點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 機器之心授權
LSTM:這次重生,我要奪回 Transformer 拿走的一切。
20 世紀 90 年代,長短時記憶(LSTM)方法引入了恒定誤差選擇輪盤和門控的核心思想。三十多年來,LSTM 經受住了時間的考驗,並為眾多深度學習的成功案例做出了貢獻。然而,以可並列自註意力為核心 Transformer 橫空出世之後,LSTM 自身所存在的局限性使其風光不再。
當人們都以為 Transformer 在語言模型領域穩坐江山的時候,LSTM 又殺回來了 —— 這次,是以 xLSTM 的身份。
5 月 8 日,LSTM 提出者和奠基者 Sepp Hochreiter 在 arXiv 上傳了 xLSTM 的預印本論文。
論文的所屬機構中還出現了一家叫做「NXAI」的公司,Sepp Hochreiter 表示:「借助 xLSTM,我們縮小了與現有最先進 LLM 的差距。借助 NXAI,我們已開始構建自己的歐洲 LLM。」
論文標題:xLSTM: Extended Long Short-Term Memory
論文連結:https://arxiv.org/pdf/2405.04517
具體來說,xLSTM 從三個層面解決了 LSTM 以往所存在的局限性:
(i) 無法修改儲存決策。
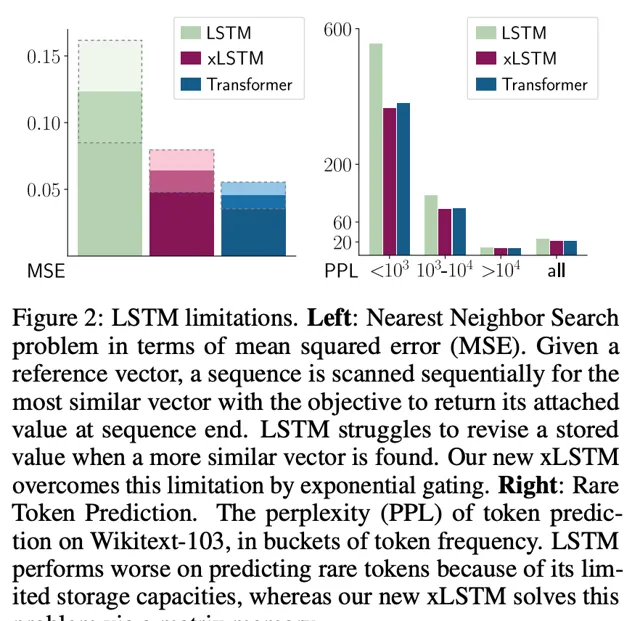
可以透過「最近鄰搜尋」(Nearest Neighbor Search)問題來舉例說明這一局限性:在給定參考向量的情況下,必須按順序掃描序列,尋找最相似的向量,以便在序列末端提供其附加值。圖 2 左側顯示了這項任務的均方誤差。當發現更相似的向量時,LSTM 難以修改儲存的值,而新的 xLSTM 透過指數門控彌補了這一限制。
(ii) 儲存容量有限,即資訊必須壓縮成純量單元狀態。
圖 2 右側給出了 Wikitext103 上不同 token 頻率的 token 預測困惑度。由於 LSTM 的儲存容量有限,它在不常見 token 上的表現較差。xLSTM 透過矩陣記憶體解決了這一問題。
(iii) 由於記憶體混合而缺乏可並列性,需要進行順序處理。例如,從一個時間步到下一個時間步的隱藏狀態之間的隱藏 - 隱藏連線。
與此同時,Sepp Hochreiter 和團隊在這篇新論文中回答了一個關鍵問題: 如果克服這些局限性並將 LSTM 擴充套件到當前大語言模型的規模時,能實作怎樣的效能?
將 LSTM 擴充套件到數十億參數
為了克服 LSTM 的局限性,xLSTM 對等式(1)中的 LSTM 理念進行了兩項主要修改。
在原來的 LSTM 中,恒定誤差選擇輪盤是由單元輸入 z_t 對單元狀態 c_(t-1)(綠色)進行的加法更新,並由 sigmoid 門(藍色)進行調節。輸入門 i_t 和遺忘門 f_t 控制這一更新,而輸出門 o_t 控制儲存單元的輸出,即隱藏狀態 h_t。儲存單元的狀態被 ψ 歸一化或壓縮,然後輸出門控得到隱藏狀態。
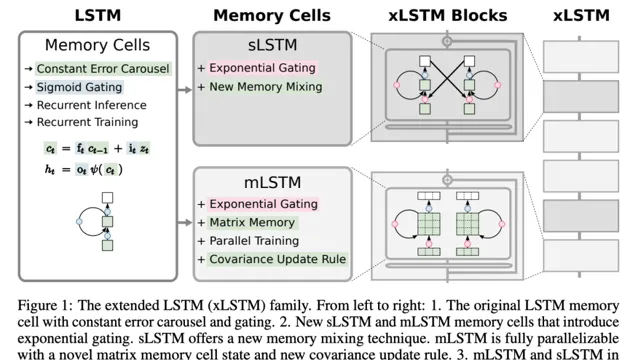
xLSTM 的修改包括指數門控和新穎的記憶體結構,因此豐富了 LSTM 家族的兩個成員:
(i) sLSTM(第 2.2 節),具有純量記憶體、純量更新和記憶體混合功能;
(ii) mLSTM(第 2.3 節),具有矩陣記憶體和共變異數(外積)更新規則,完全可並列處理。
sLSTM 和 mLSTM 都透過指數門控增強了 LSTM。為了實作並列化,mLSTM 放棄了記憶體混合,即隱藏 - 隱藏遞迴連線。mLSTM 和 sLSTM 都可以擴充套件到多個儲存單元,其中 sLSTM 具有跨單元記憶體混合的特點。此外,sLSTM 可以有多個頭,但不存在跨頭的記憶體混合,而只存在每個頭內單元間的記憶體混合。透過引入 sLSTM 頭和指數門控,研究者建立了一種新的記憶體混合方式。對於 mLSTM 而言,多頭和多單元是等價的。
將這些新的 LSTM 變體整合到殘留誤差塊模組中,就得到了 xLSTM 塊。將這些 xLSTM 塊剩余堆疊到架構中,就形成了 xLSTM 架構。xLSTM 架構及其元件見圖 1。
xLSTM 塊應在高維空間中對過去進行非線性總結,以便更好地分離不同的歷史或上下文。分離歷史是正確預測下一個序列元素(如下一個 token)的先決條件。研究者在此采用了 Cover 定理,該定理指出,在高維空間中,非線性嵌入模式比在原始空間中更有可能被線性分離。
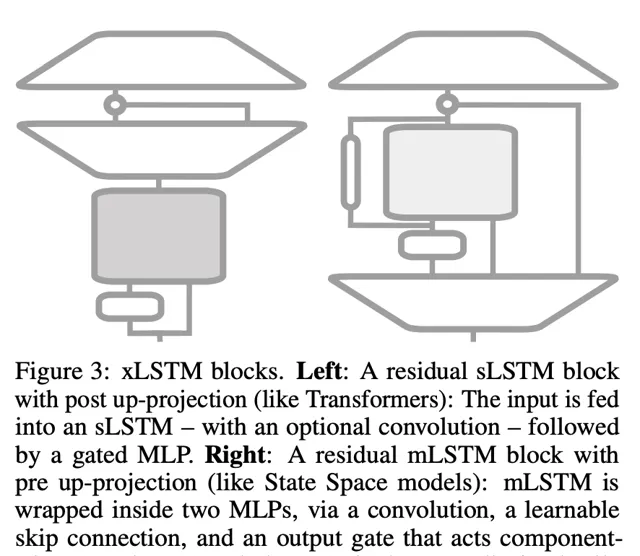
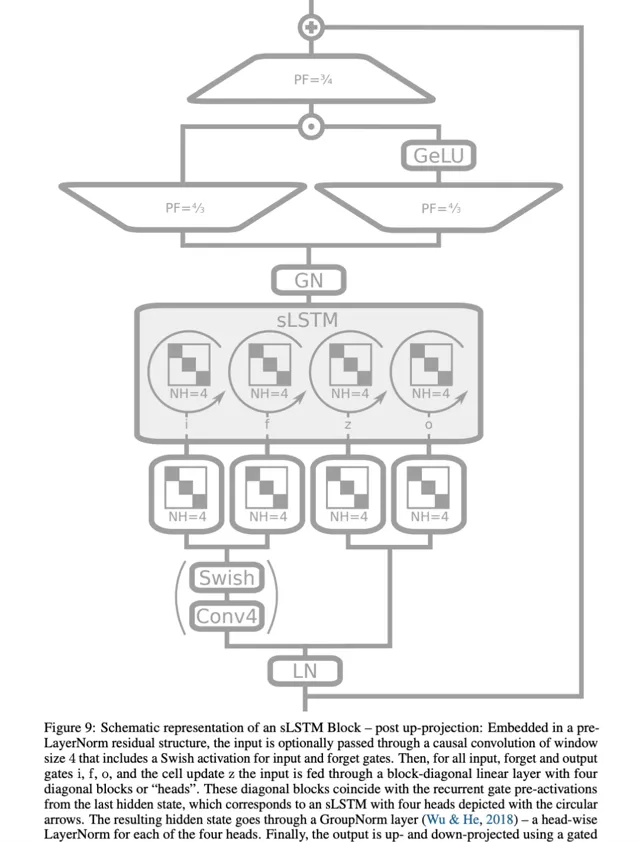
他們考慮了兩種殘留誤差塊結構:(i) post up-projection 的殘留誤差塊(如 Transformer),它非線性地概括了原始空間中的歷史,然後線性地對映到高維空間,套用非線性啟用函式,再線性地對映回原始空間(圖 3 左側和圖 1 第三欄,更詳細的版本見圖 9)。(ii) pre up-projection 的殘留誤差塊(如狀態空間模型),它線性地對映到高維空間,在高維空間中非線性地總結歷史,然後線性地對映回原始空間。對於包含 sLSTM 的 xLSTM 塊,研究者主要使用了 post up-projection 塊。對於包含 mLSTM 的 xLSTM 塊,使用 pre up-projection 塊,因為在高維空間中記憶體容量會變大。
實驗
隨後,研究者對 xLSTM 進行了實驗評估,並將其與現有的語言建模方法進行了比較。
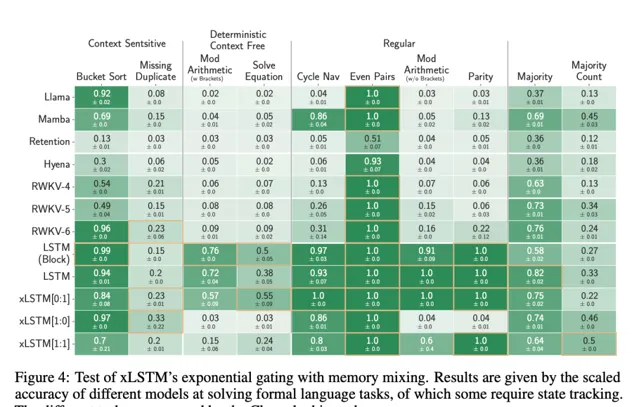
第 4.1 節討論了 xLSTM 在合成任務中的具體能力。首先,研究者測試了 xLSTM 的新指數門控與記憶體混合在形式化語言上的有效性。然後,他們評估了 xLSTM 的新矩陣記憶體在多次查詢聯想記憶任務(Multi-Query Associative Recall,MQAR)中的有效性。最後,研究者評估了 xLSTM 在 Long Range Arena(LRA)中處理長序列的效能。
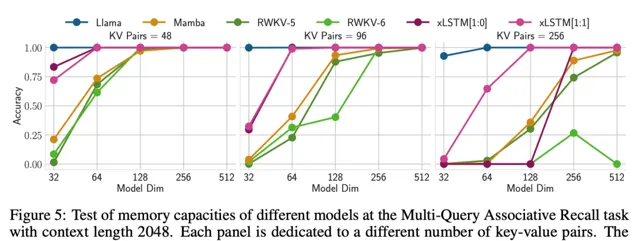
第 4.2 節比較了當前各種語言建模方法的驗證集復雜度,包括在同一數據集上對 xLSTM 進行消融研究,然後對不同方法的縮放行為進行評估。
研究者在自回歸語言建模設定中使用 SlimPajama 的 15B token 訓練了 xLSTM、Transformers、狀態空間模型(SSM)等模型。表 1 中的結果顯示,xLSTM 在驗證復雜度方面優於所有現有方法。
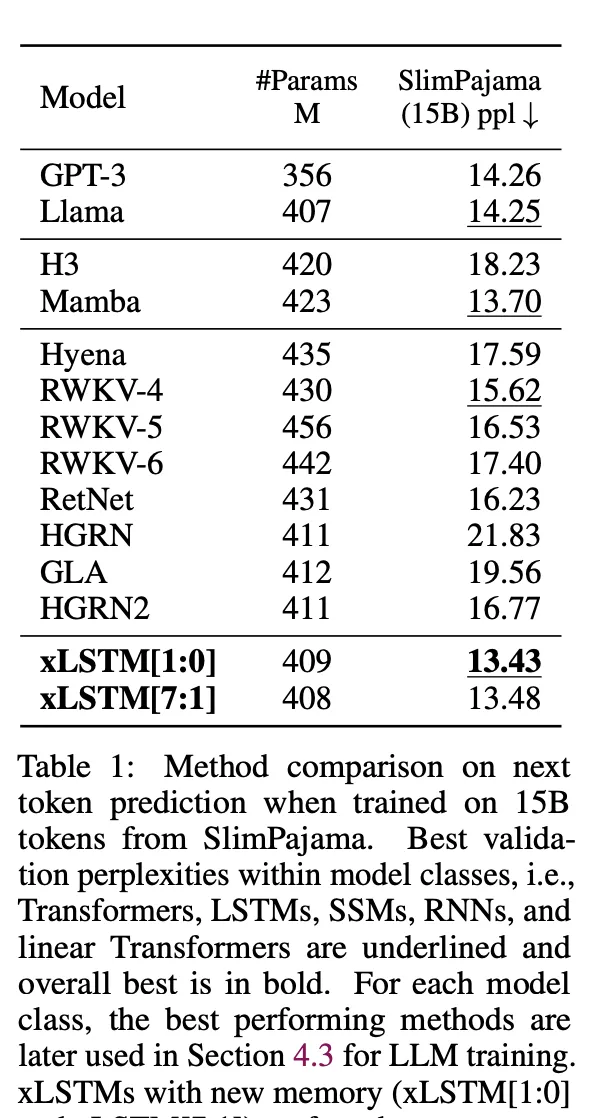
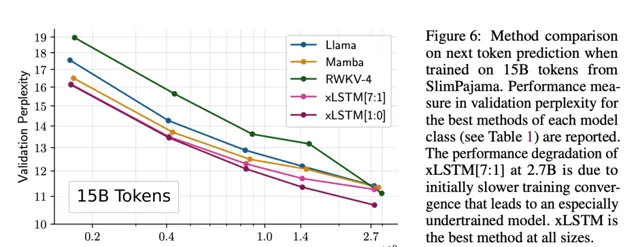
圖 6 顯示了該實驗的擴充套件結果,表明 xLSTM 對於更大規模的模型也有良好的表現。
消融研究則表明,效能改進源於指數門控和矩陣記憶體。

第 4.3 節進行了更深入的語言建模實驗。
研究者增加了訓練數據量,對來自 SlimPajama 的 300B 個 token 進行了訓練,並比較了 xLSTM、RWKV-4、Llama 和 Mamba。他們訓練了不同大小的模型(125M、350M、760M 和 1.3B),進行了深入的評估。首先,評估這些方法在推斷較長語境時的表現;其次,透過驗證易混度和下遊任務的表現來測試這些方法;此外,在 PALOMA 語言基準數據集的 571 個文本域上評估了這些方法;最後,評估了不同方法的擴充套件行為,但使用的訓練數據多了 20 倍。
可以看出,xLSTM 在效能和擴充套件性上都更勝一籌。