
點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 新智元授權
【導讀】 近日,Picsart AI Resarch等團隊聯合釋出了StreamingT2V,可以生成長達1200幀、時長為2分鐘的視訊,一舉超越Sora。同時,作為開源世界的強大元件,StreamingT2V可以無縫相容SVD和animatediff等模型。
120秒超長AI視訊模型來了!不但比Sora長,而且免費開源!
近日,Picsart AI Resarch等團隊聯合釋出了StreamingT2V,可以生成長達1200幀、時長為2分鐘的視訊,同時品質也很不錯。

論文地址:https://arxiv.org/pdf/2403.14773.pdf
Demo試用:https://huggingface.co/spaces/PAIR/StreamingT2V
開原始碼:https://github.com/Picsart-AI-Research/StreamingT2V
並且,作者表示,兩分鐘並不是模型的極限,就像之前Runway的視訊可以延長一樣,StreamingT2V理論上可以做到無限長。
在Sora之前,Pika、Runway、Stable Video Diffusion(SVD)等視訊生成模型,一般只能生成幾秒鐘的視訊,最多延長到十幾秒,
Sora一出,60秒的時長直接秒殺一眾模型,Runway的CEO Cristóbal Valenzuela當天便發推表示:比賽開始了。

——這不,120秒的超長AI視訊說來就來了。
這下雖說不能馬上撼動Sora的統治地位,但至少在時長上扳回一城。
更重要的是,StreamingT2V作為開源世界的強大元件,可以相容SVD和animatediff等計畫,更好地促進開源生態的發展:
透過放出的例子來看,目前相容的效果還稍顯抽象,但技術進步只是時間的問題,卷起來才是最重要的~
總有一天我們都能用上「開源的Sora」,——你說是吧?OpenAI。
免費開玩
目前,StreamingT2V已在GitHub開源,同時還在huggingface上提供了免費試玩,等不了了,小編馬上開測:
不過貌似伺服器負載太高,上面的這個不知道是不是等待時間,反正小編沒能成功。
目前試玩的界面可以輸入文字和圖片兩種提示,後者需要在下面的高級選項中開啟。
兩個生成按鈕中,Faster Preview指的是分辨率更低、時長更短的視訊。

小編於是轉戰另一個測試平台(https://replicate.com/camenduru/streaming-t2v),終於獲得一次測試機會,以下是文字提示:
A beautiful girl with short hair wearing a school uniform is walking on the spring campus
不過可能由於小編的要求比較復雜,導致生成的效果多少有點驚悚,諸位可以根據自己的經驗自行嘗試。
以下是huggingface上給出的一些成功案例:

StreamingT2V

「世界名畫」
Sora的橫空出世曾帶來巨大的轟動,使得前一秒還閃閃發光的Pika、Runway、SVD等模型,直接變成了「前Sora時代」的作品。
不過就如同StreamingT2V的作者所言,pre-Sora days的模型也有自己的獨特魅力。
模型架構
StreamingT2V是一種先進的自回歸技術,可以建立具有豐富運動動態的長視訊,而不會出現任何停滯。
它確保了整個視訊的時間一致性,與描述性文本緊密對齊,並保持了高幀級影像品質。
現有的文本到視訊擴散模型,主要集中在高品質的短視訊生成(通常為16或24幀)上,直接擴充套件到長視訊時,會出現品質下降、表現生硬或者停滯等問題。
AI生成視訊
而透過引入StreamingT2V,可以將視訊擴充套件到80、240、600、1200幀,甚至更長,並具有平滑過渡,在一致性和運動性方面優於其他模型。
StreamingT2V的關鍵元件包括:
(i)稱為條件註意力模組(CAM)的短期記憶塊,它透過註意機制根據從前一個塊中提取的特征來調節當前一代,從而實作一致的塊過渡;
(ii)稱為外觀保留模組(APM)的長期記憶塊,它從第一個視訊塊中提取高級場景和物件特征,以防止模型忘記初始場景;
(iii)一種隨機混合方法,該方法能夠對無限長的視訊自動回歸套用視訊增強器,而不會出現塊之間的不一致。

上面是StreamingT2V的整體流水線圖。在初始化階段,第一個16幀塊由文本到視訊模型合成。在流式處理 T2V 階段中,將自動回歸生成更多幀的新內容。
最後,在流最佳化階段,透過套用高分辨率文本到短視訊模型,並配備上面提到的隨機混合方法,生成的長視訊(600、1200幀或更多)會自動回歸增強。
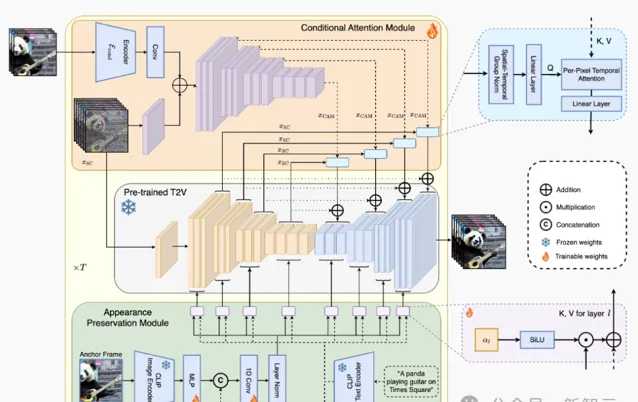
上圖展示了StreamingT2V方法的整體結構:條件註意力模組(CAM)作為短期記憶,外觀保留模組(APM)擴充套件為長期記憶。CAM使用幀編碼器對前一個塊上的視訊擴散模型(VDM)進行條件處理。
CAM的註意力機制保證了塊和視訊之間的平滑過渡,同時具有高運動量。
APM從錨幀中提取高級影像特征,並將其註入到VDM的文本交叉註意力中,這樣有助於在視訊生成過程中保留物件/場景特征。
條件註意模組
研究人員首先預訓練一個文本到(短)視訊模型(Video-LDM),然後使用CAM(前一個區塊的一些短期資訊),對Video-LDM進行自回歸調節。
CAM由一個特征提取器和一個特征註入器組成,整合到Video-LDM的UNet中,特征提取器使用逐幀影像編碼器 E。
對於特征註入,作者使UNet中的每個遠端跳躍連線,都關註CAM透過交叉註意力生成的相應特征。

CAM使用前一個塊的最後一個Fconditional幀作為輸入,交叉註意力能夠將基本模型的F幀調節為CAM。
相比之下,稀疏編碼器使用摺積進行特征註入,因此需要額外的F − Fzero值幀(和掩碼)作為輸入,以便將輸出添加到基本模型的F幀中。這會導致SparseCtrl的輸入不一致,導致生成的視訊嚴重不一致。
外觀保存模組
自回歸視訊生成器通常會忘記初始物件和場景特征,從而導致嚴重的外觀變化。
為了解決這個問題,外觀保留模組(APM)利用第一個塊的固定錨幀中包含的資訊來整合長期記憶。這有助於在視訊塊生成之間維護場景和物件特征。

為了使APM能夠平衡錨幀的引導和文本指令的引導,作者建議:
(i)將錨幀的CLIP影像標記,與文本指令中的CLIP文本標記混合,方法是使用線性層將剪輯影像標記擴充套件到k = 8, 在標記維度上連線文本和影像編碼,並使用投影塊;
(ii) 為每個交叉註意力層引入了一個權重α∈R(初始化為0),以使用來自加權總和x的鍵和值,來執行交叉註意力。
自動回歸視訊增強
為了進一步提加文本到視訊結果的品質和分辨率,這裏利用高分辨率(1280x720)文本到(短)視訊模型(Refiner Video-LDM)來自動回歸增強生成視訊的24幀塊。
使用文本到視訊模型作為24幀塊的細化器/增強器,是透過向輸入視訊塊添加大量雜訊,並使用文本到視訊擴散模型去噪來完成的。
然而,獨立增強每個塊的簡單方法會導致不一致的過渡:

作者透過在連續塊之間使用共享雜訊,並利用隨機混合方法來解決這個問題。
對比測試

上圖是DynamiCrafter-XL和StreamingT2V的視覺比較,使用相同的提示。
X-T切片視覺化顯示,DynamiCrafter-XL存在嚴重的塊不一致和重復運動。相比之下,StreamingT2V則可以無縫過渡、不斷發展。
現有方法不僅容易出現時間不一致和視訊停滯,而且隨著時間的推移,它們會受到物體外觀/特征變化,和視訊品質下降的影響(例如下圖中的SVD)。

原因是,由於僅對前一個塊的最後一幀進行調節,它們忽略了自回歸過程的長期依賴性。
在上圖的視覺比較中(80幀長度、自回歸生成視訊),StreamingT2V生成長視訊而不會出現運動停滯。
AI長視訊能做什麽
各家都在卷的視訊生成,最直觀的套用場景,可能是電影或者遊戲。
用AI生成的電影片段(Pika,Midjourney,Magnific):
Runway甚至搞了個AI電影節:

不過另一個答案是什麽呢?
世界模型
長視訊創造的虛擬世界,是Agent和人形機器人最好的訓練環境,當然前提是足夠長,也足夠真實(符合物理世界的邏輯)。
也許未來的某一天,那裏也會是我們人類的生存空間。
參考資料:
https://github.com/Picsart-AI-Research/StreamingT2V












