每天都會看很多的開源計畫
這個計畫可能是近期看到最驚艷的一個了 ,讓我迫不及待地想去分享給大家
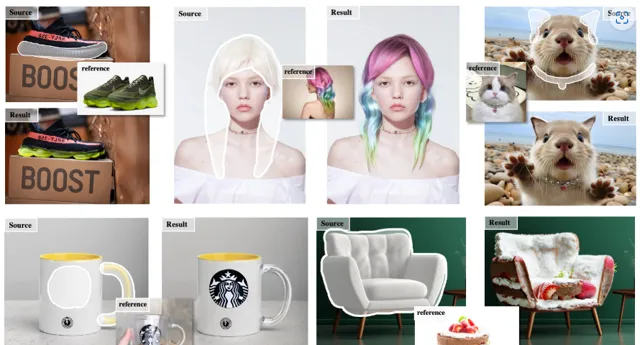
你很難想象自己換發型、換發色會變成什麽樣子,也很難想象一個沙發形狀的蛋糕會是什麽樣,這個最新的開源計畫 MimicBrush 將會滿足你所有的幻想
倒不是說局部重繪有多麽新穎,畢竟大家用的AI繪圖軟體都有這個功能,Mijourney、Stable Diffusion、Dalle3這些都可以,不過重繪也是用AI把這部份重新創造,抽卡把人都抽麻了還得不到自己想要的樣子
而 MimicBrush 讓AI真正的懂了你要重繪的內容 ,讓圖片真的變成你想要的樣子
掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

直接切入主題
我們先來看一段官方的演示視訊
是不是感覺很神奇,
我們腦海裏所有的天馬行空,居然都可以變成可以看得到的影像
最近各地天氣挺熱,恰好我這幾天想買個草帽戴著遮陽,實在是不知道戴上什麽樣,不如就直接用 MimicBrush 實際戴上看看

實際體驗下來還挺有趣的, 試用連結 在下面,你們也可以直接去玩一下
https://huggingface.co/spaces/xichenhku/MimicBrush
這就會有很多 商用場景
比如,發型設計師提前讓顧客看到自己染發後的樣子,賣項鏈的商家可以讓顧客先戴上看看,都可以讓顧客的體驗感更好
這個功能完全可以做成一個軟體,給很多行業的商家都解決了使用者預體驗的問題
下面講點這個開源計畫
專業一些的內容
計畫簡介
MimicBrush 是一個用於零樣本影像編輯的工具,透過參考影像實作高效的影像編輯。
它采用雙 U-Nets 模型,結合穩定擴散和深度模型技術,使使用者能夠對上傳的源影像進行指定區域的編輯,並透過參考影像模仿實作自然過渡。MimicBrush 的核心基於 IP-Adapter 和 MagicAnimate 計畫,提供了靈活的編輯體驗。
方法

MimicBrush的 主要結構包括模仿U-Net、參考U-Net和深度模型:
·模仿U-Net: 基於SD-1.5填充模型,接收13通道的輸入,包括影像潛變量、二進制掩碼、背景潛變量和深度潛變量
·參考U-Net: 從SD-1.5模型初始化,提取參考影像的多級特征,輔助模仿U-Net進行區域填充
·深度模型: 使用Depth Anything預測未掩蓋源影像的深度圖,並透過訓練投影器將其投影到深度潛變量中,作為形狀控制
具體的部署,可以到github連結readme部份去看下,這麽好用的功能,希望可以早點讓更多普通使用者能體驗
計畫連結
https://github.com/ali-vilab/MimicBrush
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新資訊











