前言
廢話少說,直接進入正題。
相信大家對
XXL-JOB
都很了解,故本文對源碼不進行過多介紹,側重的是
看源碼過程中想到的幾個知識點
,不一定都對,請大神們批評指正。
XXL-JOB簡介
XXL-JOB
是一個輕量級分布式任務排程平台,其核心設計目標是開發迅速、學習簡單、輕量級、易擴充套件。現已開放原始碼並接入多家公司線上產品線,開箱即用。
XXL-JOB
分為排程中心、執行器、數據中心,排程中心負責任務管理及排程、執行器管理、日誌管理等,執行器負責任務執行及執行結果回呼。
任務排程 - 「類時間輪」的實作
時間輪
時間輪出自
Netty
中的
HashedWheelTimer
,是一個環形結構,可以用時鐘來類比,鐘面上有很多
bucket
,每一個
bucket
上可以存放多個任務,使用一個
List
保存該時刻到期的所有任務,同時一個指標隨著時間流逝一格一格轉動,並執行對應
bucket
上所有到期的任務。任務透過
取模
決定應該放入哪個
bucket
。和
HashMap
的原理類似,
newTask
對應
put
,使用
List
來解決 Hash 沖突。

以上圖為例,假設一個
bucket
是1秒,則指標轉動一輪表示的時間段為8s,假設當前指標指向 0,此時需要排程一個3s後執行的任務,顯然應該加入到(0+3=3)的方格中,指標再走3s次就可以執行了;如果任務要在10s後執行,應該等指標走完一輪零2格再執行,因此應放入2,同時將
round(1)
保存到任務中。檢查到期任務時只執行
round
為0的,
bucket
上其他任務的
round
減1。
當然,還有最佳化的「分層時間輪」的實作,請參考
https://cnkirito.moe/timer/
。
XXL-JOB中的「時間輪」
XXL-JOB中的排程方式從
Quartz
變成了自研排程的方式,很像時間輪,可以理解為有60個
bucket
且每個
bucket
為1秒,但是沒有了
round
的概念。
具體可以看下圖。
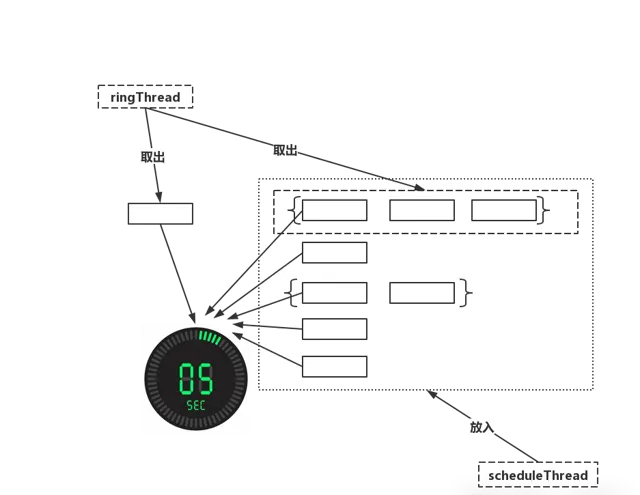
中負責任務排程的有兩個執行緒,分別為
ringThread
和
scheduleThread
,其作用如下。
❝
1、scheduleThread:對任務資訊進行讀取,預讀未來
5s
即將觸發的任務,放入時間輪。2、ringThread:對當前
bucket
和前一個
bucket
中的任務取出並執行。
下面結合原始碼看下,為什麽說是「類時間輪」,關鍵程式碼附上了註解,請大家留意觀看。
// 環狀結構
privatevolatilestatic Map<Integer, List<Integer>> ringData = new ConcurrentHashMap<>();
// 任務下次啟動時間(單位為秒) % 60
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 任務放進時間輪
privatevoidpushTimeRing(int ringSecond, int jobId){
// push async ring
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList<Integer>();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
}
// 同時取兩個時間刻度的任務
List<Integer> ringItemData = new ArrayList<>();
int nowSecond = Calendar.getInstance().get(Calendar.SECOND);
// 避免處理耗時太長,跨過刻度,向前校驗一個刻度;
for (int i = 0; i < 2; i++) {
List<Integer> tmpData = ringData.remove( (nowSecond+60-i)%60 );
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
// 執行
for (int jobId: ringItemData) {
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null);
}
一致性Hash路由中的Hash演算法
大家也知道,
XXL-JOB
在執行任務時,任務具體在哪個執行器上執行是根據路由策略來決定的,其中有一個策略是一致性Hash策略(源碼在ExecutorRouteConsistentHash.java),自然而然想到了
一致性Hash演算法
。
一致性Hash演算法 是為了解決分布式系統中負載均衡的問題時候可以使用Hash演算法讓固定的一部份請求落到同一台伺服器上,這樣每台伺服器固定處理一部份請求(並維護這些請求的資訊),起到負載均衡的作用。
普通的余數hash(hash(比如使用者id)%伺服器機器數)演算法伸縮性很差,當新增或者下線伺服器機器時候,使用者id與伺服器的對映關系會大量失效。一致性hash則利用hash環對其進行了改進。
一致性Hash演算法 在實踐中,當伺服器節點比較少的時候會出現上節所說的一致性hash傾斜的問題,一個解決方法是多加機器,但是加機器是有成本的,那麽就加 虛擬節點 。
具體原理請參考https://www.jianshu.com/p/e968c081f563。
下圖為帶有虛擬節點的Hash環,其中ip1-1是ip1的虛擬節點,ip2-1是ip2的虛擬節點,ip3-1是ip3的虛擬節點。
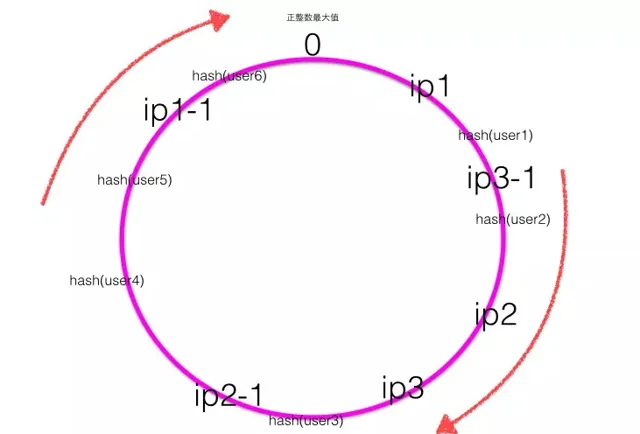
可見 ,一致性Hash演算法的關鍵在於 Hash演算法 ,保證 虛擬節點 及 Hash結果 的均勻性,而均勻性可以理解為 減少Hash沖突 ,Hash沖突的知識點本文暫不擴充套件,歷史文章中有。或者將來我再抽時間寫。
XXL-JOB中的一致性Hash的Hash函式如下。
// jobId轉換為md5
// 不直接用hashCode() 是因為擴大hash取值範圍,減少沖突
byte[] digest = md5.digest();
// 32位元hashCode
long hashCode = ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
long truncateHashCode = hashCode & 0xffffffffL;
看到上圖的Hash函式,讓我想到了
HashMap
的Hash函式
f(key) = hash(key) & (table.length - 1)
// 使用>>> 16的原因,hashCode()的高位和低位都對f(key)有了一定影響力,使得分布更加均勻,雜湊沖突的機率就小了。
hash(key) = (h = key.hashCode()) ^ (h >>> 16)
同理,將jobId的md5編碼的高低位都對Hash結果有影響,使得 沖突的機率減小。
分片任務的實作 - 維護執行緒上下文
的分片任務實作了任務的分布式執行,其實是筆者調研的重點,日常開發中很多定時任務都是單機執行,對於後續數據量大的任務最好有一個分布式的解決方案。
分片任務的路由策略,原始碼作者提出了 分片廣播 的概念,剛開始還有點摸不清頭腦,看了源碼逐漸清晰了起來。
想必看過源碼的也遇到過這麽一個小插曲,路由策略咋沒實作?如下圖所示。
publicenum ExecutorRouteStrategyEnum {
FIRST(I18nUtil.getString("jobconf_route_first"), new ExecutorRouteFirst()),
LAST(I18nUtil.getString("jobconf_route_last"), new ExecutorRouteLast()),
ROUND(I18nUtil.getString("jobconf_route_round"), new ExecutorRouteRound()),
RANDOM(I18nUtil.getString("jobconf_route_random"), new ExecutorRouteRandom()),
CONSISTENT_HASH(I18nUtil.getString("jobconf_route_consistenthash"), new ExecutorRouteConsistentHash()),
LEAST_FREQUENTLY_USED(I18nUtil.getString("jobconf_route_lfu"), new ExecutorRouteLFU()),
LEAST_RECENTLY_USED(I18nUtil.getString("jobconf_route_lru"), new ExecutorRouteLRU()),
FAILOVER(I18nUtil.getString("jobconf_route_failover"), new ExecutorRouteFailover()),
BUSYOVER(I18nUtil.getString("jobconf_route_busyover"), new ExecutorRouteBusyover()),
// 說好的實作呢???竟然是null
SHARDING_BROADCAST(I18nUtil.getString("jobconf_route_shard"), null);
再繼續追查得到了結論,待我慢慢道來,首先分片任務執行參數傳遞的是什麽?看
XxlJobTrigger.trigger
函式中的一段程式碼。
...
// 如果是分片路由,走的是這段邏輯
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST == ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList() != null && !group.getRegistryList().isEmpty()
&& shardingParam == null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
// 最後兩個參數,i是當前機器在執行器集群當中的index,group.getRegistryList().size()為執行器總數
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
}
...
參數經過自研RPC傳遞到執行器,在執行器中具體負責任務執行的
JobThread.run
中,看到了如下程式碼。
// 分片廣播的參數比set進了ShardingUtil
ShardingUtil.setShardingVo(new ShardingUtil.ShardingVO(triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal()));
...
// 將執行參數傳遞給jobHandler執行
handler.execute(triggerParamTmp.getExecutorParams())
接著看
ShardingUtil
,才發現了其中的奧秘,請看程式碼。
public classShardingUtil{
// 執行緒上下文
privatestatic InheritableThreadLocal<ShardingVO> contextHolder = new InheritableThreadLocal<ShardingVO>();
// 分片參數物件
publicstatic classShardingVO{
privateint index; // sharding index
privateint total; // sharding total
// 次數省略 get/set
}
// 參數物件註入上下文
publicstaticvoidsetShardingVo(ShardingVO shardingVo){
contextHolder.set(shardingVo);
}
// 從上下文中取出參數物件
publicstatic ShardingVO getShardingVo(){
return contextHolder.get();
}
}
顯而易見,在負責分片任務的
ShardingJobHandler
裏取出了執行緒上下文中的分片參數,這裏也給個程式碼把~
@JobHandler(value="shardingJobHandler")
@Service
public classShardingJobHandlerextendsIJobHandler{
@Override
public ReturnT<String> execute(String param)throws Exception {
// 分片參數
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片參數:當前分片序號 = {}, 總分片數 = {}", shardingVO.getIndex(), shardingVO.getTotal());
// 業務邏輯
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log("第 {} 片, 命中分片開始處理", i);
} else {
XxlJobLogger.log("第 {} 片, 忽略", i);
}
}
return SUCCESS;
}
}
由此得出,分布式實作是根據分片參數
index
及
total
來做的,簡單來講,就是給出了當前執行器的標識,根據這個標識將任務的數據或者邏輯進行區分,即可實作分布式執行。
題外話:至於為什麽用外部註入分片參數的方式,不直接
execute
傳遞?
❝
1、可能是因為只有分片任務才用到這兩個參數
2、IJobHandler只有String型別參數
看完源碼後的思考
1、經過此次看原始碼, 的設計目標確實符合 開發迅速、學習簡單、輕量級、易擴充套件 。
2、至於自研 還沒有具體考量,具體接入應該會考慮公司的RPC框架。
3、作者給出的
Quartz
排程的不足,筆者得繼續深入了解。
4、框架中很多對宕機、故障、超時等異常狀況的相容值得學習。
5、Rolling日誌以及日誌系統實作需要繼續了解。
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:ZacPark
來源:https://juejin.cn/post/6844903954145361927
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











