项目简介
ScrapeGraphAI 是一个基于Python的Web抓取库,使用大型语言模型和直接图逻辑来创建针对网站、文档和XML文件的抓取流程。用户只需指定想要抽取的信息,该库便能自动完成抓取任务。该项目强调易用性和高效性,支持通过命令行界面或代码实现灵活的数据抓取,并提供丰富的文档支持,帮助用户快速上手。
扫码加入交流群
获得更多技术支持和交流
(请注明自己的职业)

快速安装
这是 Scrapegraph-ai 的官方 PyPI 页面的参考信息
https://pypi.org/project/scrapegraphai/
pip install scrapegraphai
你还需要安装 Playwright 用于基于 JavaScript 的网页抓取:
playwright install
注意:建议在虚拟环境中安装该库,以避免与其他库冲突
DEMO
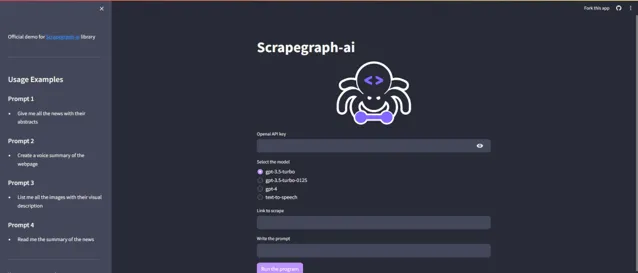
https://scrapegraph-ai-demo.streamlit.app/
使用
你可以使用 SmartScraper 类通过提示从网站中提取信息。
SmartScraper 类是一个直接图实现,使用了网页抓取流程中最常见的节点。更多信息请查看文档。
https://scrapegraph-ai.readthedocs.io/en/latest/
案例 1:使用 Ollama 提取信息记得要单独下载 Ollama 的模型!
from scrapegraphai.graphs import SmartScraperGraphgraph_config = {"llm": {"model": "ollama/mistral","temperature": 0,"format": "json", # Ollama needs the format to be specified explicitly"base_url": "http://localhost:11434", # set Ollama URL },"embeddings": {"model": "ollama/nomic-embed-text","base_url": "http://localhost:11434", # set Ollama URL }}smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles",# also accepts a string with the already downloaded HTML code source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)
案例 2:使用 Docker 提取信息
注意:在使用本地模型之前,记得创建 Docker 容器!
docker-compose up -d docker exec -it ollama ollama pull stablelm-zephyr
你可以使用 Ollama 上可用的模型或者你自己的模型,而不是使用 stablelm-zephyr。
from scrapegraphai.graphs import SmartScraperGraphgraph_config = {"llm": {"model": "ollama/mistral","temperature": 0,"format": "json", # Ollama needs the format to be specified explicitly # "model_tokens": 2000, # set context length arbitrarily },}smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles",# also accepts a string with the already downloaded HTML code source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)
案例 3:使用 OpenAI 模型提取信息
from scrapegraphai.graphs import SmartScraperGraphOPENAI_API_KEY = "YOUR_API_KEY"graph_config = {"llm": {"api_key": OPENAI_API_KEY,"model": "gpt-3.5-turbo", },}smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles",# also accepts a string with the already downloaded HTML code source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)
案例 4:使用 Groq 提取信息
from scrapegraphai.graphs import SmartScraperGraphfrom scrapegraphai.utils import prettify_exec_infogroq_key = os.getenv("GROQ_APIKEY")graph_config = {"llm": {"model": "groq/gemma-7b-it","api_key": groq_key,"temperature": 0 },"embeddings": {"model": "ollama/nomic-embed-text","temperature": 0,"base_url": "http://localhost:11434", },"headless": False}smart_scraper_graph = SmartScraperGraph( prompt="List me all the projects with their description and the author.", source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)
案例 5:使用 Azure 提取信息
from langchain_openai import AzureChatOpenAIfrom langchain_openai import AzureOpenAIEmbeddingslm_model_instance = AzureChatOpenAI( openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"], azure_deployment=os.environ["AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"])embedder_model_instance = AzureOpenAIEmbeddings( azure_deployment=os.environ["AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME"], openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],)graph_config = {"llm": {"model_instance": llm_model_instance},"embeddings": {"model_instance": embedder_model_instance}}smart_scraper_graph = SmartScraperGraph( prompt="""List me all the events, with the following fields: company_name, event_name, event_start_date, event_start_time, event_end_date, event_end_time, location, event_mode, event_category, third_party_redirect, no_of_days, time_in_hours, hosted_or_attending, refreshments_type, registration_available, registration_link""", source="https://www.hmhco.com/event", config=graph_config)
案例 6:使用 Gemini 提取信息
from scrapegraphai.graphs import SmartScraperGraphGOOGLE_APIKEY = "YOUR_API_KEY"# Define the configuration for the graphgraph_config = {"llm": {"api_key": GOOGLE_APIKEY,"model": "gemini-pro", },}# Create the SmartScraperGraph instancesmart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)
以上三个案例的输出都将是一个包含提取信息的字典,例如:
{'titles': ['Rotary Pendulum RL' ],'descriptions': ['Open Source project aimed at controlling a real life rotary pendulum using RL algorithms' ]}
项目链接
https://github.com/VinciGit00/Scrapegraph-ai
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点











