RediSearch是一個Redis模組,為Redis提供查詢、二次索引和全文搜尋。
要使用RediSearch,首先要在Redis數據上聲明索引。
然後可以使用重新搜尋查詢語言來查詢該數據。
RedSearch使用壓縮的反向索引進行快速索引,占用記憶體少。RedSearch索引透過提供精確的短語匹配、模糊搜尋和數位過濾等功能增強了
1
實作特性
基於文件的多個欄位全文索引
高效能增量索引
文件排序(由使用者在索引時手動提供)
在子查詢之間使用 AND 或 NOT 操作符的復雜布爾查詢
可選的查詢子句
基於字首的搜尋
支持欄位權重設定
自動完成建議(帶有模糊字首建議)
精確的短語搜尋
在許多語言中基於詞幹分析的查詢擴充套件
支持用於查詢擴充套件和評分的自訂函式
將搜尋限制到特定的文件欄位
數位過濾器和範圍
使用 Redis 自己的地理命令進行地理過濾
Unicode 支持(需要 UTF-8 字元集)
檢索完整的文件內容或只是ID 的檢索
支持文件刪除和更新與索引垃圾收集
支持部份更新和條件文件更新
2
對比 Elasticsearch
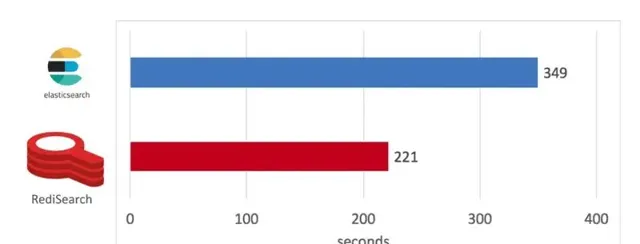
如下圖所示,RediSearch 構建索引的時間為 221 秒,而 Elasticsearch 為 349 秒,快了 58%。
3
索引構建測試
我們模擬了一個多租戶電子商務應用程式,其中每個租戶代表一個產品類別並維護自己的索引。 對於此基準測試,我們構建了 50K 個索引(或產品),每個索引最多儲存 500 個文件(或計畫),總共 2500 萬個文件。
RediSearch 僅用了 201 秒就構建了索引,平均每秒執行 125K 個索引。然而,Elasticsearch 在 921 個索引後崩潰了,顯然它不是為應對這種負載而設計的。

4
查詢效能測試
一旦數據集被索引,我們就使用在專用負載生成器伺服器上執行的 32 個客戶端啟動兩個單詞的搜尋查詢。 如下圖所示,RediSearch 吞吐量達到了 12.5K 操作/秒,而 Elasticsearch 為 3.1K 操作/秒,速度提高了 4 倍。
此外,RediSearch 延遲稍好一些,平均為 8 毫秒,而 Elasticsearch 為 10 毫秒。
5
安裝
安裝目前分為源碼和docker安裝兩種方式。
源碼安裝
git clone https://github.com/RediSearch/RediSearch.git
cd RediSearch # 進入模組目錄
make setup
make install
docker安裝
note: RediSearch的安裝比較復雜原包無法進行編譯操作所以我們使用docker安裝
docker run -p 6379:6379 redislabs/redisearch:latest
判斷是否安裝成功
127.0.0.1:0>modulelist
1) 1) "name"
2) "ReJSON"
3) "ver"
4) "20007"
2) 1) "name"
2) "search"
3) "ver"
4) "20209"
返回陣列存在「ft」或 「search」(不同版本),表明 RediSearch 模組已經成功載入。
6
命令列操作
1、建立
1.1 建立索引
建立索引不妨想象成建立表結構,表一般基本內容有表名、欄位和欄位類別等,所以我們可以考慮將索引名代表表名,欄位代表欄位,內容即表示內容。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0"sex" text "desc" text " class"tag
"OK"
student 表示索引名,name、sex、desc表示欄位,text表示型別(這樣表示只是為了便於理解)
「weight」為權重,預設值為 1.0
type student
"none"
我們建立的索引redis是不認識的,這證明使用的是外掛程式。
1.2 建立文件
建立文件上下文的過程不妨想想成向表中插入數據,這裏請註意欄位名可以使用雙引號但切記一定要用英文,這裏之所以著重提出是因為有些編譯器中文雙引號和英文雙引號用肉眼實在難以辨認否則會出現 「Fields must be specified in FIELD VALUE pairs」(其實是將「 當作內容處理了以至於缺少了欄位)
ft.add student 0011.0language"chinese" fields name "張三" sex "男" desc "這是一個學生" class "一班"
"OK"
其中001為文件ID,"1.0"為評分缺少此值會報"Could not parse document score"異常
language 指明使用的語言預設是英文編碼 如果沒有此標記儲存是沒有問題的但不可以透過中文字元查詢
1.3 查詢
1.3.1 基本查詢
1.3.1.1 全量查詢
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "張三"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
4) "002"
5) 1) "name"
2) "張三"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
1.3.1.2 匹配查詢
xxx.xxx.xxx.xxx:0>ft.search student "張三" limit 010 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "張三"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
4) "002"
5) 1) "name"
2) "張三"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
limit 與mysql相識主要用於分頁,此處是全量匹配,如果沒有設定language 「chinese」 此處查詢為0,
1.3.2 模糊匹配
1.3.2.1 後置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"
2) "李四"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
1.3.2.2 模糊搜尋
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%張店%%"
1) "1"
2) "beer:1"
3) 1) "name"
2) "集團本部已釋出【文明就餐公約】,2號樓辦公人員午餐的就餐時間是11:45~13:00,現經行政服務部進行抽查,發現我們部門有員工違規就餐現象。請大家務必遵守,相互轉告,對於外地回到集團辦公的同事,亦請遵守,謝謝!"
3) "org"
4) "山東省淄博市張店區"
5) "school"
6) "山東理工大學"
別高興太早全量模糊匹配是由很大限制的,他基於Levenshtein距離(LD)進行模糊匹配。術語的模糊匹配是透過在術語周圍加「%」來實作的,模糊匹配的最大LD為3,確切的說這只是一種相識度查詢,並非一般意義上的模糊搜尋,但是如果仔細觀察會發現透過精確匹配時不僅能夠將完整value值查詢出來而且還查詢出其他處於文件某個位置的key請看官方提供的一個例子:
FT.CREATEidxSCHEMAtxtTEXT
FT.ADDidxdocCn 1.0LANGUAGEchineseFIELDStxt
Redis支持主從同步。數據可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層樹復制。從盤可以有意無意的對數據進行寫操作。
由於完全實作了釋出/訂閱機制,使得從資料庫在任何地方同步樹時,可訂閱一個頻道並接收主伺服器完整的訊息釋出記錄。同步對讀取操作的可延伸性和數據冗余很有幫助。
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主從同步。數據可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層樹復制。從盤可以有意無意的對數據進行寫操作。由於完全實作了釋出/訂閱機制,使得從資料庫在任何地方同步樹時,可訂閱一個頻道並接收主伺服器完整的訊息釋出記錄。同步對讀取操作的可延伸性和數據冗余很有幫助。[8]"
FT.SEARCH idx "數據" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>數據</b>?... <b>數據</b>進行寫操作。由於完全實作了釋出... <b>數據</b>冗余很有幫助。[8...
之所以會出現這樣的效果是因為redisearch對文本進行了分詞,其使用的工具是friso相比es的ik還是弱一些前者主要是對中文分詞,體積小可移植性強。
從而我們可以結合後後置匹配演算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "數*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主從同步。<b>數據</b>可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層樹復制。從盤可以有意無意的對<b>數據</b>進行寫操作。由於完全實作了釋出/訂閱機制,使得從資料庫在任何地方同步樹時,可訂閱一個頻道並接收主伺服器完整的訊息釋出記錄。同步對讀取操作的可延伸性和<b>數據</b>冗余很有幫助。[8]"
或者結合Levenshtein演算法這樣基本上能夠滿足業務查詢需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%單的樹%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主從同步。數據可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層<b>樹</b>復制。從盤可以有意無意的對數據進行寫操作。由於完全實作了釋出/訂閱機制,使得從資料庫在任何地方同步<b>樹</b>時,可訂閱一個頻道並接收主伺服器完整的訊息釋出記錄。同步對讀取操作的可延伸性和數據冗余很有幫助。[8]"
1.3.2.3 欄位查詢
透過欄位查詢也可以實作模糊搜尋,直接給例子,後面跟著官網上給的sql 和 redisearch的對照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "「檢索」是很多產品中"
5) "phone"
6) "18563717107"
4) "ttao"
5) 1) "name"
2) "姚元濤"
3) "jtzz"
4) "一個生病的人只"
5) "phone"
6) "18563717107"
ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "「檢索」是很多產品中"
5) "phone"
6) "18563717107"
1.4 刪除
1.3.1 刪除文件
xxx.xxx.xxx.xxx:0>ft.delstudent 002
"1"
1.3.3 刪除索引
xxx.xxx.xxx.xxx:0>ft.dropstudent
"OK"
1.5 檢視
1.5.1 檢視所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"
1.5.2 檢視索引文件中的數據
1.5.2.1 獲取單條數據
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "張三"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
7) " class"
8) "一班"
1.5.2.2 獲取多條數據
xxx.xxx.xxx.xxx:0>ft.mget student 001002
1) 1) "name"
2) "張三"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
7) " class"
8) "一班"
2) 1) "name"
2) "張三"
3) "sex"
4) "男"
5) "desc"
6) "這是一個學生"
7) " class"
8) "一班"
1.6 索引別名操作
1.6.1 添加別名
123.232.112.84:0>FT.ALIASADDxsstudent
"OK"
給索引student起個xs的別名,一個索引可以起多個別名
1.6.2 修改別名
1.6.3 刪除別名
123.232.112.84:0>FT.ALIASDELxs
"OK"
來源:zhuanlan.zhihu.com/p/687400704
>>
END
精品資料,超贊福利,免費領
微信掃碼/長按辨識 添加【技術交流群】
群內每天分享精品學習資料

最近開發整理了一個用於速刷面試題的小程式;其中收錄了上千道常見面試題及答案(包含基礎、並行、JVM、MySQL、Redis、Spring、SpringMVC、SpringBoot、SpringCloud、訊息佇列等多個型別),歡迎您的使用。
👇👇
👇點選"閱讀原文",獲取更多資料(持續更新中)











