點選上方 "
Python人工智慧技術
"
關註,
星標或者置頂
22點24分準時推播,第一時間送達
後台回復「
大禮包
」,送你特別福利
編輯:樂樂 | 來自: 機器之心
上一篇:
正文
大家好,我是Python人工智慧技術
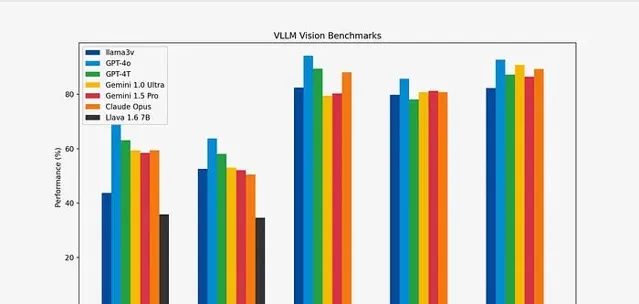
在 GPT-4o 出世後,Llama3 的風頭被狠狠蓋過。GPT-4o 在影像辨識、語音理解上卓越的效能展現了它強大多模態能力。開源領域的領頭羊 Llama3 曾在幾乎所有基準測試中都超越了 GPT-3.5,甚至在某些方面超越了 GPT-4。這次就要悶聲「吃癟」了嗎?
5 月 29 日,一個來自史丹佛的研究團隊釋出了一個能夠「改變現狀」的產品:Llama3-V,號稱只要 500 美元(約為人民幣 3650 元),就能基於 Llama3 訓練出一個超強的多模態模型,效果與 GPT4-V、Gemini Ultra 、 Claude Opus 多模態效能相當,但模型小 100 倍。
Github 計畫連結:https://github.com/mustafaaljadery/llama3v(已刪庫)
HuggingFace 計畫連結:https://huggingface.co/mustafaaljadery/llama3v(已刪庫)
用這麽少的成本,創造出了如此驚艷的成果,Llama3-V 在推特上迅速爆火,瀏覽量突破 30 萬,轉發超過 300 次,還沖上了「 HuggingFace Trending 」Top 5。
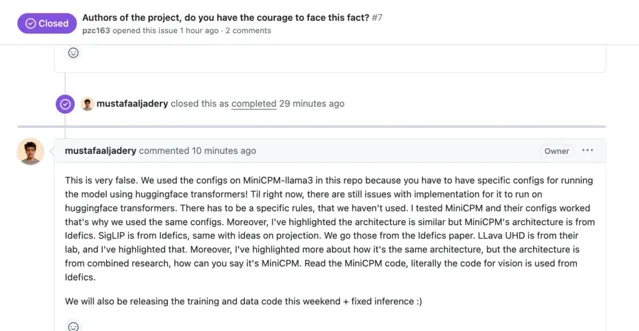
但是沒釋出兩天,Llama3-V 就遭遇了重重質疑。有人指出,Llama3-V 計畫中有一大部份似乎竊取了清華大學自然語言處理實驗室與面壁智慧合作開發的多模態模型 MiniCPM-Llama3-V 2.5。
MiniCPM-V 是面向圖文理解的端側多模態大模型系列。MiniCPM-Llama3-V 2.5 是該系列的最新版本。其多模態綜合效能超越 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等商用閉源模型。OCR 能力及指令跟隨能力進一步提升,並支持超過 30 種語言的多模態互動。這樣的優秀效能,不僅讓 MiniCPM-Llama3-V 2.5 成為受大家推崇的模型,或許也成為了 Llama3-V 的「模仿」物件。
計畫地址:https://github.com/OpenBMB/MiniCPM-V/blob/main/README_zh.md
可疑的作者答復
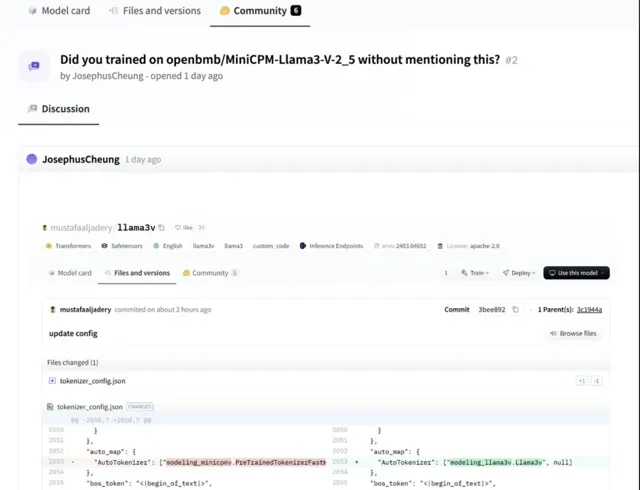
HuggingFace 使用者 JosephusCheung 在計畫的評論區中提出問題,Llama3-V 是否在未提及的情況下使用 openbmb/MiniCPM-Llama3-V-2.5 進行了訓練。而作者回復表明,Llama3-V 使用了 MiniCPM-Llama3-V-2.5 的預訓練 tokenizer,並且是在它釋出前就開始了這項工作。這樣的解釋明顯出現了時間錯位,加重了大家的懷疑。
細扒其中貓膩
此外,還有一位名為 Magic Yang 的網友也產生了質疑,他對於這兩個模型的相似性也有著更深的洞察。
他首先在 Llama3-V 的 GitHub 計畫 Issue 中釋出了他的疑問,沒想到 Llama3-V 的作者們很快就刪除了質疑帖。
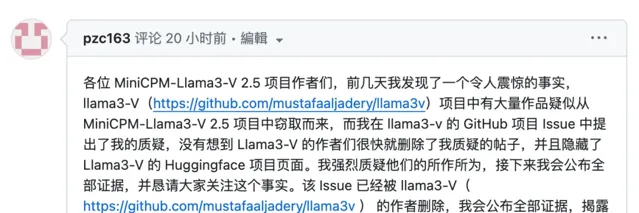
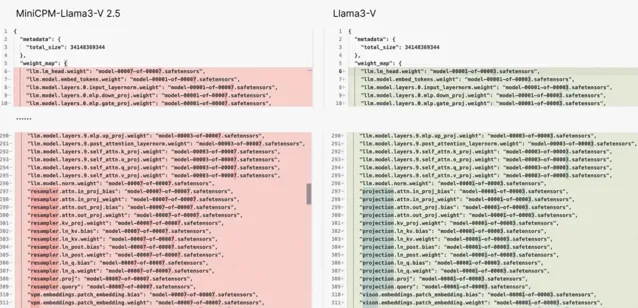
在這個 Issue 中,他首先提出,Llama3-V 與 MiniCPM- Llama3-V 2.5 具有相同的模型結構和配置檔,只是變量名不同。Llama3-V 的程式碼幾乎完全照抄 MiniCPM-Llama3-V 2.5,只是進行了一些格式上的修改,包括但不限於分割影像、tokenizer、重采樣器和數據載入部份。

Llama3-V 的作者立馬回復,稱 Llama3-V 在架構上參考的是 LLaVA-UHD,並列出了在 ViT 和 LLM 選擇上與 Mini CPM-Llama3-V 2.5 的差異。
但 Magic Yang 發現,相比 LLaVA-UHD 所用的方法,Llama3-V 與 MiniCPM-Llama3-V 2.5 可謂是一模一樣。特別是 Llama3-V 使用了與 MiniCPM-Llama3-V 2.5 相同的,連 MiniCPM-Llama3-V 2.5 新定義的特殊符號都「抄」上了。
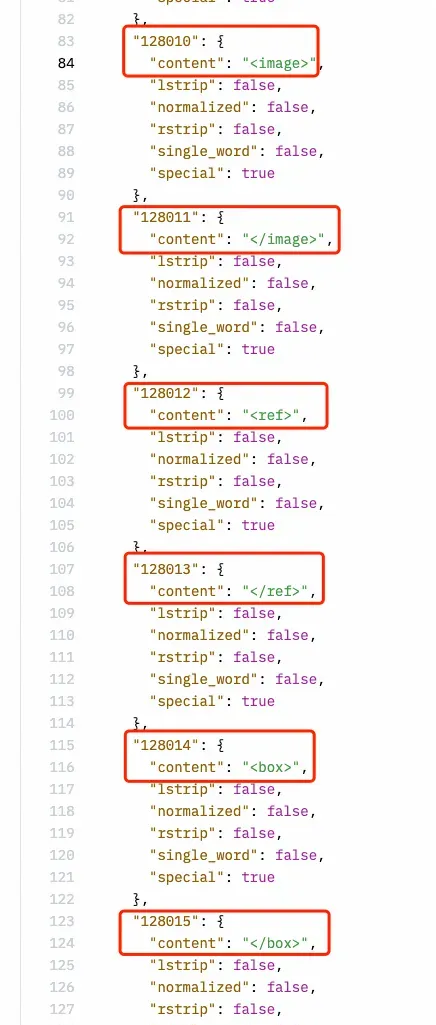
於是,他向作者提問,為什麽 Llama3-V 在 MiniCPM-Llama3-V2.5 計畫釋出之前,就未蔔先知似的拿到了其 tokenizer?這似乎算是追問了作者對 JosephusCheung 的回答。
Llama3-V 作者回答稱,他參考了 MiniCPM-V-2 的 tokenizer(https://huggingface.co/openbmb/MinicPM-V-2/blob/main/tokenizer.jsonBefore),MiniCPM-Llama3-V2.5 采用了新的 tokenizer 和原來版本中的特殊符號,因此 Llama3-V 的程式碼中保留了這個符號,但 Llama3-V 與 MiniCPM-Llama3-V2.5 是完全不同。
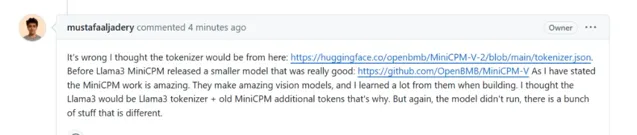
但事實是,MiniCPM-V-2 的 tokenizer 與 MinicPM-Llama3-V2.5 完全不同,在 Hugging Face 裏是兩個檔,檔大小也完全不同,也不包含 Llama3-V 所用到的與 Llama 3 有關的 tokenizer。
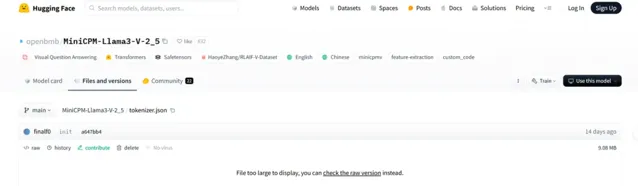
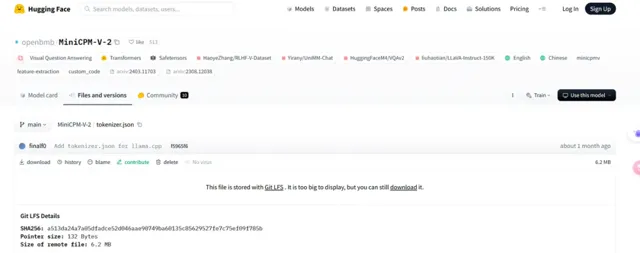
Magic Yang 還發現了 Llama3-V 的作者在 Hugging Face 上傳計畫時,直接匯入了 MiniCPM-Llama3-V 2.5 的程式碼,後來才把一些檔裏的名稱替換為 Llama3-V。
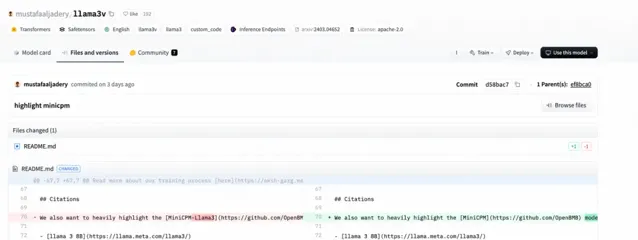
於是,Llama3-V 的作者的作者再次回復,稱 Magic Yang 的指控大錯特錯。首先,想要執行 HuggingFace Transformer,需要給模型寫配置檔,但是他們恰好發現 MiniCPM 的配置能用,因此,他們使用了與 MiniCPM 相同的配置。其二,Llama3-V 的模型架構 SigLIP 的靈感來源於 Idéfics ,作者之前也提到,Llama3-V 模型架構參考的 LLaVA-UHD 同樣如此,並且在視覺程式碼方面,他們借鑒了 Idéfics ,並非照搬 MiniCPM。
更令人驚訝的是, Magic Yang 發現 Llama3-V 計畫的作者似乎並不理解他們自己的程式碼,或許也不明白搬來的 MiniCPM-Llama3-V 2.5 架構中的細節。
感知器重采樣器(Perceiver Resampler)使用的是單層交叉註意力,而非雙層自註意力。然而,下圖中的 Llama3-V 技術部落格中的描述明視訊記憶體在誤解。

Llama3-V 的技術部落格
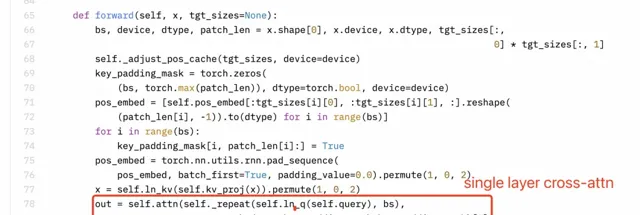
Llama3-V 的程式碼
此外,SigLIP 的 Sigmoid 啟用功能並不用於訓練多模態大語言模型,而是僅在 SigLIP 的預訓練過程中使用。看來,作者對於自己的程式碼理解還是有很大偏差的。

Llama3-V 的技術部落格
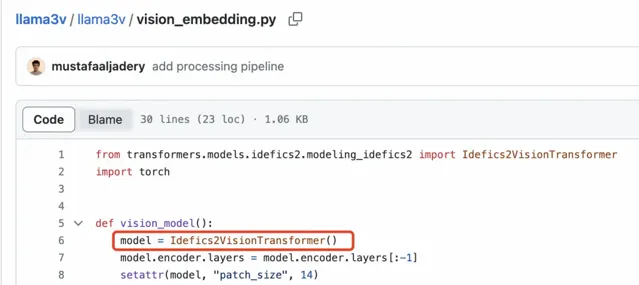
Llama3-V 的程式碼
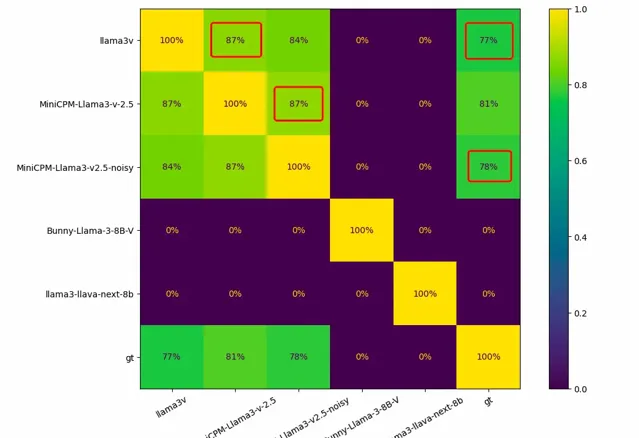
對於清華 NLP 實驗室和面壁智慧團隊特別采集和標註,從未對外公開的專有數據,Llama3-V 的表現也非常出色。「清華簡」是一種非常特殊且罕見的中國戰國時期的古文字,而美國模型 Llama3-V 不僅認識中國古文字,在認錯字的時候,也和 MiniCPM-Llama3-V 2.5 一模一樣。

有網友用 1000 張竹簡影像對同類模型進行了測試,正常情況下,每兩個模型之間的重疊應該為 0,而 Llama3-V 和 MiniCPM-Llama3-V 2.5 之間的重疊高達 87%。辨識錯誤的結果 Llama3-V 和 MiniCPM-Llama3-V 2.5 也有高達 182 個重合。
刪庫?也不管用
在重重質疑之後,Llama3-V 的作者行動了。此前宣傳 Llama3-V 的推特內容流已不可見。
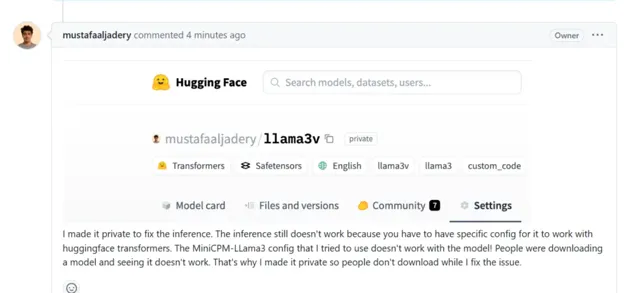
他還隱藏了 HuggingFace 的倉庫。Magic Yang 再次發難,問 Llama3-V 的作者為何在 HuggingFace 上將模型設為私密?
作者稱,設為私密是為了修復 Llama3-V 的推理功能,MiniCPM 的配置與 Llama3-V 不相容,當時 HuggingFace Transformers 無法正確地載入模型,為了避免下載模型的使用者執行失敗,他將進行一些修復。
同樣地,Llama3-V 的 GitHub 計畫主頁也顯示為「404」。
GitHub 地址:https://github.com/mustafaaljadery/llama3v
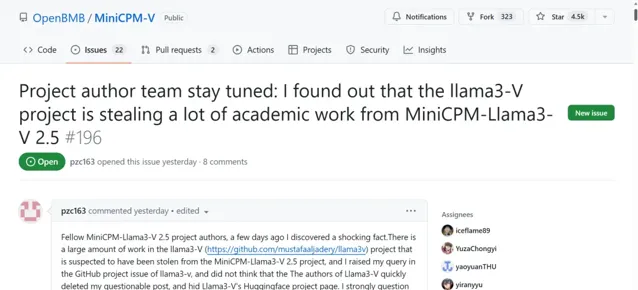
這些舉動顯然是為了應對社群的強烈反應和對模型來源合法性的質疑。但這樣的逃避似乎並不管用。即使 Magic Yang 與對話已經隨著計畫頁面 404 而隱藏。但 Magic Yang 已將對話截圖評論在了 MiniCPM-V 的 GitHub 頁面。
據網友反饋,當執行 Llama3-V 時,作者提供的程式碼無法與 HuggingFace 上的 checkpoint 相容。然而,當把 Llama3-V 模型權重中的變量名更改為 MiniCPM-Llama3-V 2.5 後,就能成功執行。
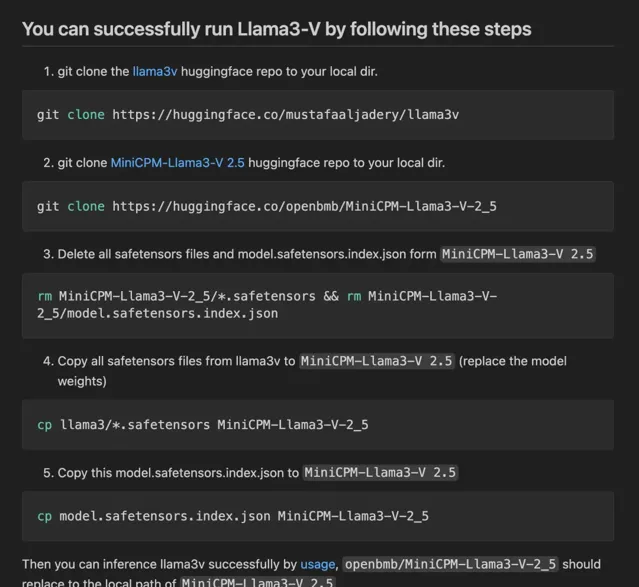
如果在 MiniCPM-Llama3-V 2.5 的 checkpoint 上添加一個簡單的高斯雜訊,就會得到一個在各個測試集上的表現都與 Llama3-V 極為相似的模型。
有網友上傳了 Llama3-V 刪庫前的檢查點,大家可以自行測試驗證。
檢查點連結:https://twitter.com/zhanga6/status/1797293207338041719
有人認為,這是關乎道德、誠信與聲譽的問題。如果抄襲得到驗證,史丹佛大學應該介入調查。
圖源:X@AvikonHadoop
在國內外輿情發酵了兩天後,作者之一站出來道歉,稱「抄襲」源於對隊友 Mustafa 的盲信。
為了跟上AI時代我幹了一件事兒,我建立了一個知識星球社群:ChartGPT與副業。想帶著大家一起探索 ChatGPT和新的AI時代 。
有很多小夥伴搞不定ChatGPT帳號,於是我們決定,凡是這三天之內加入ChatPGT的小夥伴,我們直接送一個正常可用的永久ChatGPT獨立帳戶。
不光是增長速度最快,我們的星球品質也絕對經得起考驗,短短一個月時間,我們的課程團隊釋出了 8個專欄、18個副業計畫 :
簡單說下這個星球能給大家提供什麽:
1、不斷分享如何使用ChatGPT來完成各種任務,讓你更高效地使用ChatGPT,以及副業思考、變現思路、創業案例、落地案例分享。
2、分享ChatGPT的使用方法、最新資訊、商業價值。
3、探討未來關於ChatGPT的機遇,共同成長。
4、幫助大家解決ChatGPT遇到的問題。
5、 提供一整年的售後服務,一起搞副業
星球福利:
1、加入星球4天後,就送ChatGPT獨立帳號。
2、邀請你加入ChatGPT會員交流群。
3、贈送一份完整的ChatGPT手冊和66個ChatGPT副業賺錢手冊。
其它福利還在籌劃中... 不過,我給你大家保證,加入星球後,收獲的價值會遠遠大於今天加入的門票費用 !
本星球第一期原價 399 ,目前屬於試營運,早鳥價 169 ,每超過50人漲價10元,星球馬上要來一波大的漲價,如果你還在猶豫,可能最後就要以 更高價格加入了 。。
早就是優勢。建議大家盡早以便宜的價格加入!
歡迎有需要的同學試試,如果本文對您有幫助,也請幫忙點個 贊 + 在看 啦!❤️
在 還有更多優質計畫系統學習資源,歡迎分享給其他同學吧!
你還有什
麽想要補充的嗎?
免責聲明:本文內容來源於網路,文章版權歸原作者所有,意在傳播相關技術知識&行業趨勢,供大家學習交流,若涉及作品版權問題,請聯系刪除或授權事宜。
技術君個人微信
添加技術君個人微信即送一份驚喜大禮包
→ 技術資料共享
→ 技術交流社群
--END--
往日熱文:
Python程式設計師深度學習的「四大名著」:
這四本書著實很不錯!我們都知道現在機器學習、深度學習的資料太多了,面對海量資源,往往陷入到「無從下手」的困惑出境。而且並非所有的書籍都是優質資源,浪費大量的時間是得不償失的。給大家推薦這幾本好書並做簡單介紹。
獲得方式:
1.掃碼關註本公眾號
2.後台回復關鍵詞:名著
▲長按掃描關註,回復名著即可獲取











