計畫簡介
Snowflake Arctic 是一款專為企業級智慧設計的語言模型,透過極高的訓練效率和開放性推動成本效益的新標準。它采用了獨特的密集型和MoE混合變換架構,讓企業使用者可以以較低成本建立高品質客製模型。此外,Arctic 計畫不僅開源了模型權重和程式碼,還提供了完整的數據配方和研究洞見,真正實作了開放協作,推動了社群的集體學習和進步。
想要得到更多技術支持和交流
掃碼添加以下微信進入技術交流群
更多技術大咖在這等你

特點
這是一個面向企業的頂級大型語言模型(LLM),推動了成本效益訓練和開放性的前沿。Arctic 在智慧效率和真正的開放性上都表現出色。
智慧效率 :Arctic 在企業任務上表現出色,如 SQL 生成、編程和指令跟隨基準測試,即便與使用顯著更高計算預算的開源模型相比也是如此。事實上,它為成本效益訓練設定了新的基準,使 Snowflake 的客戶能夠以低成本為他們的企業需求建立高品質的客製模型。
真正的開放 :Apache 2.0 授權證提供了對權重和程式碼的無門檻存取。此外,還將開放所有的數據集和研究洞見。
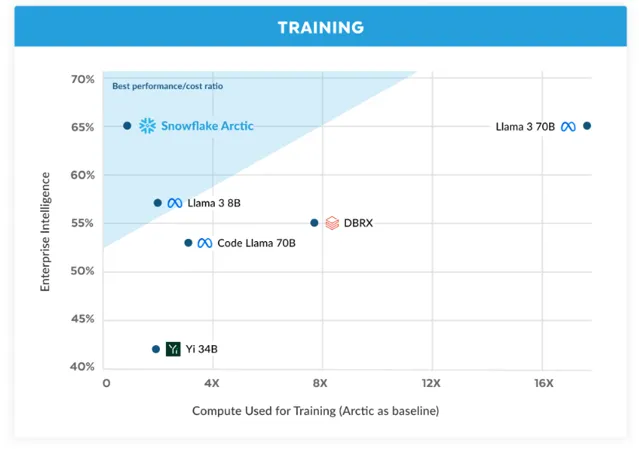
以極低的訓練成本提供頂級企業智慧
在 Snowflake,從企業客戶那裏看到了一種一致的 AI 需求和使用案例模式。企業希望利用大型語言模型(LLMs)來構建對話式 SQL 數據副駕駛、程式碼副駕駛和 RAG 聊天機器人。從指標角度看,這意味著在 SQL、編程、復雜指令跟隨以及產生有根據的答案方面表現出色的 LLMs。透過取編程(HumanEval+ 和 MBPP+)、SQL 生成(Spider)和指令跟隨(IFEval)的平均值,將這些能力匯總成一個我們稱之為企業智慧的單一指標。
Arctic 在開源大型語言模型中提供頂級企業智慧,並且使用的訓練計算預算大約在200萬美元以下。這意味著 Arctic 比使用類似計算預算的其他開源模型更有能力。更重要的是,它在企業智慧方面表現出色,即使與那些使用顯著更高計算預算訓練的模型相比也是如此。Arctic 的高訓練效率還意味著 Snowflake 客戶和廣大 AI 社群可以以更加經濟的方式訓練客製模型。
如圖1所示,Arctic 在企業指標上與 LLAMA 3 8B 和 LLAMA 2 70B 不相上下,甚至更好,同時使用的訓練計算預算不到一半。同樣,盡管使用的計算預算比 Llama3 70B 少17倍,Arctic 在企業指標如編程(HumanEval+ 和 MBPP+)、SQL(Spider)和指令跟隨(IFEval)上表現不相上下。它在整體效能上仍保持競爭力。例如,盡管使用的計算比 DBRX 少7倍,但在語言理解和推理(11個指標的集合)上仍具有競爭力,同時在數學(GSM8K)方面表現更好。

訓練效率
為了達到這種訓練效率,Arctic 使用了一種獨特的 Dense-MoE Hybrid transformer 架構。它結合了一個10B 的密集型變換器模型和一個剩余的128×3.66B MoE MLP,總計480B 參數,透過 top-2 門控選擇了17B 活躍參數。它的設計和訓練基於以下三個關鍵見解和創新:
1.多但精簡的專家與更多的專家選擇 :在2021年末,DeepSpeed 團隊展示了 MoE 可以套用於自回歸大型語言模型,顯著提升模型品質而不增加計算成本。
在設計 Arctic 的過程中,基於上述發現,模型品質的提升主要取決於 MoE 模型中的專家數量、專家總參數量以及這些專家組合的方式。
基於這一見解,Arctic 被設計為擁有480B 參數,這些參數分布在128個精細的專家之間,並使用 top-2 門控來選擇17B 活躍參數。相比之下,最近的 MoE 模型構建時使用的專家數量顯著少,如表2所示。直觀地說,Arctic 利用大量的總參數和眾多的專家來擴大模型容量,實作頂級智慧,同時它精心選擇多但精簡的專家,並運用適度數量的活躍參數,以實作資源高效的訓練和推理。
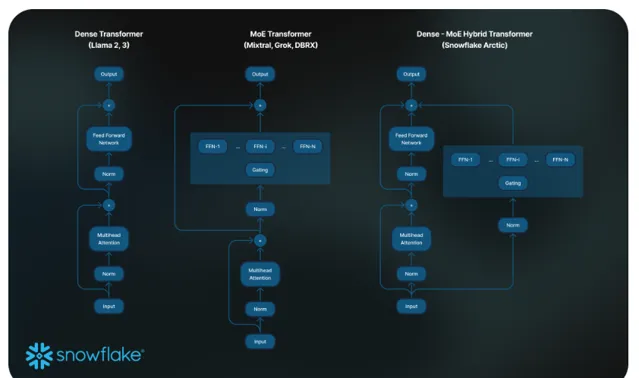
2.架構與系統共同設計 :即使在最強大的人工智慧訓練硬體上,使用大量專家的普通 MoE 架構的訓練效率也非常低,原因是專家之間的全通訊開銷很高。然而,如果通訊可以與計算重疊,就有可能隱藏這種開銷。
我們的第二個見解是,將密集型變換器與殘留誤差 MoE 元件(見圖 2)結合在 Arctic 架構中,使我們的訓練系統透過通訊計算重疊實作良好的訓練效率,隱藏了大部份通訊開銷。
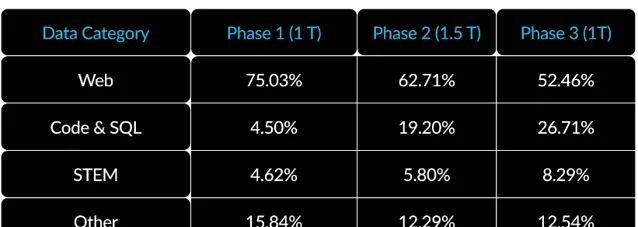
3.面向企業的數據課程 :在程式碼生成和 SQL 等企業指標上表現出色,需要與訓練通用指標的模型完全不同的數據課程。透過數百次小規模的消融實驗,了解到像常識推理這樣的通用技能可以在訓練初期學習,而像編程、數學和 SQL 這樣的更復雜的指標可以在訓練的後期有效學習。這可以類比人的生活和教育,從簡單到復雜逐步獲得能力。因此,Arctic 的訓練采用了三階段課程,每個階段使用不同的數據組合,第一階段(1T Tokens)關註通用技能,後兩階段(1.5T 和 1T tokens)關註企業核心技能。這裏展示了動態課程的高層次概述。
推理效率

訓練效率只代表了 Arctic 高效智慧的一個方面。推理效率對於以低成本實際部署模型同樣至關重要。Arctic 在 MoE 模型規模上代表了一次飛躍,使用的專家數量和總參數量超過了任何其他開源的自回歸 MoE 模型。因此,為了在 Arctic 上高效執行推理,需要多個系統見解和創新:
a) 在小批次互動式推理中,例如批次大小為1時,MoE 模型的推理延遲受限於讀取所有活躍參數所需的時間,此時推理受記憶體頻寬限制。在這個批次大小下,Arctic(17B 活躍參數)的記憶體讀取量可比 Code-Llama 70B 少4倍,比 Mixtral 8x22B(44B 活躍參數)少2.5倍,從而提高了推理效能。
已與 NVIDIA 合作,並與 NVIDIA(TensorRT-LLM)以及 vLLM 團隊合作,為互動式推理提供了 Arctic 的初步實作。透過 FP8 量化,我們可以將 Arctic 配置在單個 GPU 節點內。雖然還遠未完全最佳化,但在批次大小為1時,Arctic 的吞吐量可達到每秒70+個token,有效支持互動式服務。
b) 當批次大小顯著增加,例如每次前向傳遞成千上萬個token時,Arctic 從記憶體頻寬受限轉變為計算受限,此時推理受每個令牌的活躍參數限制。在這一點上,Arctic 的計算量比 CodeLlama 70B 和 Llama 3 70B 少4倍。
為了實作計算受限的推理和與 Arctic 中活躍參數數量較少相對應的高相對吞吐量(如圖3所示),需要較大的批次大小。實作這一點需要有足夠的 KV 緩存記憶體來支持大批次大小,同時還需要足夠的記憶體來儲存近500B 的模型參數。盡管具有挑戰性,但可以透過使用 FP8 權重、分裂-融合和連續批次處理、節點內的張量並列性和節點間的管道並列性等系統最佳化,采用雙節點推理來實作。
計畫連結
https://huggingface.co/Snowflake/snowflake-arctic-instruct
關註「 開源AI計畫落地 」公眾號











