「定制」这件事在我们生活中十分常见。
但大模型的定制你见过吗?🤔
文生图模型的定制化现在发展迅速,但文生视频模型的定制化还在研究中。
谷歌DeepMind团队 的最新研究—— Still-Moving 框架,实现了 T2V 模型的定制化生成!!
扫码加入AI交流群
获得更多技术支持和交流

项目简介
视频生成的定制化之所以仍然处于起步阶段,主要原因是缺乏定制化视频数据。
Still-Moving 是一个不需要定制视频数据的创新型通用框架,可以对文本生成视频模型进行定制化。
给定一个基于T2I模型构建的T2V模型, Still-Moving 可以 仅使用少量静态参考图像,来 调整任何自定义的 T2I 权重与T2V模型保持一致, 并保留 T2V 模型的运动先验 。
Demo
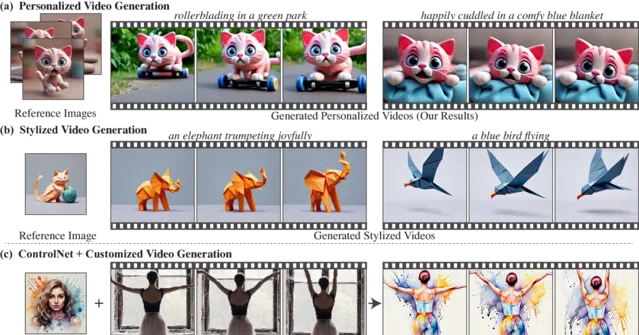
下面是通过调整个性化T2I模型来生成 个性化视频 的示例。
参考图

生成视频
参考图

生成视频
参考图

生成视频
Still-Moving还可用于基于预训练的风格化T2I模型,生成具有一致风格的视频。
下面是 风格化视频 生成的案例,这些视频遵循参考图像的风格,同时也展现了T2V模型的自然运动。
参考图

生成视频
参考图

生成视频
参考图

生成视频
项目原理
大家设想一下当我们看到一组静态图像时,肯定能够想象出这些图像中的主体在不同场景下的动态变化。👾
这种能力源于我们对物体运动、物理和动态的强烈先验认知。
所以该研究的核心问题是:是否可以使用一个学会了运动先验的生成视频模型,来实现类似的人类想象能力?🤔
Still-Moving提出了一种 无需定制视频数据 的方法,直接扩展T2I模型的定制化成果到T2V模型。
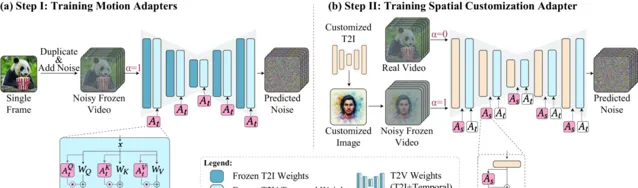
具体来说,Still-Moving通过两个步骤实现定制化:
运动适配器训练 :引入运动适配器,用于控制模型生成视频的运动量。通过在静态视频上训练这些适配器,模型学会生成静态视频。
空间适配器训练 :注入定制化的T2I权重,并训练空间适配器,这些适配器在组合了定制化图像和自然视频的数据上进行训练,从而在保持模型运动先验的同时,适应定制化的空间先验。
下面是团队展示的使用不同比例的运动适配器的效果比较。
DeepMind团队在多个任务上展示了Still-Moving框架的有效性,包括个性化生成、风格化生成和条件生成。
在所有评估场景中,Still-Moving成功地结合了定制化T2I模型的空间先验与T2V模型的运动先验,生成了高质量的视频内容。
下面将Still-Moving应用于AnimateDiff T2V模型,并将Still-Moving与简单注入进行了比较,第二行是Still-Moving的结果。
参考图

生成对比
同时团队对Still-Moving和基线方法进行了定性比较。最后一列是Still-Moving的效果展示。
参考图

生成对比
Still-Moving扩展了T2I模型的定制化成果到视频生成领域,解决了缺乏定制化视频数据的关键问题。
DeepMind团队的这一创新实现了高质量的定制化视频生成,小编期待后续团队为AI生成领域的高楼再次添砖加瓦!
🔗 项目链接 :
https://still-moving.github.io
关注「 向量光年 」公众号
加速全行业向AI的改变
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新咨询











