引言:在 Redis 中,并没有使用 C 标准库提供提供的字符串,而是实现了一种动态字符串,即 SDS (Simple Dynamic String),然后通过这种数据结构来表示字符串,面试中除了基本数据类型让你去讲解,此外还会讲1-2种数据结构的底层原理和优势。
题目
redis 的字符串为什么要升级 SDS,而不用 C 语言字符串?
推荐解析
C 语言字符串的缺陷
首先最直接的,为什么不适用一个东西,其最根本的原因就是他有不好的地方, C 语言的字符串其实本质上就是 char* 的字符数组,其本身是存在一定缺陷的,首先我们来盘点一下其缺陷。
1)C 语言字符数组的结尾位置就用 「\0」 表示,意思是指字符串的结束
2)C 语言字符数组获取长度只能通过遍历获得,时间复杂度是 O(n)
3)字符串操作函数不高效且不安全,比如缓冲区溢出,其可能导致程序异常终止
针对以上问题,C 语言在其基础上进行了一定的改进,接下里我们来注意进行分析。
SDS 结构

如下图所示,SDS 数据结构分为四个部分的内容,如下图所示
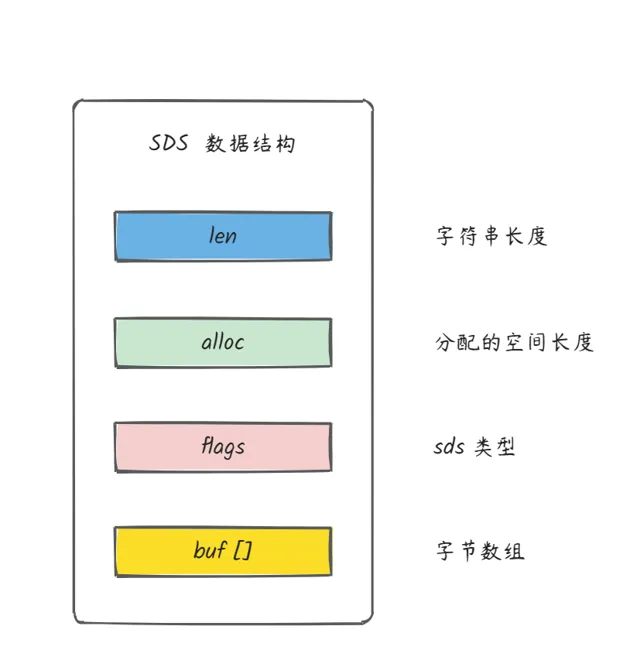
1)len (长度):记录了 SDS 字符串数组的长度,当需要获取字符串长度的时候,只需要返回这个成员变量的值就可以了,时间复杂度是O(1)
2)alloc(分配空间长度):这个字段的主要作用是指分配给字符数组的存储的空间大小,当需要计算剩余空间大小的时候,只需要 alloc - len 就可以直接进行计算,然后判断空间大小是否符合修改需求,如果不满足需求的话,就执行相应的修改操作,这样的话就可以很好地解决我们上面所说的缓冲区溢出问题。
3)flags(表示 SDS 的类型):一共设计了五种类型的 SDS,分别是 sdshdr 5、sdshdr 8、sdshdr 16、sdshdr 32、sdshdr 64(这个的记忆页很简单,就是 32 开始,128,即 2 的多少次方去记忆就可以了),这个类型的主要作用就是灵活保存不同大小的字符串,从而有效节省内存空间。
4)buf(存储数据的字符数组):主要起到保存数据的作用,如字符串、二进制数据(二进制安全就是一个重要原因)等
然后在分析完 SDS 的结构之后,接下来我们来分析原因,我们可以发现,SDS 相对于 C 语言原生的字符串,其多了几个字段,即 len、alloc、flags,这几个字段帮助 SDS 解决了 C 语言字符串的问题:
1) 长度计算
首先是 len,他记录了 SDS 的字符串长度,因此当你需要获取字符串长度的时候,你只需要返回 len 的值就可以了,不需要再去遍历字符串,这样操作的时间复杂度就降低了许多,直接从 O(n) 变成了 O (1)
2) 二进制安全
第二个点在于存储的字符数组,SDS 中进行了改进,SDS 中不在需要 \0 来判断字符串是否结束,这就是我们上面所说的 Redis 字符串中的 buf 数组可以存储任何的二进制数据,因此存储二进制数据的时候便不会发生字符截断的问题,避免了由于特殊字符引发的异常,不过需要注意一个点,Redis 为了兼容 C 标准库的一些操作, Redis 仍然为末尾的 \0 预留了内存空间
3) 修改操作高效
其次就是 alloc 字段了,alloc 字段用来记录字符串预分配的内存大小,当发生字符串修改的时候,通过 allloc - len 判断当前空间是否足够,如果不足够的话就进行扩容。
然后这里放一段 sds 扩容的代码,用于帮助理解
hisds hi_sdsMakeRoomFor(hisds s, size_t addlen)
{
... ...
// avail 值就是 allloc-len 的值
// 如果值的大小即剩余空间大于增加的字符串长度,则表示空间足够,不需要进行扩容,直接返回就可以
if (avail >= addlen)
return s;
//获取当前 s 的长度大小
len = hi_sdslen(s);
sh = (char *)s - hi_sdsHdrSize(oldtype);
//求扩容以后 s 需要的最小长度
newlen = (len + addlen);
//根据获取到的新长度,为 s 分配新空间所需要的内存空间大小
if (newlen < HI_SDS_MAX_PREALLOC)
//新长度 < HI_SDS_MAX_PREALLOC,这里 HI_SDS_MAX_PREALLOC 的值 为 1 MB
//表示分配所需空间 2 倍的空间
newlen *= 2;
else
//不满足条件的话,分配长度为目前长度 + 1MB 的空间
newlen += HI_SDS_MAX_PREALLOC;
...
}
我们可以发现,当 sds 扩容的时候,其是根据 sds 的长度进行判断的,其判断的值就是所需要的 sds 的长度是否超过 1 MB
如果需要的 sds 长度小于 1MB 的话,其扩容规则就是翻倍扩容,即 2 倍的新长度
如果需要的 sds 长度大于等于 1 MB 的话,其扩容规则就是 newlen + 1 MB
在扩容之前,SDS 会有限检查使用空间够不够使用,如果不够使用的话,则会进行扩容处理,即分配额外的未使用空间,这样可以有效地减少内存分配的次数,并且解决了缓冲区溢出的问题。
4) 按需使用,节省内存
最后一个要介绍的点就是 flag 字段,和那个字段主要分为 5 种类型,即 sdshdr5、sdshdr8、sdshdr16、sdshdr32 以及 sdshdr64 五种字符串,他们分别对应存储长度小于等于 2 的 5/8/16/32/64 次方字节的字符串。
通过使用不同存储类型的结构题,灵活保存不同大小的字符串,从而节省内存空间,此外,Redis SDS 底层还使用了消除内存对齐的方式进行内存的优化,从而保证所有的成员尽可能在内存中相邻,从而保证按照实际大小分配内存,节约内存的使用。
源码版本迭代
Redis 3.2 版本以前的源码
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
Redis 3.2 版本以后的源码
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
其他补充
鱼聪明 AI 的回答:
鱼聪明 AI 地址:https://www.yucongming.com/

Redis 字符串:
优点:
分布式存储: Redis 是一种分布式缓存系统,可以在多台服务器上进行数据存储和访问,提高了系统的可扩展性和容错性。
支持持久化: Redis 支持将数据持久化到磁盘,保证数据不会因为服务器重启或断电而丢失。
数据结构丰富: Redis 的字符串不仅仅支持简单的键值对,还支持列表、哈希、集合等多种数据结构,提供了更多的灵活性和功能。
高性能: Redis 是基于内存的数据库,读写速度非常快,适用于高并发场景。
缺点:
内存消耗较高: Redis 数据存储在内存中,如果数据量较大,可能会消耗大量的内存资源。
单个值大小限制: Redis 单个字符串值的大小受到内存限制,如果需要存储大对象,可能会有限制。
学习成本: Redis 是一种新的数据存储技术,需要学习其特有的命令和使用方式。
普通 C 语言字符串:
优点:
简单易用: C 语言中的字符串是一种基本数据类型,使用起来非常简单和灵活。
低资源消耗: 普通 C 语言字符串通常存储在栈上或堆上,内存消耗较低。
无需学习成本: 对于熟悉 C 语言的开发者来说,使用普通的 C 语言字符串无需学习新的技术和命令。
缺点:
不支持分布式: 普通 C 语言字符串只能存储在单个程序的内存空间中,无法实现分布式存储和访问。
不支持持久化: C 语言字符串通常存储在内存中,程序结束或崩溃时数据会丢失。
功能受限: 普通 C 语言字符串功能相对简单,不支持丰富的数据结构和高级功能。
欢迎交流
在阅读完本文后,你应该了解了 C 语言和 SDS 动态字符串的优缺点,最好是对源码有过分析,在文末将提出三个问题,去检验你自己的学习成果,欢迎小伙伴在评论区留言!

1)SDS 中的 len 和 alloc 字段分别有什么作用?为什么 len 的存在可以提高字符串长度获取的效率?
2)在 SDS 中,为什么 buf 数组可以存储任何的二进制数据?这如何避免了字符截断的问题?
3)文章中提到了 Redis 为了兼容 C 标准库的一些操作而预留了末尾的 \0,这个操作有什么具体的目的或好处?
点燃求职热情!每周持续更新,海量面试题和大厂面经等你挑战!赶紧关注面试鸭公众号,轻松备战春招和暑期实习!
往期推荐











