从2月份OpenAI第一次发出Sora的视频,到现在已经10个月了,Sora终于上线。
但是,Sora经历了这么久的沉淀,效果也不能说是完美。
3月份北大团队提出要复刻Sora,启动了一个叫Open-Sora的计划。
在当时还觉得就是他们团队随便玩玩。
但是没想到, 他们坚持了下来,而且真的拿出成果给大家看了。

从3月份到现在,一直在不断地迭代更新。
总有一天,开源跟闭源的差距会越来越小。
当前版本我认为,已经算是开源里不错的AI项目了,就这个更新速度来看的话,即将到来的版本可能还会有惊喜。
今天给大家介绍的是1.3版本。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

DEMO
官方给了一段黑神话悟空的创意视频DEMO,用的是图生视频功能。
项目亮点
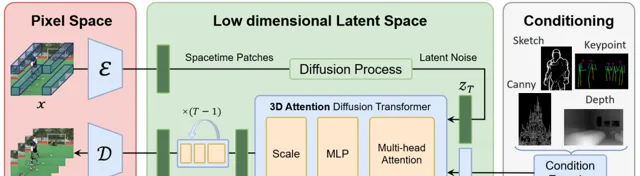
1、高性能 CausalVideoVAE,训练成本低
高压缩比,能将视频压缩至原来的 1/256(4×8×8),在保证优秀性能的同时,大大降低了训练成本。
Causal 卷积支持图像和视频的同时推理,且仅需 1 个节点即可完成训练。
2、基于 3D 注意力的视频扩散模型,时空特征联合学习
采用全新的稀疏注意力架构,替代了传统的 2+1D 模型。
3D 注意力能够更好地捕捉空间和时间的联合特征,提升了模型对时空特性的理解能力。
技术特点
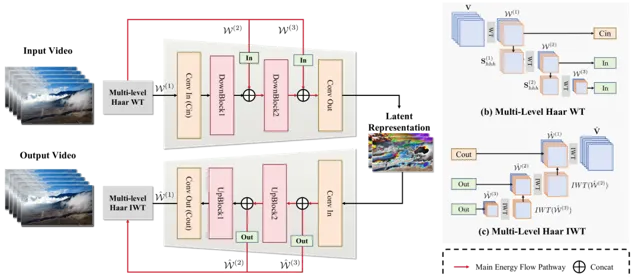
1.多组件架构:
Wavelet-Flow Variational Autoencoder (WF-VAE):通过多级小波变换在频率域获取多尺度特征,并将其注入到卷积网络中,以减少内存使用并提高训练速度。
Joint Image-Video Skiparse Denoiser:将2+1D视频生成去噪器改为3D全注意力结构,增强了模型对世界的理解能力,包括物体运动、相机移动、物理和人类行为。

Condition Controllers:设计了帧级图像条件控制器,以支持包括图像到视频、视频转换和视频延续在内的多种任务。
2.高效训练和推理策略:
Min-Max Token Strategy:通过聚合不同分辨率和时长的数据,实现高效的NPU/GPU计算,并最大化数据的有效使用。
Adaptive Gradient Clipping Strategy:提出自适应梯度裁剪策略,基于梯度范数检测异常数据,防止异常值扭曲模型的梯度方向。
Prompt Refinement Strategy:开发了提示细化器,使模型能够合理扩展输入提示,同时遵循语义,增强视频运动的稳定性并丰富细节。
3.多维数据管理流程:
Multi-dimensional Data Processor:包括检测跳跃剪辑、剪辑视频、过滤快慢动作、裁剪边缘字幕、过滤审美分数、评估视频技术质量以及注释字幕。
LPIPS-Based Jump Cuts Detection:基于学习感知图像补丁相似性(LPIPS)实现视频剪辑检测方法,防止快速运动镜头的错误分割。
4.条件注入模型: 包括深度图、姿态图、草图、文本等控制条件,实现精确的单帧操作。
5.视频生成模型的框架: 能够处理包括文本提示、多图像和结构控制信号(如边缘检测、深度、草图等)在内的多种条件查询。
6.Skiparse Attention: 提出了一种新的稀疏注意力机制,减少了计算复杂度,同时保持了对物理世界的复杂交互的建模能力。

7.结构条件控制器: 提出了一种新的结构条件控制器,以高效地将结构信号(如Canny边缘、深度图、草图)集成到基础模型中,实现可控生成。

项目链接
https://github.com/PKU-YuanGroup/Open-Sora-Plan
论文链接
https://arxiv.org/abs/2412.00131
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新资讯
关注「 向量光年 」公众号
加速全行业向AI转变











