Big Whale
巨鲸任务调度平台为美柚大数据研发的分布式计算任务调度系统,提供Spark、Flink等批处理任务的DAG调度和流处理任务的运行管理和状态监控,并具有Yarn应用管理、重复应用检测、大内存应用检测等功能。服务基于Spring Boot 2.0开发,打包后即可运行。
概述
1.架构图
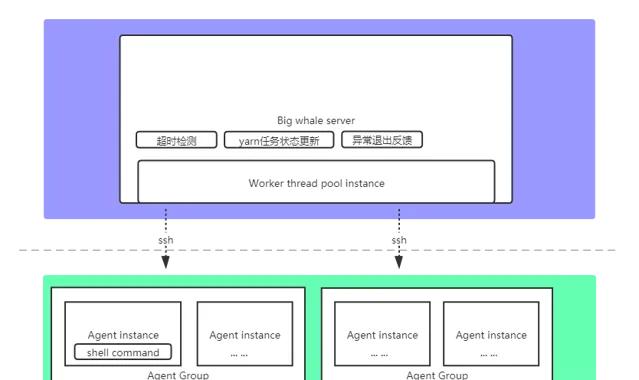
2.特性
基于SSH的脚本执行机制,部署简单快捷,仅需单个服务
基于Yarn Rest Api的任务状态同步机制,对Spark、Flink无版本限制
支持失败重试
支持任务依赖
支持复杂任务编排(DAG)
支持流处理任务运行管理和监控
支持Yarn应用管理
部署
1.准备
Java 1.8+
Mysql 5.1.0+
下载项目或git clone项目
为解决 github README.md 图片无法正常加载的问题,请在hosts文件中加入相关域名解析规则,参考: hosts
2.安装
创建数据库:big-whale
运行数据库脚本: big-whale.sql
根据Spring Boot环境,配置相关数据库账号密码,以及SMTP信息
配置: big-whale.properties
ssh.user: 拥有脚本执行权限的ssh远程登录用户名(平台会将该用户作为统一的脚本执行用户)
ssh.password: ssh远程登录用户密码
dingding.enabled: 是否开启钉钉告警
dingding.watcher-token: 钉钉公共群机器人Token
yarn.app-memory-threshold: Yarn应用内存上限(单位:MB),-1禁用检测
yarn.app-white-list: Yarn应用白名单列表(列表中的应用申请的内存超过上限,不会进行告警)
配置项说明
修改:$FLINK_HOME/bin/flink,参考: flink (因flink提交任务时只能读取本地jar包,故需要在执行提交命令时从hdfs上下载jar包并替换脚本中的jar包路径参数)
打包:mvn clean package
3.启动
检查端口17070是否被占用,被占用的话,关闭占用的进程或修改项目端口号配置重新打包
拷贝target目录下的big-whale.jar,执行命令:java -jar big-whale.jar
4.初始配置
打开:
http://localhost:17070
输入账号admin,密码admin
点击:权限管理->用户管理,修改当前账号的邮箱为合法且存在的邮箱地址,否则会导致邮件发送失败
添加集群
集群管理->集群管理->新增
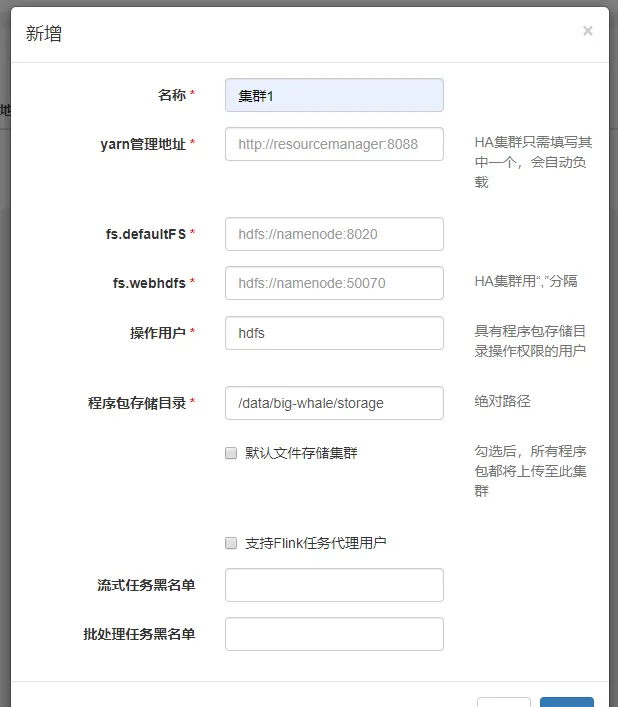
「yarn管理地址」为Yarn ResourceManager的WEB UI地址
「程序包存储目录」为程序包上传至hdfs集群时的存储路径,如:/data/big-whale/storage
「支持Flink任务代理用户」「流处理任务黑名单」和「批处理任务黑名单」为内部定制的任务分配规则,勿填
添加集群用户
集群管理->集群用户->新增
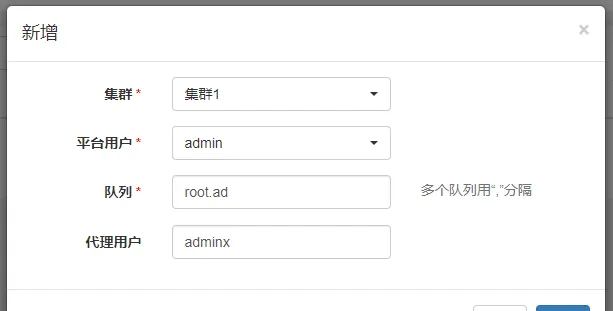
该配置的语义为:平台用户在所选集群下可以使用的Yarn资源队列(--queue)和代理用户(--proxy-user)
添加代理
集群管理->代理管理->新增
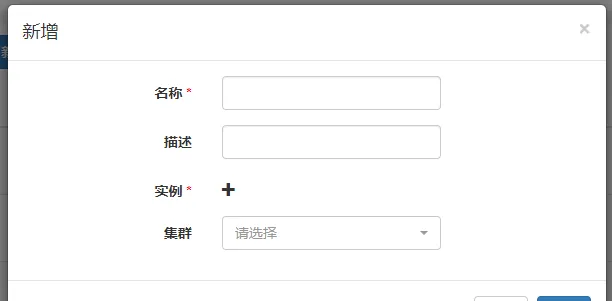
可添加多个实例(仅支持IP地址,可指定端口号,默认为22),执行脚本的时候会随机选择一个实例执行,在实例不可达的情况下,会继续随机选择下一个实例,在实例均不可达时执行失败
选择集群后,会作为该集群下提交Spark或Flink任务的代理之一
添加计算框架版本
集群管理->版本管理->新增
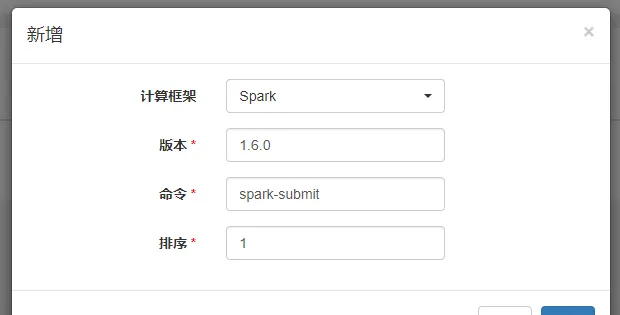
同一集群下不同版本的Spark或Flink任务的提交命令可能有所不同,如Spark 1.6.0版本的提交命令为spark-submit,Spark 2.1.0版本的提交命令为spark2-submit
使用
1.离线调度
1.1 新增
目前支持「Shell」、「Spark Batch」和「Flink Batch」三种类型的批处理任务
通过拖拽左侧工具栏相应的批处理任务图标,可添加相应的DAG节点
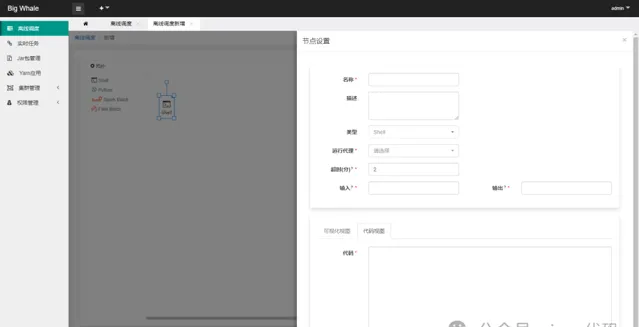
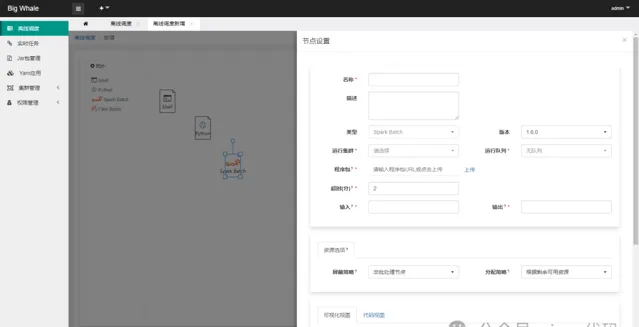
支持时间参数
${now} ${now - 1d} ${now - 1h@yyyyMMddHHmmss}
等(d天、h时、m分、s秒、@yyyyMMddHHmmss为格式化参数)
非「Shell」类型的批处理任务应上传与之处理类型相对应的程序包,此处为Spark批处理任务打成的jar包
「资源选项」可不填
代码有两种编辑模式,「可视化视图」和「代码视图」,可互相切换
点击「测试」可测试当前节点是否正确配置并可以正常运行
为防止平台线程被大量占用,平台提交Saprk或Flink任务的时候都会强制以「后台」的方式执行,对应spark配置:--conf spark.yarn.submit.waitAppCompletion=false,flink配置:-d,但是基于后台「作业状态更新任务」的回调,在实现DAG执行引擎时可以确保当前节点所提交的任务运行完成后再执行下一个节点的任务
DAG节点支持失败重试
将节点按照一定的顺序连接起来可以构建一个完整的DAG
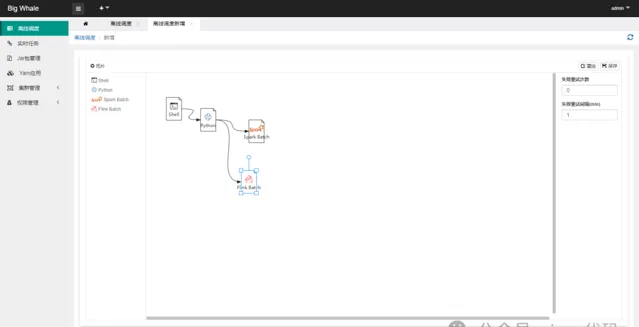
DAG构建完成后,点击「保存」,完成调度设置
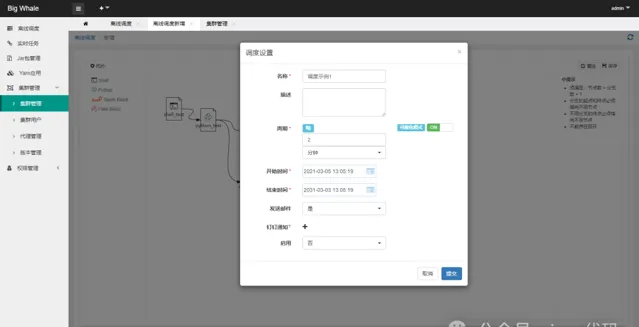
1.2 操作
打开离线调度列表
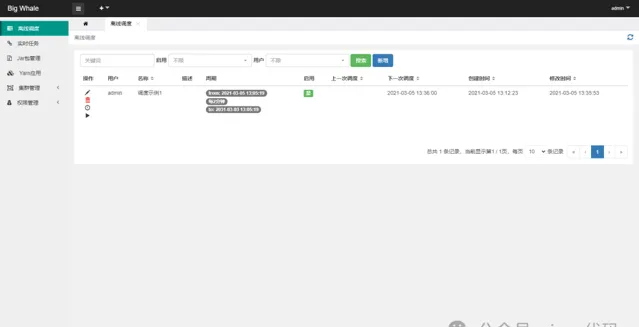
点击左侧操作栏「调度实例」可查看调度实例列表、运行状态和节点启动日志
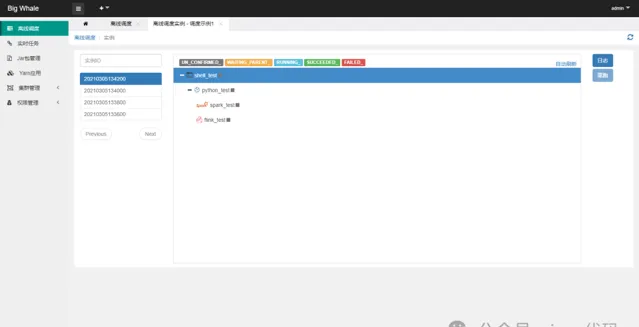
点击左侧操作栏「手动执行」可触发调度执行
2.实时任务
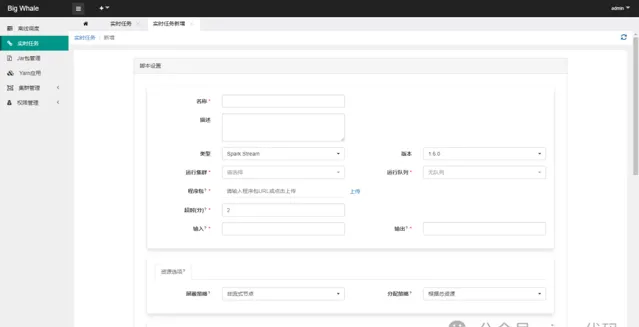
2.1 新增
目前支持「Spark Stream」和「Flink Stream」两种类型的流处理任务
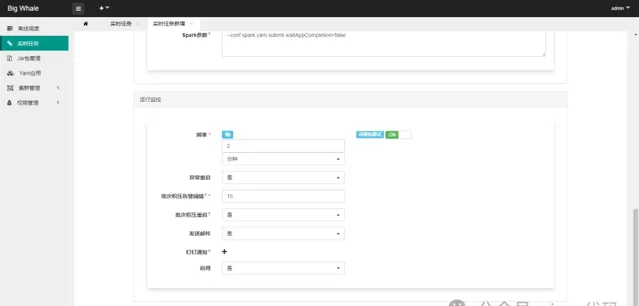
启用监控可以对任务进行状态监控,包括异常重启、批次积压告警等
2.2 操作
打开实时任务列表
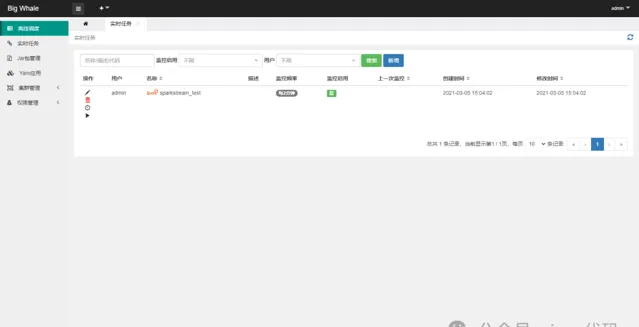
点击左侧操作栏「日志」可查看任务启动日志
点击左侧操作栏「执行」可触发任务启动
3.任务告警
正确配置邮件或钉钉告警后在任务运行异常时会发送相应的告警邮件或通知,以便及时进行相应的处理
<巨鲸任务告警>
代理: agent1
类型: 脚本执行失败
用户: admin
任务: 调度示例1 - shell_test
时间: 2021-03-05 15:18:23
<巨鲸任务告警>
集群: 集群1
类型: spark离线任务异常(FAILED)
用户: admin
任务: 调度示例1 - spark_test
时间: 2021-03-05 15:28:33
<巨鲸任务告警>
集群: 集群1
类型: spark实时任务批次积压,已重启
用户: admin
任务: sparkstream_test
时间: 2021-03-05 15:30:41
除上述告警信息外还有其他告警信息此处不一一列举
Change log
v1.1开始支持DAG
v1.2开始支持DAG节点失败重试
v1.3调度引擎进行重构升级,不支持从旧版本升级上来,原有旧版本的任务请手动进行迁移,离线调度移除「Python」类型脚本支持
项目地址:
https://gitee.com/meetyoucrop/big-whale.git











