大模型的發展已經進入了萬億級參數時代。DeepMind 聯合創始人穆斯塔法・蘇萊曼(Mustafa Suleyman)預測,
僅在未來三年內,大模型規模以驚人的速度繼續擴張,將增長 1000 倍
。
一方面,模型的參數量與其能夠處理和學習的復雜性直接相關。模型容量越大,往往意味著效能越好。隨著模型容量增加到數萬億個參數,大模型可以捕捉更復雜的模式,從而在自然語言處理、電腦視覺和其他任務上表現更好,具備更像人類的能力。
另一方面,隨著計算能力的大幅提升,特別是 GPU 和專用 AI 芯片(如 TPU)的發展,使得訓練更大規模的模型成為可能;新的模型架構和訓練技術的出現,如 Transformer 架構和預訓練技術,使得模型能夠更有效地擴充套件到更大的規模。
此外,模型的大小往往被視為技術創新和研發實力的一種體現。因此,研究和商業機構之間存在一種競爭,推動著模型規模不斷擴大,直到推上萬億級參數量的巔峰。
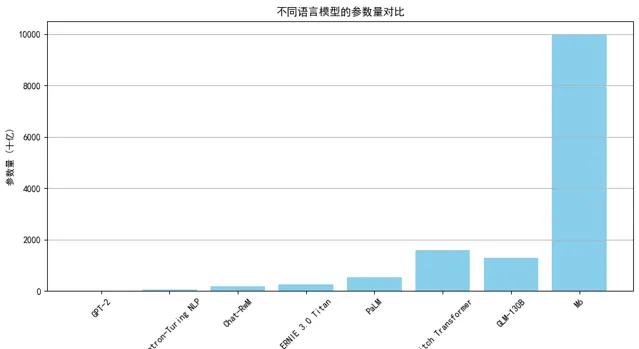
GPT-2 :2019 年釋出的 GPT-2 模型擁有 15 億參數,是當時重要的大型語言模型之一。
Megatron-Turing NLP :由微軟和 NVIDIA 合作開發的 Megatron-Turing NLP 模型,是一個具有 530 億參數的語言模型。
Chat-RwM:Salesforce 研究院釋出的 Chat-RwM 模型,是一個具有 1750 億參數的對話生成模型,專註於多輪對話場景。
ERNIE 3.0 Titan:百度與鵬城自然語言處理聯合實驗室釋出的 ERNIE 3.0 Titan 擁有 2600 億的參數。
PaLM :2022 年,谷歌釋出的 Pathways Language Model(PaLM)模型擁有 5400 億參數。
Switch Transformer :由谷歌釋出的 Switch Transformer 模型,擁有 1.6 萬億參數,用於高效的多工學習。
GLM-130B :智譜開源的 GLM-130B 模型,具有 1.3 萬億參數。
M6:達摩院的多模態預訓練模型 M6,擁有 10 萬億參數。
然而這種大模型之間的軍備競賽,令業內十分擔憂 。
參數量的增加,就一定能帶來顯著的效能提升嗎?不一定。大模型帶來的問題越來越明顯:
計算資源需求巨大:訓練大規模模型需要大量的計算資源,包括高效能 GPU、雲端運算集群等。這對於大多數企業和個人來說,成本高昂。對話式人工智慧模型 Claude 背後的初創公司 Anthropic 認為,在 18 個月內,他們可以構建出比當今最大模型還要強大 10 倍的模型。但是這個 「Claude-Next」 可能需要超過 10 億美元來訓練和執行。
能源消耗:訓練大模型的訓練和執行都要消耗大量能源,並且產生的巨大體量的碳排放。根據 Digital Information World 釋出的報告顯示,OpenAI 訓練 GPT-3 耗電為 1.287 吉瓦時,大約相當於 120 個美國家庭 1 年的用電量。而這僅僅是訓練 AI 模型的前期電力,僅占模型實際使用時所消耗電力的 40%。2023 年 1 月,OpenAI 僅一個月已耗用可能等同 17.5 萬個丹麥家庭的全年用電量。谷歌 AI 每年耗電量達 2.3 太瓦時,相當於亞特蘭大所有家庭 1 年用電量。
不可解釋性:由於 GPT-3、BERT 等大模型具有復雜的結構和數以億計的參數,其內部的決策過程對於人類來說往往是黑箱式的,即難以直接理解。人們難以理解模型為何作出某個預測或生成某段文本,這在一些敏感領域中可能引發問題。
倫理和安全問題:大模型的套用涉及倫理和安全問題,例如偏見、歧視、虛假資訊等。如何對萬億級的大模型進行監管和治理,這在全球都算得上是一個棘手問題。
「我們正在接近大模型規模的極限。規模越大不一定意味著模型越好,很可能只是為了追求一個數位而已。」 去年 4 月,OpenAI 的聯合創始人兼 CEO Sam Altman 在麻省理工學院 「想象力行動」 活動上接受采訪時表示。
他將 LLM 的規模與過去芯片速度的競賽進行了類比,指出今天我們更關註芯片能否完成任務,而不是它們有多快。「規模不再是衡量模型品質的重要指標,未來將有更多的方式來提升模型的能力和效用。」

風向在轉變,小模型正在成為 AI 界的新寵。盡管參數規模較小,卻在成本、效能和實用性方面具備優勢 —— 占記憶體小、反應速度快、可以在地化執行 。
不久前,微軟研究院推出了新一代小型語言模型系列 Phi-3。雖然該模型的參數規模較小,但透過精心設計的訓練數據集和最佳化的演算法,超越了同等大小和稍大一號的模型,在各種語言、推理、編碼和數學基準測試中表現優異。
蘋果緊隨其後,釋出了 OpenELM,包含了 2.7 億、4.5 億、11 億和 30 億四個參數版本。與微軟的 Phi-3 一樣,OpenELM 也是一款專為終端裝置而設計的小模型。
在國內,面壁智慧推出了只有 20 億參數量級的模型 MiniCPM,而其效能卻超過了大參數模型 Mistral-7B,且部份超越 Llama-13B 等,能在在手機等終端上執行,甚至僅靠一塊 CPU 就能運載。
小模型正在不斷證明,它們可以在重點任務上與大模型相媲美,甚至將其擊敗 。其優勢也恰好能補大模型的不足,比如:
計算效率高:小模型相對較小,可以在本地機器上執行模型,訓練和推理速度更快,適用於資源有限的環境。
可解釋性更好:小模型的結構相對簡單,更容易理解其決策過程。
適用範圍廣:小模型可以套用於各種任務,包括嵌入式裝置、行動應用和邊緣計算。
偏見風險低:由於 SLM 在相對較小的特定領域數據集上進行訓練,與 LLM 相比,偏差風險自然較低。
在大多數特定於功能的用例中,比如醫療、法律和金融等領域,小模型可能會表現更加出色。利用這些領域高度專業化的知識訓練小模型,並對其進行微調,可以作為高度監管和專業化行業中特定領域用例的智慧代理。
小模型在邊緣裝置上有著廣泛的套用,如智慧型手機、物聯網裝置和嵌入式系統,這些邊緣裝置通常具有有限的計算能力和儲存空間,它們無法有效地執行大型語言模型。小模型更接近使用者,更個人化,更適合解決實際問題。
一個觀點認為,大模型和小模型都將在未來的 AI 市場中占有一席之地 。具有數萬億參數的大模型將推動通用智慧的新領域,具有數百萬到數十億個參數的專用小模型將處理大多數公司的重點任務。
因此,對於諸多垂直領域的企業而言,或許應該更多地建立自己能夠負擔得起的 「小模型」,透過具備學習能力的 AI 來加速小體量套用場景的體驗更新。
與其將大模型和小型模之爭稱為 「模型之戰」,不如將二者視為互補並滿足不同需求 。學會駕馭這種二分法,或許才能未來幾年把握住 AI 大勢。
如果你還想更進一步了解大模型和小模型如何透過技術手段實作融合,小模型在實際套用中有何成功案例,如何高效、可靠地管理和運維大語言模型,AI 與資料庫等領域的結合會帶來怎樣的變革,多模態大模型有哪些套用與實踐,技術極客在大 AI 浪潮中有什麽創新實踐與經驗,以及未來可能出現的新技術或理論突破等話題,敬請關註 2024 亞太人工智慧與機器人產業峰會暨 GOTC 全球開源技術峰會 。
本次大會將透過 「LLMOps 最佳實踐」「開源資料庫與 AI 協同創新」「多模態大模型的套用與實踐」「硬核 AI 技術創新與實踐」「AI WorkShop,大模型開發者實操營」 等多個論壇及活動,來探索 AI 大模型的最新研究進展及其在實際套用中的挑戰與機遇。
報名 GOTC 2024:
掃碼或長按辨識二維碼
2024 亞太人工智慧與機器人產業峰會暨 GOTC 全球開源技術峰會
由中國人工智慧學會與開源中國聯合舉辦,將於
7 月 13-14 日
在
杭州
隆重舉行。
本次峰會將匯聚全球頂尖的專家、學者、企業領袖及開源技術代表,深入探討機器人技術、軟體開發、開源技術和 AI 大模型等前沿領域。
會議將重點展示機器人在制造、醫療、物流和服務等行業的最新套用,探討智慧演算法和自主學習能力如何提升機器人效能,並分享開源技術在推動技術創新與協作中的關鍵作用。
此外,峰會還將關註 AI 大模型的最新研究進展及其在實際套用中的挑戰與機遇。
透過主題演講、圓桌討論、技術展示和互動工作坊,與會者將有機會交流實踐經驗,探索前沿技術,促進跨領域合作,共同推動人工智慧與機器人技術的發展。

Reference
https://my.oschina.net/u/3859945/blog/11213589
END
熱門文章
-
-
-
-
-












