小伙伴们好啊,今天咱们再来学习几个常用函数公式的典型用法:
1、根据日期返回季度
如下图所示,需要根据A列的日期,返回该日期所属的季度。
B2单元格输入以下公式,向下复制。
=MATCH(MONTH(A2),{0,4,7,10})
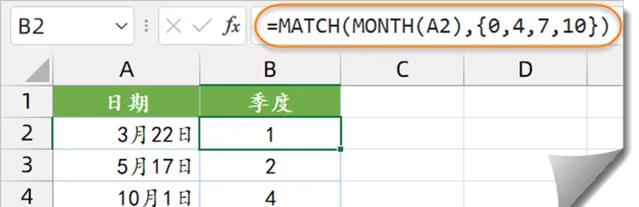
首先用MONTH函数计算出A2单元格所属的月份,结果为3。
再使用MATCH函数,计算该月份在常量数组{0,4,7,10}中所处的位置。{0,4,7,10},是各个季度的起始月份。
本例中MATCH函数省略了第三参数,其计算规则与使用参数1时相同,当查找不到对应的内容时,会以小于查找值的最接近的一个进行匹配,并返回对应的位置信息。
MATCH函数在常量数组{0,4,7,10}中找不到3,因此以小于3的最接近值0进行匹配,并返回0在常量数组{0,4,7,10}中的位置,结果为1。
2、科目拆分
如下图,需要按分隔符「/」,来拆分A列中的会计科目。
B2输入以下公式,下拉即可。
=TEXTSPLIT(A2,"/")
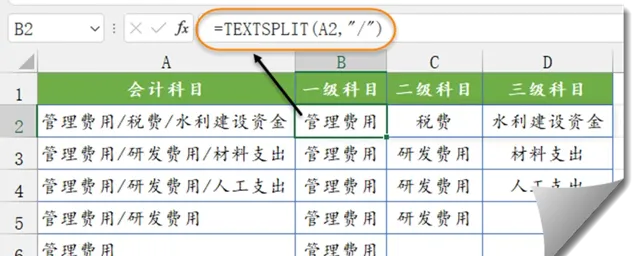
本例中,TEXTSPLIT的第二参数使用"/"作为列分隔符号,其他参数省略。
3、随机不重复数
如下图,要根据A列的姓名,生成随机面试顺序。
B2单元格输入以下公式:
=SORTBY(SEQUENCE(9),RANDARRAY(9))
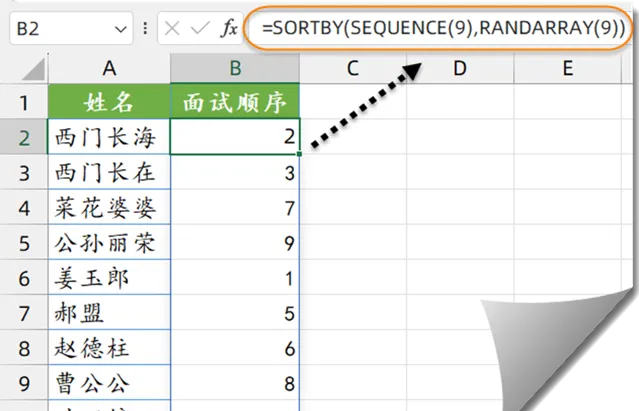
先使用SEQUENCE(9),生成1~9的连续序号。再使用RANDARRAY(9),生成9个随机小数。最后使用SORTBY函数,以随机小数为排序依据,对序号进行排序。
4、在不连续区域提取不重复值
如下图所示,希望从左侧值班表中提取出不重复的员工名单。
其中A列和C列为姓名,B列和D列为值班电话。
F2单元格输入以下公式:
=UNIQUE(VSTACK(A2:A7,C2:C7))
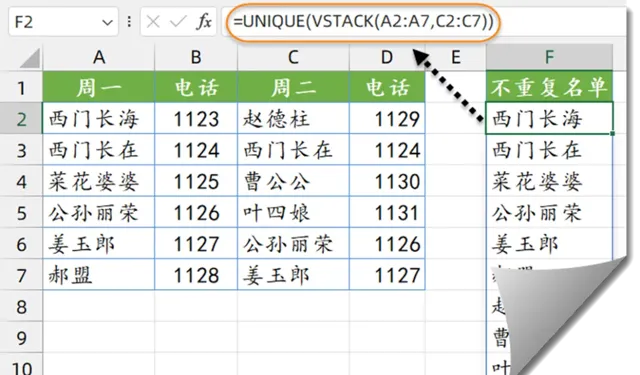
先使用VSTACK函数,把A2:A7和C2:C7两个不相邻的区域合并为一列,然后使用UNIQUE提取出不重复的记录。
5、按自定义序列排序
如下图,A~C列是一些员工信息,希望按照E列指定的部门顺序进行排序,同一部门的,再按年龄从大到小排序。
先将标题复制到右侧的空白单元格内,然后在第一个标题下方输入公式:
=SORTBY(A2:C21,MATCH(B2:B21,E2:E7,),1,C2:C21,-1)
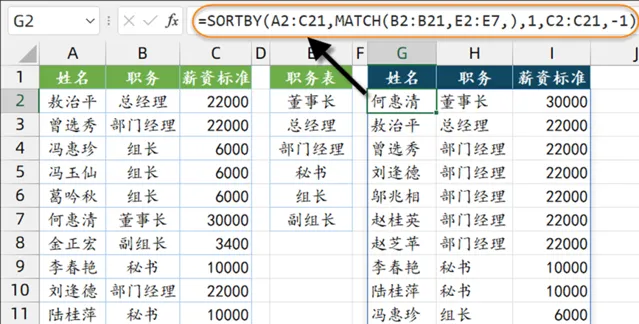
公式中的MATCH(B2:B21,E2:E7,)部分,分别查询B列职务在E2:E7区域中的位置,结果是这样的:
{2;3;5;5;5;1;6;4;3;4;5;6;5;5;3;6;5;6;3;3}
这一步的目的,实际上就是将B列的职务变成了E列的排列顺序号。总经理成了2,部门经理变成了3……
接下来的过程就清晰了:
SORTBY的排序区域为C2:C21单元格中的数据,排序依据是优先对部门顺序号升序排序,再对年龄执行升序排序。
好了,咱们今天就分享这些吧,祝各位一天好心情。
图文制作:祝洪忠











