一、存储高可用
对于需要存储数据的系统来说,整个系统的高可用设计关键点和难点就在于「存储高可用」,存储与计算相比,有一个本质上的区别:将数据从一台机器同步到另一台机器,需要经过线路进行传输。传输的速度,同一机房能够做到毫秒级,分布在不同地方的机房,传输耗时需要几十甚至上百毫秒。
虽然毫秒级对人来说几乎没有什么感觉,但对于要求高可用的系统来说,就是本质上的区别。
以最经典的银行储蓄业务为例,假设用户的数据存在北京机房,用户存了1万块钱,然后它查询的时候被路由到了上海机房,此时用户肯定后背一凉,马上怀疑自己的钱被盗了,然后赶紧打客户电话投诉,甚至打110报警,即使最后发现只是因为传输延迟导致的问题,用户的体验也是极差的。
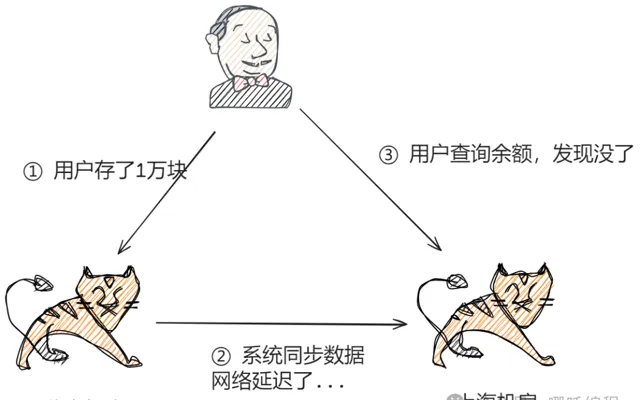
除了物理上的传输速度限制,传输线路本身也存在可用性问题,传输线路可能中断、可能拥塞、可能异常,并且传输线路的故障时间一般都特别长,短的十几分钟,长的几个小时。
例如,2015年支付宝因为光缆被挖断,业务影响超过4个小时,2016年中美海底光缆中断3小时。
在传输线路中断的情况下,就意味着存储无法进行同步,在这段时间内整个系统的数据是不一致的。
因此,存储高可用的难点不在于如何备份数据,而在于如何减少或规避数据不一致对业务造成的影响。
分布式领域有一个著名的CAP定理,从理论上论证了存储高可用的复杂度。存储高可用不可能同时满足「一致性、可用性、分区容错性」,最多满足其中2个,这就要求我们在做架构设计的时候结合业务进行取舍了。
二、读写分离
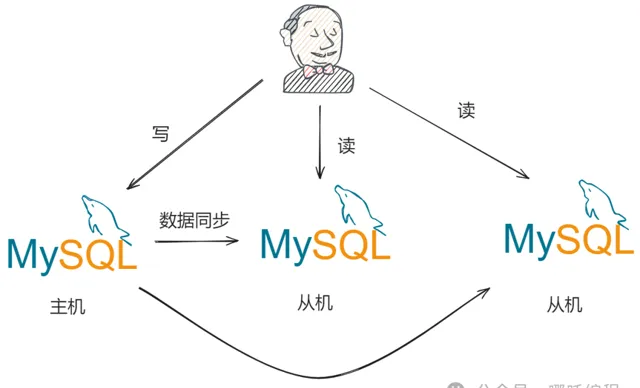
读写分离的基本实现原理:
数据库服务器搭建主从集群,一主二从
数据库主机负责写操作,从机负责读操作
数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据
业务服务器将写操作发给数据库主机,将读操作发给数据库从机
读写分离的实现逻辑并不复杂,但在实际应用过程中需要应对复制延迟带来的复杂性。
以MySQL为例,主从复制延迟可能达到1S,如果有大量数据同步,延迟1分钟也是有可能的。
主从复制延迟会带来一个问题,如果业务服务器将数据写入到数据库主服务器后立刻(1S)内进行读取,此时读操作访问的是从机,从机还没有将数据复制过来,此时用户读取的就不是最新数据,业务上可能会存在问题。
例如,用户刚注册完后立刻登录,业务服务器会提示「你还没有注册」,而用户刚才已经注册成功了。
三、解决主从复制延迟问题的几种方案
1、写操作后的读操作指定发给数据库主服务器
2、读从机失败后再读一次主机
这就是大家常说的二次读取,二次读取和业务无绑定,只需要对底层数据库访问的API进行封装即可,实现代价较小,不足之处在于如果有很多二次读取,将大大增加主机的读操作压力。
3、关键业务读写操作全部指向主机,非关键业务采用读写分离
对于不要求实时性的操作,可以通过异步处理,将一些耗时的操作延后执行。
4、压缩与批量传输
通过开启Binlog压缩功能,减少传输数据量,降低网络负担。
在可能的情况下,批量传输数据,而不是逐条记录传输,以提高传输效率。
5、优化从库的查询性能
在从库上创建合理的索引结构,以减少查询的响应时间。
6、优化网络延迟
确保主从数据库之间的网络带宽充足,并且网络延迟尽可能低。可以通过提高带宽、优化网络拓扑结构,或者使用专线等方式减少延迟。
使用网络监控工具监控网络质量,及时发现并解决网络异常问题。
7、调整复制参数
使用半同步复制(Semi-Synchronous Replication)替代完全同步复制,以减少主库等待从库确认的时间。
MySQL 5.6及以上版本支持多线程复制,可以通过增加slave_parallel_workers的值来启用多线程复制,从而加速从库的并发执行。
增加sync_binlog与innodb_flush_log_at_trx_commit的值:这些参数影响主库的Binlog刷新频率,适当调整可以减少延迟。
8、监控与报警机制
通过SHOW SLAVE STATUS命令监控从库的复制延迟情况,并设定报警机制,及时处理复制延迟问题。
配置MySQL的自动故障转移(Failover)机制,在主库出现问题时自动切换到从库。
9、提高从库的硬件性能
为从库配置更高性能的CPU和内存,以提高SQL执行效率。
使用SSD替代HDD以提高磁盘读写速度,从而减少I/O等待时间。
四、半同步复制是什么
半同步复制是MySQL的一种复制模式,它介于全同步复制和异步复制之间,旨在在保证数据一致性和系统性能之间取得平衡。
在传统的异步复制模式中,主库在执行完一条事务后,只需将二进制日志(Binlog)写入本地文件并立即返回给客户端,表示事务提交成功。随后,这些日志会异步地发送到从库,从库再进行重放。这种方式性能较好,但在主库故障时可能会导致部分事务丢失,因为这些事务还没有被从库接收到。
而在半同步复制中,当主库执行完一条事务并写入Binlog后,不会立即返回给客户端,而是会等待至少一个从库确认已经接收到这个Binlog。只有在收到从库的确认信号后,主库才会返回事务提交成功的响应给客户端。如果在设定的超时时间内没有收到从库的确认,主库会回退到异步复制模式,以保证系统的可用性。
五、半同步复制的优缺点
1、半同步复制的优点
(1)数据安全性增强
由于主库在返回事务提交成功之前,至少要确认一个从库已经接收到了该事务的Binlog,因此可以减少数据丢失的风险。
(2)更快的故障恢复
即使主库发生故障,从库已经接收到的事务数据可以使从库迅速接替主库角色,减少数据恢复的时间。
2、半同步复制的缺点
(1)性能开销
半同步复制需要等待从库的确认,会增加事务的提交时间,导致延迟增大,尤其是在网络延迟较大的情况下。
(2)依赖网络
如果网络状况不好,可能频繁超时回退到异步模式,降低整体系统的效率。
六、半同步复制的流程
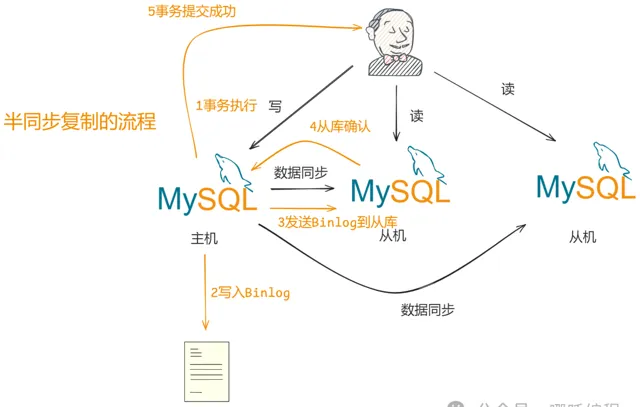
事务执行:客户端在主库上执行事务,事务在主库的存储引擎层完成。
写入Binlog:主库将事务记录写入二进制日志(Binlog)。
发送Binlog到从库:主库将Binlog发送到至少一个从库。
从库确认:从库接收到Binlog后,会立即返回一个确认信号给主库,表示已经接收到并写入Relay Log。
事务提交成功:主库在收到至少一个从库的确认后,返回事务提交成功的响应给客户端。
如果主库在一定时间内没有收到从库的确认信号,会回退到异步模式继续执行,以避免系统停滞。
半同步复制适用于那些对数据一致性要求较高,但又不能接受全同步复制带来的高延迟的场景。
常见应用场景包括:
金融系统:交易数据需要尽可能保证一致性,但仍需要一定的性能。
高可用集群:在保证一定程度的数据一致性的同时,允许快速故障切换。
通过配置半同步复制,MySQL可以在性能和数据一致性之间取得一定的平衡,减少数据丢失的风险。
如此浪潮下,作为程序员的你,还没用过ChatGPT4o吗?还没用过Copilot吗?
国内直接使用ChatGPT4o:
谷歌浏览器直接使用:https://www.nezhasoft.cn
无需魔法,同时支持手机、电脑
个人独享
ChatGPT4o mini永久免费
支持Copilot、DALLE AI绘画、上传文件等
长按识别下方二维码,备注ai,发给你


回复gpt,获取ChatGPT4o直接使用地址
点击阅读原文,国内直接使用ChatGpt4o











