大模型的发展已经进入了万亿级参数时代。DeepMind 联合创始人穆斯塔法・苏莱曼(Mustafa Suleyman)预测,
仅在未来三年内,大模型规模以惊人的速度继续扩张,将增长 1000 倍
。
一方面,模型的参数量与其能够处理和学习的复杂性直接相关。模型容量越大,往往意味着性能越好。随着模型容量增加到数万亿个参数,大模型可以捕捉更复杂的模式,从而在自然语言处理、计算机视觉和其他任务上表现更好,具备更像人类的能力。
另一方面,随着计算能力的大幅提升,特别是 GPU 和专用 AI 芯片(如 TPU)的发展,使得训练更大规模的模型成为可能;新的模型架构和训练技术的出现,如 Transformer 架构和预训练技术,使得模型能够更有效地扩展到更大的规模。
此外,模型的大小往往被视为技术创新和研发实力的一种体现。因此,研究和商业机构之间存在一种竞争,推动着模型规模不断扩大,直到推上万亿级参数量的巅峰。
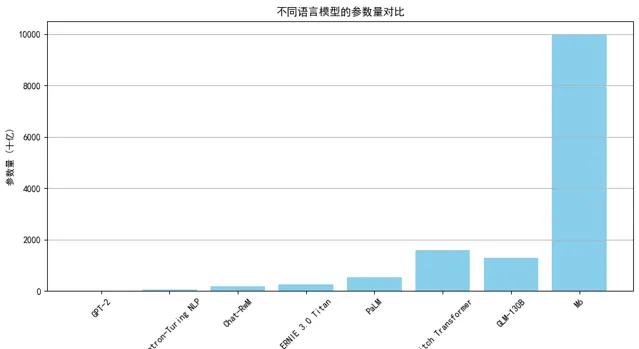
GPT-2 :2019 年发布的 GPT-2 模型拥有 15 亿参数,是当时重要的大型语言模型之一。
Megatron-Turing NLP :由微软和 NVIDIA 合作开发的 Megatron-Turing NLP 模型,是一个具有 530 亿参数的语言模型。
Chat-RwM:Salesforce 研究院发布的 Chat-RwM 模型,是一个具有 1750 亿参数的对话生成模型,专注于多轮对话场景。
ERNIE 3.0 Titan:百度与鹏城自然语言处理联合实验室发布的 ERNIE 3.0 Titan 拥有 2600 亿的参数。
PaLM :2022 年,谷歌发布的 Pathways Language Model(PaLM)模型拥有 5400 亿参数。
Switch Transformer :由谷歌发布的 Switch Transformer 模型,拥有 1.6 万亿参数,用于高效的多任务学习。
GLM-130B :智谱开源的 GLM-130B 模型,具有 1.3 万亿参数。
M6:达摩院的多模态预训练模型 M6,拥有 10 万亿参数。
然而这种大模型之间的军备竞赛,令业内十分担忧 。
参数量的增加,就一定能带来显著的性能提升吗?不一定。大模型带来的问题越来越明显:
计算资源需求巨大:训练大规模模型需要大量的计算资源,包括高性能 GPU、云计算集群等。这对于大多数企业和个人来说,成本高昂。对话式人工智能模型 Claude 背后的初创公司 Anthropic 认为,在 18 个月内,他们可以构建出比当今最大模型还要强大 10 倍的模型。但是这个 「Claude-Next」 可能需要超过 10 亿美元来训练和运行。
能源消耗:训练大模型的训练和运行都要消耗大量能源,并且产生的巨大体量的碳排放。根据 Digital Information World 发布的报告显示,OpenAI 训练 GPT-3 耗电为 1.287 吉瓦时,大约相当于 120 个美国家庭 1 年的用电量。而这仅仅是训练 AI 模型的前期电力,仅占模型实际使用时所消耗电力的 40%。2023 年 1 月,OpenAI 仅一个月已耗用可能等同 17.5 万个丹麦家庭的全年用电量。谷歌 AI 每年耗电量达 2.3 太瓦时,相当于亚特兰大所有家庭 1 年用电量。
不可解释性:由于 GPT-3、BERT 等大模型具有复杂的结构和数以亿计的参数,其内部的决策过程对于人类来说往往是黑箱式的,即难以直接理解。人们难以理解模型为何作出某个预测或生成某段文本,这在一些敏感领域中可能引发问题。
伦理和安全问题:大模型的应用涉及伦理和安全问题,例如偏见、歧视、虚假信息等。如何对万亿级的大模型进行监管和治理,这在全球都算得上是一个棘手问题。
「我们正在接近大模型规模的极限。规模越大不一定意味着模型越好,很可能只是为了追求一个数字而已。」 去年 4 月,OpenAI 的联合创始人兼 CEO Sam Altman 在麻省理工学院 「想象力行动」 活动上接受采访时表示。
他将 LLM 的规模与过去芯片速度的竞赛进行了类比,指出今天我们更关注芯片能否完成任务,而不是它们有多快。「规模不再是衡量模型质量的重要指标,未来将有更多的方式来提升模型的能力和效用。」

风向在转变,小模型正在成为 AI 界的新宠。尽管参数规模较小,却在成本、性能和实用性方面具备优势 —— 占内存小、反应速度快、可以本地化运行 。
不久前,微软研究院推出了新一代小型语言模型系列 Phi-3。虽然该模型的参数规模较小,但通过精心设计的训练数据集和优化的算法,超越了同等大小和稍大一号的模型,在各种语言、推理、编码和数学基准测试中表现优异。
苹果紧随其后,发布了 OpenELM,包含了 2.7 亿、4.5 亿、11 亿和 30 亿四个参数版本。与微软的 Phi-3 一样,OpenELM 也是一款专为终端设备而设计的小模型。
在国内,面壁智能推出了只有 20 亿参数量级的模型 MiniCPM,而其性能却超过了大参数模型 Mistral-7B,且部分超越 Llama-13B 等,能在在手机等终端上运行,甚至仅靠一块 CPU 就能运载。
小模型正在不断证明,它们可以在重点任务上与大模型相媲美,甚至将其击败 。其优势也恰好能补大模型的不足,比如:
计算效率高:小模型相对较小,可以在本地机器上运行模型,训练和推理速度更快,适用于资源有限的环境。
可解释性更好:小模型的结构相对简单,更容易理解其决策过程。
适用范围广:小模型可以应用于各种任务,包括嵌入式设备、移动应用和边缘计算。
偏见风险低:由于 SLM 在相对较小的特定领域数据集上进行训练,与 LLM 相比,偏差风险自然较低。
在大多数特定于功能的用例中,比如医疗、法律和金融等领域,小模型可能会表现更加出色。利用这些领域高度专业化的知识训练小模型,并对其进行微调,可以作为高度监管和专业化行业中特定领域用例的智能代理。
小模型在边缘设备上有着广泛的应用,如智能手机、物联网设备和嵌入式系统,这些边缘设备通常具有有限的计算能力和存储空间,它们无法有效地运行大型语言模型。小模型更接近用户,更个性化,更适合解决实际问题。
一个观点认为,大模型和小模型都将在未来的 AI 市场中占有一席之地 。具有数万亿参数的大模型将推动通用智能的新领域,具有数百万到数十亿个参数的专用小模型将处理大多数公司的重点任务。
因此,对于诸多垂直领域的企业而言,或许应该更多地建立自己能够负担得起的 「小模型」,通过具备学习能力的 AI 来加速小体量应用场景的体验更新。
与其将大模型和小型模之争称为 「模型之战」,不如将二者视为互补并满足不同需求 。学会驾驭这种二分法,或许才能未来几年把握住 AI 大势。
如果你还想更进一步了解大模型和小模型如何通过技术手段实现融合,小模型在实际应用中有何成功案例,如何高效、可靠地管理和运维大语言模型,AI 与数据库等领域的结合会带来怎样的变革,多模态大模型有哪些应用与实践,技术极客在大 AI 浪潮中有什么创新实践与经验,以及未来可能出现的新技术或理论突破等话题,敬请关注 2024 亚太人工智能与机器人产业峰会暨 GOTC 全球开源技术峰会 。
本次大会将通过 「LLMOps 最佳实践」「开源数据库与 AI 协同创新」「多模态大模型的应用与实践」「硬核 AI 技术创新与实践」「AI WorkShop,大模型开发者实操营」 等多个论坛及活动,来探索 AI 大模型的最新研究进展及其在实际应用中的挑战与机遇。
报名 GOTC 2024:
扫码或长按识别二维码
2024 亚太人工智能与机器人产业峰会暨 GOTC 全球开源技术峰会
由中国人工智能学会与开源中国联合举办,将于
7 月 13-14 日
在
杭州
隆重举行。
本次峰会将汇聚全球顶尖的专家、学者、企业领袖及开源技术代表,深入探讨机器人技术、软件开发、开源技术和 AI 大模型等前沿领域。
会议将重点展示机器人在制造、医疗、物流和服务等行业的最新应用,探讨智能算法和自主学习能力如何提升机器人性能,并分享开源技术在推动技术创新与协作中的关键作用。
此外,峰会还将关注 AI 大模型的最新研究进展及其在实际应用中的挑战与机遇。
通过主题演讲、圆桌讨论、技术展示和互动工作坊,与会者将有机会交流实践经验,探索前沿技术,促进跨领域合作,共同推动人工智能与机器人技术的发展。

Reference
https://my.oschina.net/u/3859945/blog/11213589
END
热门文章
-
-
-
-
-












