大家好,歡迎來到 Crossin的編程教室~
一組1000萬個0~100的整數序列,用它來生成一個新的序列,要求如果原本序列中是奇數就不變,如果是偶數就變成原來的一半。
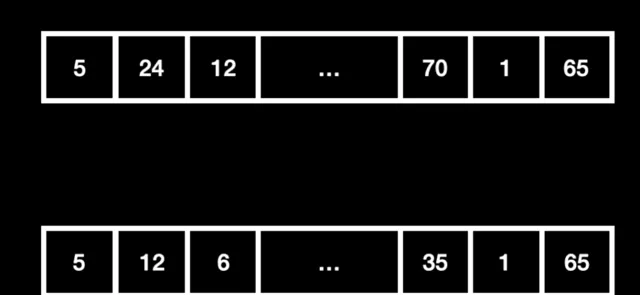
你會怎麽寫?
來看幾份參考答案:
青銅:
def for_method(data): result = []for x indata:if x % 2 == 0: result.append(x // 2)else: result.append(x)return result
(自測耗時:0.95 秒 )
新建一個空列表,for迴圈遍歷原列表,依次判斷每個元素,如果能被2整除就除以2添加進新列表,否則直接添加進新列表。
白銀:
deflc_method(data):return [x if x % 2else x // 2for x in data]
( 自測 耗時: 0.75 秒 )
透過列表解析式生成新列表,不僅程式碼更簡潔明了,耗時還變少了。
黃金:
def numpy_method(data): arr = np.array(data)return np.where(arr % 2 == 0, arr // 2, arr).tolist()
( 自測 耗時: 0.90 秒 )
用numpy的where方法生成新的陣列。看起來效率好像還不如列表解析式嘛?這是因為大部份時間都花在了列表和ndarray的轉換上。如果這組序列本身就用numpy的陣列來儲存的話:
def numpy_array_method(data):return np.where(data % 2 == 0, data// 2, data)
(自測耗時: 0 .32 秒 )
速度直接碾壓列表解析式。
王者:
@numba.jit(nopython=True)def numba_method(data): result = np.copy(data)for i in range(len(data)):if result[i] % 2 == 0: result[i] //= 2return result
(自測耗時: 0 .65 秒 )
還是用for迴圈,不過給函式加上一個裝飾器,表示用Numba JIT編譯,這個看起來平平無奇的寫法會有什麽效果呢?好像也沒有比直接用numpy快多少嘛?
別急,讓我們加大劑量,把序列長度調整到1億,優勢就體現出來了。(numba:1.21秒 vs numpy:3.04秒)
你還有其他寫法嗎?
作者:Crossin的編程教室
Crossin的新書【 碼上行動:用ChatGPT學會Python編程 】已經上市了。 本書以ChatGPT為輔助,系統全面地講解了如何掌握Python編程,適合Python零基礎入門的讀者學習。
購買後可加入讀者交流群,Crossin為你開啟陪讀模式,解答你在閱讀本書時的一切疑問。
添加微信 crossin123 ,加入編程教室共同學習 ~
感謝 轉發 和 點贊 的各位~











