能實分時析的挑戰
在上述要求下,現在非常流行數據湖架構和湖倉一體架構。數據湖天然具有很多優勢:
低儲存成本,所有的數據可以放在統一的儲存上,減少冗余。
擴充套件性較好,可以很好地做存算的分離。
統一的數據管理能力,支持批次更新、刪除等能力。
多場景支持,能夠很好地支持批、流、分析、 AI 等處理場景。
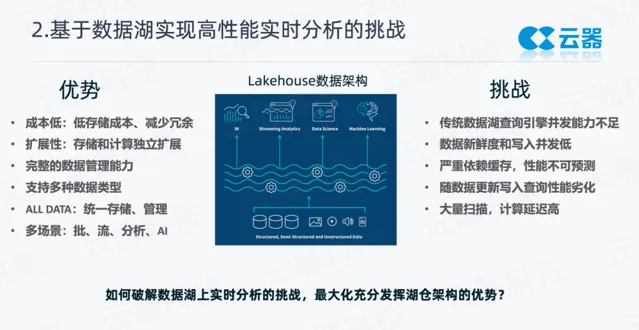
在數據湖上做數據分析,也面臨一些挑戰:
存算分離架構,計算和儲存離得比較遠。數據湖儲存本身面向吞吐,時延 IO 效能不是特別好。在數據湖的解決方案中,主流的數據湖查詢引擎,並行能力往往不太突出。這也是我們能看到市面上開始流行一些並行效能更好的分析引擎的原因。
由於數據湖的寫入需要去落檔、管理Meta,寫入的頻率不能太高、間隔也不能太短,否則對 Meta 壓力很大,往往做不到低延遲的寫入可見性。
嚴重依賴緩存,其實數據能夠被緩存的話,可以獲得較好的可預測效能。而一旦有新的數據進來,或者是不在緩存中的歷史長周期的數據,整個的效能抖動就會非常明顯,這對於分析數據產品來說,往往是不可接受的。
因為數據湖要存大量的數據,隨著數據的變化更新,數據規模的增大,在湖上建數據分析產品,查詢的效能會逐漸地劣化。
怎麽才能夠更好地發揮數據湖的優勢,解決這些即時的挑戰呢?
雲器Lakehouse:「Single-Engine」為技術理念的數據平台產品
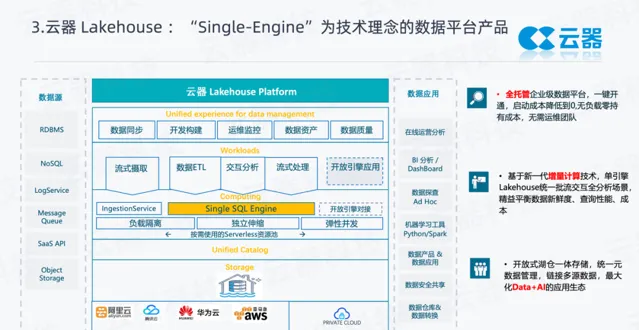
雲器在產品設計之初,就考慮到了這些分析場景。產品的設計要點如下:
所有的雲器產品,有兩種部署模式,雲上的多雲 SaaS 服務,以及大型客戶的私有雲部署。
使用物件儲存,透過一套後設資料去管理結構化數據和非結構化數據。
作為一個 SaaS 化的多租戶系統,我們會維護一個大的 serverless 彈性資源池,客戶在使用的時候能夠快速地按需使用資源,不用的時候可以交還給雲器,減少不必要的資源持有成本。
在計算側,基於這樣一個大的資源池,雲器的產品支持建立多計算資源,相互隔離互不影響。資源有很好的彈性,能夠獨立地伸縮,根據並行場景做快速的彈性來滿足使用者側的並行變化。
我們的核心特性是基於一套自研的 SQL 引擎,支持常見的大數據處理ETL、流式處理,提供基於增量計算這種近即時的流式處理,基於一套數據,可以在數據集上直接進行線上的互動式分析。
為了保證整個系統的數據能夠很好地處理流式數據,我們設計了即時的寫入服務能力。提供 Streaming 的 API,能夠把流式數據很好地寫入進來,支持秒級可見。
更上層,是一套 SaaS 化的服務,產品內建了數據同步、數據開發、監控運維、數據資產管理、數據品質等工具。將這些日常使用的開發管理工具,做成一體化的產品,以Web套用的形式對外提供服務。
1. 基於Multi-Cluster彈性、即時架構,應對規模化的即時數據和查詢並行挑戰
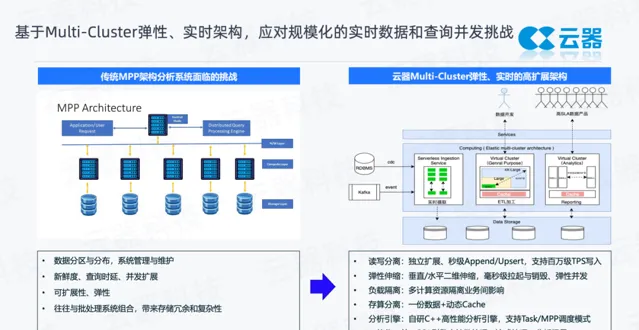
前文中提到,數據湖並不太適合做即時化的作業,而且數據湖上的加速分析引擎往往對並行支持也不夠好,雲器基於 Multi-Cluster(多計算集群)+ 即時化的架構(多集群的彈性和即時化的架構)來應對這樣的挑戰。
傳統的MPP架構,是存算耦合的方式(如圖左半部份),每個節點有自己的分片數據單獨做處理。這種緊耦合帶來的挑戰是數據一旦需要擴充套件,就要重新分布,會對業務造成影響,很難做到快速擴充套件。同時這種模式,對即時寫入的支持也不夠友好,當然很多廠商也在做進一步的最佳化。
受制於這樣一個存算耦合的架構,整體的擴充套件性和彈性是相對偏弱的。同時 MPP 架構,在傳統的 Lambda 架構裏常用於做 OLAP 分析,對接 BI 報表。它的批次處理數據的準備、數據的加工往往需要和大數據批次處理系統結合,把加工好的數據再匯入到裏邊,會產生額外的數據冗余和整體系統的復雜性。
雲器從以下幾個層面來解決上述問題:
讀寫分離:采用存算分離的架構,數據和計算無關,計算可以獨立地擴充套件,不受儲存的影響。同時為了更好地應對即時數據的挑戰,我們設計了一套即時攝取的服務。常見的資料庫 Binlog 的 CDC 寫入、 Kafka 訊息服務的寫入,都可以呼叫streaming 的 API 快速地寫入,寫入之後秒級可見。
支持基於主鍵的更新,基於這樣的讀寫分離的架構,數據的寫入後使用單獨的集群讀取、處理、分析數據,寫入任務不影響數據加工和分析,它們之間做到了解耦。這樣一個獨立的寫入服務本身具有很好的伸縮性。在實踐中,能夠支持每秒千萬級TPS的寫入吞吐,很好地解決了數據新鮮度和規模化的問題。
在計算層,Multi-Cluster 有兩層含義。第一層含義是,不同的計算任務有獨立的計算集群,它們共享一份數據,但計算是隔離的,這是多計算集群的內涵之一。第二層含義是,計算資源支持垂直和水平的彈性伸縮能力。舉例來說,當數據產品剛剛上線的時候,使用率並不高,隨著數據產品的推廣,大量的使用者開始使用,並行就會更高,對於平台的訴求就是能夠很好地去承接變化的高並行需求,這也需要計算資源具備很好的彈效能力。Multi-Cluster 的核心是一個計算資源裏有多個可獨立承擔並行任務的計算資源。
前文提到數據湖嚴重依賴緩存,我們設計了cache機制,基於數據湖上物件儲存的一份數據,提供動態的cache 能力,cache 本身隨整個計算資源的生命周期產生和消亡。當建立計算資源時,查詢會把數據拉到本地cache,當釋放掉資源的時候,cache本身也會銷毀掉。透過這樣一套模式來更好地利用本地計算資源的本地cache。
分析引擎:雲器產品內建的 SQL 引擎是其核心的一個差異化點,我們自研了一套 C++ 的高效能更新引擎。一個獨特的優勢是這套 SQL 引擎支持不同的負載模式,使用不同的任務排程模式來滿足。比如常見的數據加工場景,往往需要基於任務獨立申請資源,基於 DAG 依賴關系的排程模式來更好地保持吞吐和可靠性。分析場景,往往需要 MPP 以及 Pipeline 的執行模型來更好地支持加速分析和高並行。
一體化:所有對使用者的介面,都是一套 SQL 語法來滿足批次處理、流式和分析。
2. 彈性並行(Concurrency Scaling)以低成本滿足動態變化的分析要求
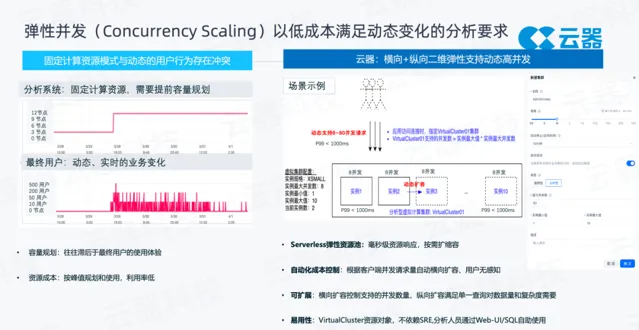
彈性並行方面,常見的方案是使用固定的計算資源,比如要支持 200 位使用者的並行使用,需要申請12個計算節點,即使沒有人存取,這12個計算資源也一直占用著。如果突然有業務峰值,業務方需要提前提出擴容訴求,才能進行擴容,造成了很多的資源浪費。由於使用者的請求是動態的,使用者什麽時候來存取、分析數據產品是不確定的,所以這種固定資源 + 容量規劃的模式往往滯後於使用者的使用,會造成使用者體驗的下降。按峰值規劃又造成了資源浪費。
在雲上我們借助雲原生能力把計算資源虛擬化,透過大的 Serverless彈性資源池,能夠快速地申請資源。雲器產品中,我們抽象了資源物件VirtualCluster 虛擬集群,集群本身有縱向和橫向擴容的能力。如上圖右側所示,使用者在建立計算資源的時候,可以選擇資源的大小(縱向擴容)和平行計算例項的數量(橫向擴容)。如果把方框看成一個計算資源的話,使用者的 Query 是下發給計算資源的。內部至少包含一個計算資源例項,資源規格在建立時指定,並可以快速調整。同時也可以透過設定整個資源的最小例項數和最大例項數,形成從例項 1 到例項 10 的多計算集群資源模型。
舉例來說,某個數據產品需要支持最高80個並行請求。在設計資源的時候,我們建立了1~10 的資源例項,每個資源例項支撐 8 個並行,當有 80 個並行同時來的時候,透過橫向的動態擴容,可以毫秒級地將資源例項彈出來,把新增加的並行請求接住。由於是毫秒級的彈效能力,所以客戶是無感的,幾乎不知道資源做了擴容。當使用者的請求負載下降,能自動回縮,這樣整體的資源成本會很低。舉例說明:單個計算資源例項在 8 並行時,可以保證每個例項下 P99 的查詢都小於 1 秒,這是我們對業務方的承諾。透過設定最大例項=10這樣的方式,當有 80 個並行來的時候,橫向擴充套件出 10 個計算例項,透過橫向擴容能夠保證每個使用者的查詢都可以達到 P99的SLA,這也是雲器的一大亮點,能夠精細地控制資源和並行延遲之間的線性關系。
3. 使用Preload cache提升即時查詢的效能穩定性,消減即時數據帶來的查詢抖動
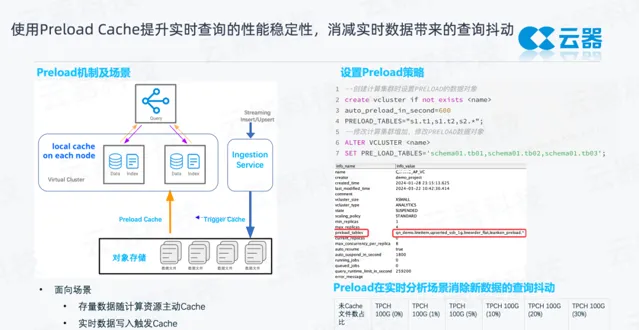
前文中提到,數據湖天然要對數據做持久化,所有的數據進到湖裏,要先落盤做數據持久化,防止數據遺失。之後這些數據就在物件儲存上,可以視為冷數據,查詢延遲會較高,在分析時就會導致很多查詢抖動和毛刺。
雲器提供了 Preload cache 能力,主要面向兩種場景:
離線場景,數據本身是 T+1的,數據的變化不高頻,只要定期及時地把 T+1的數據載入到本地緩存就可以了,這樣分析就是穩定的,類似於存算一體的 MPP。這裏采用的方式是建立計算資源的時候,增加 Preload 的參數,能夠把數據產品涉及到的表都配置進來,系統自動根據配置把數據拉到 cache 中,不再根據使用者的 Query 去喚醒。
實分時析場景,有大量的流式即時數據,比如訂單數據,每秒都有大量的變化。這些數據往往要被及時地分析,雲器在數據寫入持久化的同時,立即主動 trigger 一個 cache動作將心數據緩存至 計算集群的本地緩存中。透過這樣的方式,能夠有效避免大量地讀冷數據,從而保持對業務的高SLA。舉個例項(如右圖),以TPCH 100G數據測試,如果這些數據100%都是在本地cache中,整個的查詢時延很低,9秒即可完成。如果有30%數據在物件儲存上,整個查詢時延就要翻倍。特別是實分時析場景裏有大量即時更新的數據進來,即使有1%,也會極大地拉低整個的查詢延遲。這也是為什麽我們去做Preload的工作。
4. 借助自動化、智慧化的托管能力,降低效能最佳化投入、支持分析套用持續高效營運
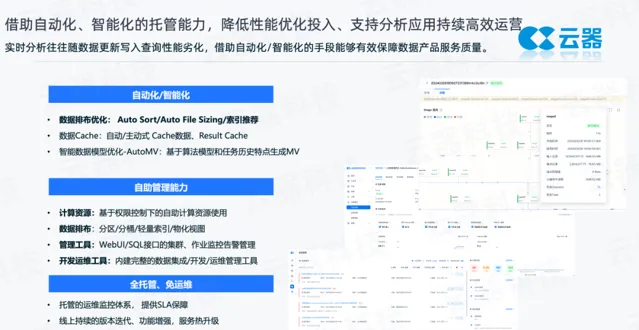
產品建設初期,因為數據規模不大,使用的人也並不多,效能容易得到保障。隨著產品的持續營運,數據規模和使用者量都不斷增長,就需要一些手段來持續最佳化。雲器提供了一些手段來自動管理。
全托管、免運維:提供全托管、免運維的 SaaS 化服務,使用者不用考慮底層的基礎設施,我們有專業的團隊做相關的運維,監控底層的基礎設施,提供商業化的 SLA保障。同時會以比較高頻的節奏做版本叠代,增加功能、提升效能,整個服務是透過客戶無感知的方式自動做升級。同時我們有大量的自動化服務,比如 Compaction 合並小檔,特別是即時場景有大量的小檔,這些數據往往需要去做更好的數據分布和收集統計資訊,這些工作都由系統自動化地完成。
自助管理能力:彈性計算資源,透過 SQL 介面或者 Web UI 介面,能夠讓分析人員、一線的業務人員直接建立、管理、銷毀、擴縮容資源,不用再依賴 SRE 或者平台團隊人員,能更好地實作資源使用的民主化。數據排布上,有大量的最佳化手段,比如對慢查詢可以做針對性的最佳化,同時也提供了配套的監控診斷工具。
自動化/智慧化:有些部份透過 AI 的方式驅動。比如數據排布的場景,很多分析查詢往往需要做欄位的快速過濾,因此建數據模型時會建 Sort 的模式,提升過濾效率。隨著新的數據不斷進來,Sort 本身的排序就不好了,系統會自動幫它做排序。另外還可以做自動的檔大小處理,分析場景的熱數據檔往往較小,能夠被快速地去分析檢索;當這些數據變成冷的歷史數據的時候,更多要考慮歷史查詢的成本,需要把單個檔變大,最佳化吞吐。同時還提供了索引推薦,基於演算法找到熱點的Key進行推薦。Cache方面,包括自動/主動的cache,也支持偏分析場景的 result cache。在數據的建模方面,有AutoMV,能夠基於演算法模型,結合日常的作業模式,在ADHoc或者 BI 分析和ETL 場景下,都能夠找到其中的Pattern,主動地幫你做中間層的模型,生成物化檢視,這樣作業不用改就能做透明加速。
典型場景分析
接下來結合一個例子,來對產品核心功能進行展示和講解。
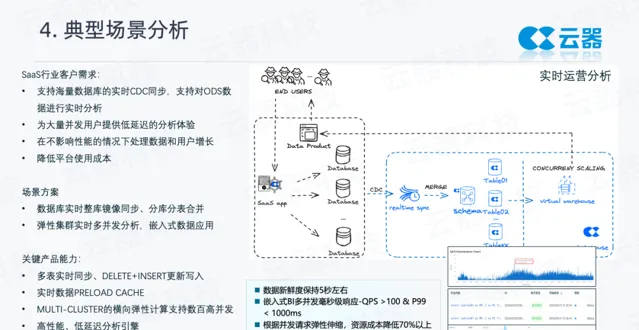
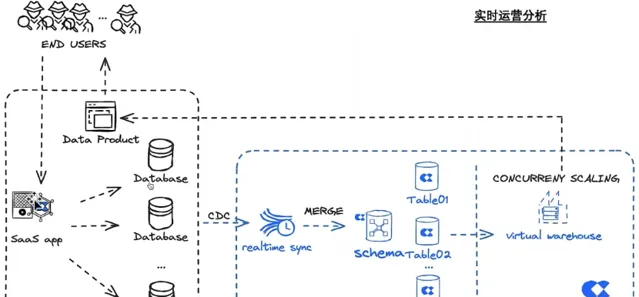
以SaaS 企業的即時營運分析為例, SaaS 企業裏有很多的多租戶數據在資料庫中產生,有大量的分庫分表。這類場景,往往需要將這些交易訂單數據快速地分庫分表地合並到資料倉儲中,並立即開放給租戶進行數據分析,幾乎沒有任何的數據加工。
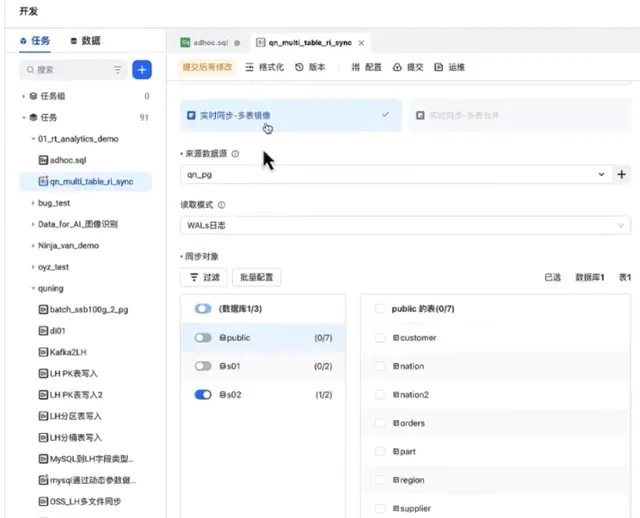
這裏具體展示的場景是,數據來自於資料庫qn_pg,透過日誌模式去訂閱它的 CDC 數據。產品具有即時同步的能力,能夠支持多表一鍵同步。例如訂閱了一張表,把這張表同步到雲器Lakehouse的表中。
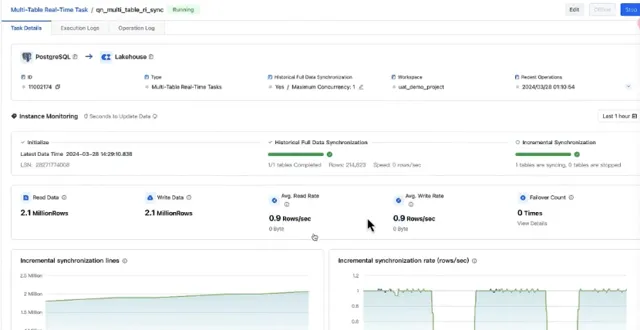
任務建立完之後,可以看到,能夠以秒級延遲的速度,將最新的數據寫入到 Lakehouse中。
從雲器的 Lakehouse中檢查一下新寫入數據的新鮮度,能看到即時增加的數據,這些數據都是透過主鍵的方式即時更新進來。
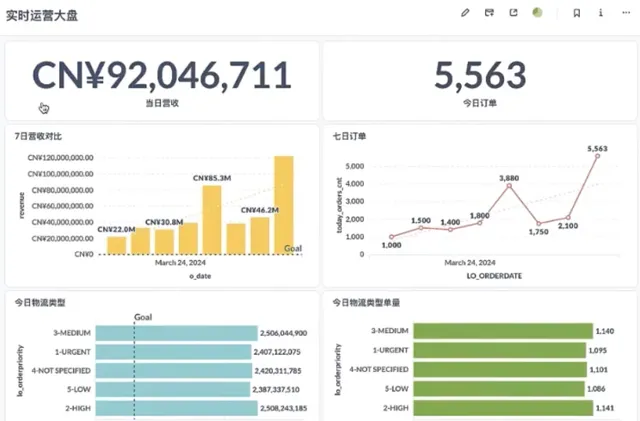
即時數據透過營運大盤展示給客戶。上圖中的DashBoard包含8個Query,能夠查詢到最新的即時的數據。
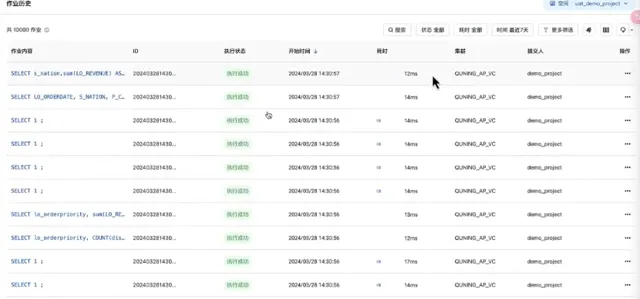
上圖中可以看到在BI報表查詢時發起的query,這些 query 在雲器平台能夠以毫秒級的延遲完成。
再來展示一下彈性計算能力。
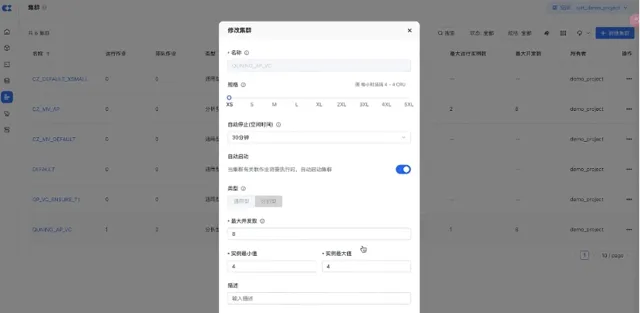
剛才是單並行,單個計算資源是 8 並行。同時建立 4 個這樣的計算例項,同時可以支持 32 並行。
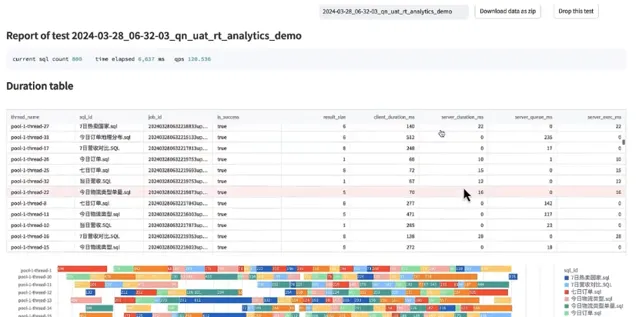
以我們的壓力測試工具來驗證,每個作業跑 100 遍, 以 32 個並行連線,不停地去發。可以看到並行情況,32並行,整個 QPS 在 120 秒,每個 query 在百毫秒就已經結束了。這就是客戶端查詢的情況。
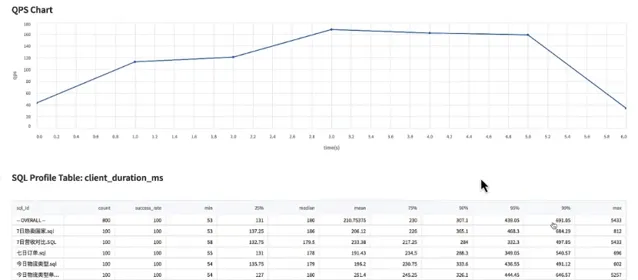
這些 Query 的查詢延遲分布是在一個比較低的水位上,P99在百毫秒級別。
這就是前文講到的,透過多並行的橫向擴充套件能力,支持精細的並行控制,以滿足業務的並行和延遲的要求。
剛才是使用了 4 個計算資源,現在調整為一個,也就是預設只啟動一個資源,後面三個是不啟用的。只有當並行來的足夠多,超過 8 個的時候才去彈性伸縮。
進行同樣的測試,同時發起 32 並行。
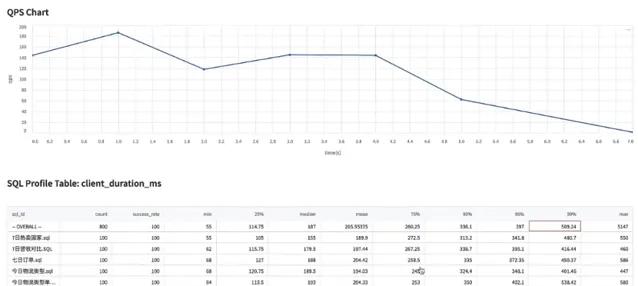
可以看到,由於並行請求觸發了計算資源的自動的橫向擴容,計算例項由1個變成4個。在這個場景,整個 Query 的延遲還是保持在比較低的水平上, P99 也沒有明顯的變化,還是能夠滿足業務SLA。
從上面的演示可以看到,單個使用者可以達到毫秒級的查詢體驗,當多並行時,仍能夠透過彈效能力,讓每一個使用者在其 BI 產品上得到相同的體驗。
總結

本次分享主要探討了如何在數據湖上更好地實作高並行、低延遲。主要包括三個關鍵點:
充分利用彈效能力提升效能、降低成本。雲器Lakehouse具備很好的分析加速引擎能夠支持多並行,同時借助雲原生的能力在橫向、縱向上的快速彈縮能力,能夠快速匹配業務的彈性要求,無需提前進行業務容量預估,就可以及時滿足業務需求。
實作湖上數據的即時更新、主動cache,保障數據新鮮度和分析效能。特別是即時數據的cache,我們透過 Preload cache 的方式能更好地破解挑戰。
借助自動化、智慧化的平台托管能力,持續最佳化分析效能。豐富的配套工具和產品化的管理能力,能夠為業務、開發和分析人員助力,同時我們也希望能夠提供更多智慧化的方式,持續地去做產品的最佳化。
問答環節
Q1:雲器支持事務嗎?
A1:不支持資料庫級別的事務,更多使用分析場景中的版本事務隔離。
Q2:查詢引擎是基於 C++ 實作的嗎?
A2:是的,我們的引擎核心分為兩部份。我們的編譯器、最佳化器這是一套。然後從執行引擎上,根據兩種不同的業務負載模式,我們實作了兩種不同的任務排程模型。所以從使用者的介面層面,我們能用一套的 SQL 語法和介面。從執行上,可以顯示地建立不同的計算資源來拉起不同的執行引擎,分別去面向批次處理、分析場景進行最佳化。
Q3:目前增量這塊只支持微批實作嗎?純流有做嗎?
A3:我們的微批可以做到一分鐘級別,已經能滿足很多場景,熟悉這個領域的話都知道,在很多場景上做到分鐘級的這種即時微批已經是非常大的挑戰了。即時的這部份也在我們的規劃中,後續會分享更多進展。關於增量計算,後續也會有單獨的專題來介紹。
Q4:跟 Spark 還有 Flink 的整合如何?
A4:跟 Spark 和Flink的整合後期會有另外的專題來介紹。雲器內部只有一個 SQL引擎,沒有 Spark 或 Flink 引擎。但是支持Spark、Flink、Presto這些引擎來存取。存取的方式不一樣,比如 Flink 存取雲器Lakehouse,更多的是透過的 Connector 方式去調我們的即時寫入的 API, 能即時地寫進來。Spark 存取雲器Lakehouse的時候,更多的是希望直讀儲存以提高吞吐,所以我們在整個的後設資料系統設計之初就考慮了開放性,提供雲器Catalog 的SDK, Spark 可以直接使用我們的 Catalog 的 SDK 包,透過雲器產品的使用者名稱和密碼授權地對接到雲器的數據,存取底層的儲存群。
END
關於雲器
雲器Lakehouse 作為面向企業的全托管一體化數據平台,只需註冊帳戶即可管理和分析數據,無需關心復雜的平台維護和管理問題。新一代 增量計算 引擎實作了批次處理、流計算和互動式分析的統一,適用於多種雲端運算環境,幫助企業簡化數據架構,消除數據冗余。
點選文末「 閱讀原文 」,前往雲器官網申請試用,了解更多產品細節!
官網:yunqi.tech
B 站:雲器科技
知乎:雲器科技
▼點選關註雲器科技公眾號,優先試用雲器Lakehouse!
往期推薦











