今天的這個計畫牛!
現在市面上有很多複制數位人,也就是用音訊驅動圖片、視訊。
但實際上只是驅動了口型,並不是完全意義上的數位人。至少開源的類似計畫沒有見到過對動作最佳化的很好的,如果有的話你也可以在評論區告訴大家。
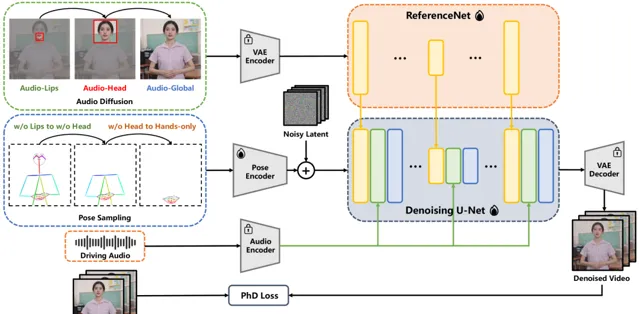
螞蟻集團把EchoMimic計畫升級了,EchoMimic是一個音訊驅動圖片的計畫。這幾天開源了EchoMimicV2,做了一個很大的升級, 現在可以驅動半身的照片了,而且有了肢體動作,還有一點很重要,它對生成的手做了特殊最佳化! 如果參考圖中沒有手或者手部變形,就會重新生成一個高品質的手。

掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

計畫簡介
EchoMimicV2是螞蟻集團開源的音訊驅動半身人體動畫生成技術,它透過簡化的條件來實作高品質的動畫效果。該計畫利用音訊姿態動態協調策略(APDH),透過音訊和姿態的精細調節,顯著降低了姿態條件的冗余,同時增強了動畫的表現力和細節品質。EchoMimicV2還引入了頭部偏註意力機制來強化半身數據的面部表情,無需額外模組即可提升動畫的自然性和表達力。
DEMO
先看下EchoMimicV1版本的效果,只是驅動了口型,類似計畫很多。
V2版本實在是太給力了!
對中文也做了特殊的最佳化。
技術特點
1.音訊姿態動態協調(APDH): EchoMimicV2核心的APDH策略,透過動態調整音訊和姿態輸入,最佳化了條件復雜性。這一策略包括姿態采樣和音訊擴散兩個主要環節,使得音訊不僅控制口部動作,還能擴充套件到整個半身的動畫表現,實作更加和諧的視聽一致性。

2. 用於數據增強的 頭部偏註意力(HPA)機制: 為了解決半身動畫數據稀缺的問題,EchoMimicV2采用了頭部偏註意力機制。透過這一機制,可以在不增加額外計算負擔的情況下,將面部表情的細節加以強化,提高動畫的真實感和表現力。EchoMimicV2能夠無縫地利用已有的頭像數據增強訓練集,增強模型對半身影像中面部表情的學習和再現能力,無需依賴於額外的數據處理模組。
3.階段特定去噪損失(PhD Loss): 該技術透過定義不同的去噪階段,為每個階段客製了特定的損失函式,包括姿態主導損失、細節主導損失和低階別損失。這種分階段的最佳化方法,確保了動畫在動作表現、細節豐富性和視覺品質上的均衡提升。

計畫連結
https://www.dongaigc.com/p/antgroup/echomimic_v2
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新資訊
關註「 向量光年 」公眾號
加速全行業向AI轉變











