点击关注公众号,Java干货 及时送达 👇

测试环境:
MySQL版本:8.0
数据库表:T (主键id,唯一索引c,普通字段d)

如果你的业务设计依赖于自增主键的连续性,这个设计假设自增主键是连续的。但实际上,这样的假设是错的,因为自增主键不能保证连续递增。
一、自增值的属性特征:
1. 自增主键值是存储在哪的?
MySQL5.7版本
在 MySQL 5.7 及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值
max(id)
,然后将
max(id)+1
作为这个表当前的自增值。
MySQL8.0之后版本
在 MySQL 8.0 版本,将自增值的变更记录在了
redo log
中,重启的时候依靠
redo log
恢复重启之前的值。
可以通过看表详情查看当前自增值,以及查看表参数详情
AUTO_INCREMENT
值(
AUTO_INCREMENT
就是当前数据表的自增值)
2. 自增主键值的修改机制?
在表t中,我定义了主键id为自增值,在插入一行数据的时候,自增值的行为如下:
如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的
AUTO_INCREMENT值填到自增字段;如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。
根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设,某次要插入的值是 X,当前的自增值是 Y。
如果 X<Y,那么这个表的自增值不变;
如果 X≥Y,就需要把当前自增值修改为新的自增值。
二、新增语句自增主键是如何变化的:
我们执行以下SQL语句,来观察自增主键是如何进行变化的
insertinto t values(null, 1, 1);
流程图如下所示
流程步骤:
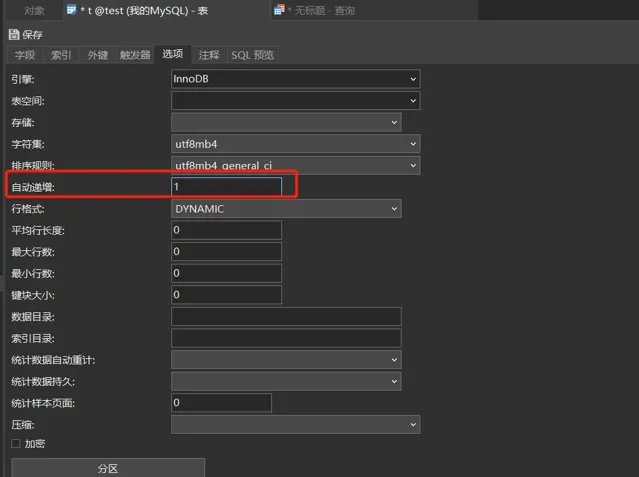
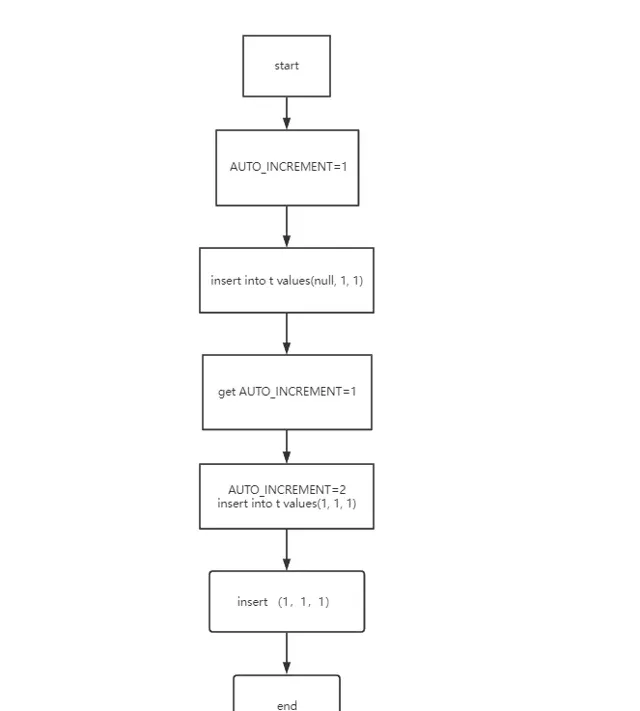
AUTO_INCREMENT=1 (表示下一次插入数据时,如果需要自动生成自增值,会生成 id=1。)
insert into t values(null, 1, 1) (执行器调用 InnoDB 引擎接口写入一行,传入的这一行的值是 (0,1,1))
get AUTO_INCREMENT=1 (InnoDB 发现用户没有指定自增 id 的值,获取表 t 当前的自增值 1 )
AUTO_INCREMENT=2 insert into t values(1, 1, 1) (将传入的行的值改成 (1,1,1),并把自增值改为2)
insert (1,1,1) 执行插入操作,至此流程结束
大家可以发现,在这个流程当中是先进行自增值的+1,在进行新增语句的执行的。大家可以发现这个操作并没有进行原子操作,如果SQL语句执行失败,那么自增是不是就不会连续了呢?
三、自增主键值不连续情况:(唯一主键冲突)
当我执行以下SQL语句时
insertinto t values(null, 1, 1);
第一次我们可以进行新增成功,根据自增值的修改机制。如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的
AUTO_INCREMENT
值填到自增字段;
当我们第二次在执行以下SQL语句时,就会出现错误。因为我们表中c字段是唯一索引,会出现
Duplicate key error
错误导致新增失败。
例如:
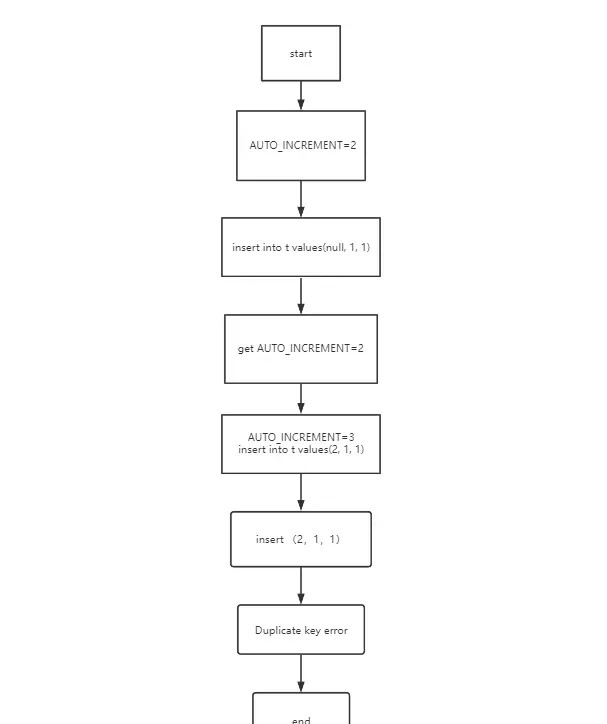
AUTO_INCREMENT=2 (表示下一次插入数据时,如果需要自动生成自增值,会生成 id=2。)
insert into t values(null, 1, 1) (执行器调用 InnoDB 引擎接口写入一行,传入的这一行的值是 (0,1,1))
get AUTO_INCREMENT=2 (InnoDB 发现用户没有指定自增 id 的值,获取表 t 当前的自增值 2 )
AUTO_INCREMENT=3 insert into t values(2, 1, 1) (将传入的行的值改成 (2,1,1),并把自增值改为3)
insert (2,1,1)
执行插入操作,由于已经存在 c=1 的记录,所以报
Duplicate key error
,语句返回。
可以看到,这个表的自增值改成 3,是在真正执行插入数据的操作之前。这个语句真正执行的时候,因为碰到唯一键 c 冲突,所以 id=2 这一行并没有插入成功,但也没有将自增值再改回去。所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。也就是说,出现了自增主键不连续的情况。
四、自增主键值不连续情况:(事务回滚)
其实事务回滚原理也和上面一样,都是因为异常导致新增失败,但是自增值没有进行回退。
五、自增主键值不连续情况:(批量插入)
批量插入数据的语句,MySQL 有一个批量申请自增 id 的策略:
语句执行过程中,第一次申请自增 id,会分配 1 个;
1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
2 个用完以后,还是这个语句, 第三次申请自增 id,会分配 4 个;
依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
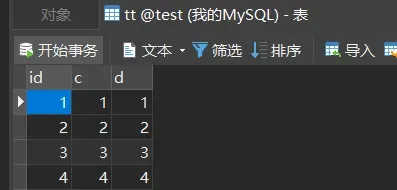
执行以下SQL语句(在表t中先新增了4条数据,在创建表tt把表t数据进行批量新增)
insertinto t values(null, 1,1);
insertinto t values(null, 2,2);
insertinto t values(null, 3,3);
insertinto t values(null, 4,4);
createtable tt like t;
insertinto tt(c,d) select c,d from t;
insertinto tt values(null, 5,5);
第一次申请到了 id=1,第二次被分配了 id=2 和 id=3, 第三次被分配到 id=4 到 id=7。当我们再执行
insert into t2 values(null, 5,5)
,实际上插入的数据就是(8,5,5),出现了自增主键不连续的情况。
六、自增主键值的优化
1.什么是自增锁
自增锁是一种比拟非凡的表级锁。并且在事务向蕴含了
AUTO_INCREMENT
列的表中新增数据时就会去持有自增锁,假如事务 A 正在做这个操作,如果另一个事务 B 尝试执行 INSERT语句,事务 B 会被阻塞住,直到事务 A 开释自增锁。
2.自增锁有哪些优化
在 MySQL 5.0 版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等语句执行结束以后才释放。显然,这样设计会影响并发度。在MySQL 5.1.22 版本引入了一个新策略,新增参数
innodb_autoinc_lock_mode
,默认值是 1。
传统模式(Traditional)
这个参数的值被设置为 0 时,表示采用之前 MySQL 5.0 版本的策略,即语句执行结束后才释放锁;
传统模式他可以保证数据一致性,但是如果有多个事务并发的执行 INSERT 操作,
AUTO-INC
的存在会使得 MySQL 的性能略有降落,因为同时只能执行一条 INSERT 语句。
间断模式(Consecutive)
这个参数的值被设置为 1 时:普通 insert 语句,自增锁在申请之后就马上释放;类似
insert … select
这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
间断模式他可以保证数据一致性,但是如果有多个事务并发的执行 INSERT 批量操作时,就会进行锁等待状态。如果我们业务插入数据量很大时,这个时候MySQL的性能就会大大下降。
穿插模式(Interleaved)
这个参数的值被设置为 2 时,所有的申请自增主键的动作都是申请后就释放锁。
穿插模式他没有进行任何的上锁设置。在一定情况下是保证了MySQL的性能,但是他无法保证数据的一致性。如果我们在穿插模式下进行主从复制时,如果你的binlog格式不是row格式,主从复制就会出现不一致。
七、MySQL8.0做了哪些优化
在MySQL8.0之后版本,已经默认设置为
innodb_autoinc_lock_mode=2
,
binlog_format=row.
。这样更有利与我们在
insert … select
这种批量插入数据的场景时,既能提升并发性,又不会出现数据一致性问题。
作者:又欠
来源:blog.csdn.net/qq_48157004/article/
details/128356734
END
看完本文有收获?请转发分享给更多人
关注「Java编程鸭」,提升Java技能
关注Java编程鸭微信公众号,后台回复:码农大礼包可以获取最新整理的技术资料一份。涵盖Java 框架学习、架构师学习等!
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)











