點選「 IT碼徒 」, 關註,置頂 公眾號
每日技術幹貨,第一時間送達!
1
MySQL索引
MySQL支持諸多儲存引擎,而各種儲存引擎對索引的支持也各不相同,因此MySQL資料庫支持多種索引型別,如BTree索引,哈希索引,全文索引等等。
為了避免混亂,本文將只關註於BTree索引,因為這是平常使用MySQL時主要打交道的索引。
MySQL官方對索引的定義為:索引(Index)是幫助MySQL高效獲取數據的數據結構。提取句子主幹,就可以得到索引的本質: 索引是 數據結構。
MySQL索引原理
索引目的
索引的目的在於提高查詢效率,可以類比字典,如果要查「mysql」這個單詞,我們肯定需要定位到m字母,然後從下往下找到y字母,再找到剩下的sql。
如果沒有索引,那麽你可能需要把所有單詞看一遍才能找到你想要的,如果我想找到m開頭的單詞呢?或者ze開頭的單詞呢?是不是覺得如果沒有索引,這個事情根本無法完成?
咱們去圖書館借書也是一樣,如果你要借某一本書,一定是先找到對應的分類科目,再找到對應的編號,這是生活中活生生的例子,通用索引,可以加快查詢速度,快速定位。
索引原理
所有索引原理都是一樣的,透過不斷的縮小想要獲得數據的範圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是我們總是透過同一種尋找方式來釘選數據。
資料庫也是一樣,但顯然要復雜許多,因為不僅面臨著等值查詢,還有範圍查詢(>、<、between)、模糊查詢(like)、聯集查詢(or)、多值匹配(in【in本質上屬於多個or】)等等。資料庫應該選擇怎麽樣的方式來應對所有的問題呢?
我們回想字典的例子,能不能把數據分成段,然後分段查詢呢?
最簡單的如果1000條數據,1到100分成第一段,101到200分成第二段,201到300分成第三段……
這樣查第250條數據,只要找第三段就可以了,一下子去除了90%的無效數據。
但如果是1千萬的記錄呢,分成幾段比較好?
稍有演算法基礎的同學會想到搜尋樹,其平均復雜度是lgN,具有不錯的查詢效能。
但這裏我們忽略了一個關鍵的問題,復雜度模型是基於每次相同的操作成本來考慮的,資料庫實作比較復雜,數據保存在磁盤上,而為了提高效能,每次又可以把部份數據讀入記憶體來計算,因為我們知道存取磁盤的成本大概是存取記憶體的十萬倍左右,所以簡單的搜尋樹難以滿足復雜的套用場景。
索引結構
任何一種數據結構都不是憑空產生的,一定會有它的背景和使用場景,我們現在總結一下,我們需要這種數據結構能夠做些什麽
其實很簡單,那就是:每次尋找數據時把磁盤IO次數控制在一個很小的數量級,最好是常數數量級。那麽我們就想到如果一個高度可控的多路搜尋樹是否能滿足需求呢?
就這樣,b+樹應運而生。
b+樹的索引結構解釋
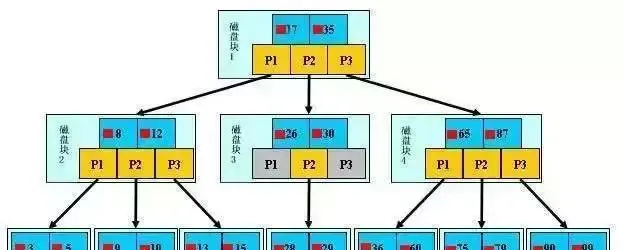
淺藍色的塊我們稱之為一個磁盤塊,可以看到每個磁盤塊包含幾個數據項(深藍色所示)和指標(黃色所示)
如磁盤塊1包含數據項17和35,包含指標P1、P2、P3,P1表示小於17的磁盤塊,P2表示在17和35之間的磁盤塊,P3表示大於35的磁盤塊。
真實的數據存在於葉子節點即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非葉子節點不儲存真實的數據,只儲存指引搜尋方向的數據項,如17、35並不真實存在於數據表中。
b+樹的尋找過程
如圖所示,如果要尋找數據項29,那麽首先會把磁盤塊1由磁盤載入到記憶體,此時發生一次IO,在記憶體中用二分尋找確定29在17和35之間,釘選磁盤塊1的P2指標,記憶體時間因為非常短(相比磁盤的IO)可以忽略不計
透過磁盤塊1的P2指標的磁盤地址把磁盤塊3由磁盤載入到記憶體,發生第二次IO,29在26和30之間,釘選磁盤塊3的P2指標
透過指標載入磁盤塊8到記憶體,發生第三次IO,同時記憶體中做二分尋找找到29,結束查詢,總計三次IO。
真實的情況是,3層的b+樹可以表示上百萬的數據,如果上百萬的數據尋找只需要三次IO,效能提高將是巨大的
如果沒有索引,每個數據項都要發生一次IO,那麽總共需要百萬次的IO,顯然成本非常非常高。
b+樹性質
1、透過上面的分析,我們知道間越小,數據項的數量越多,樹的高度越低。
這就是為什麽每個數據項,即索引欄位要盡量的小,比如int占4字節,要比bigint8字節少一半。
這也是為什麽b+樹要求把真實的數據放到葉子節點而不是內層節點,一旦放到內層節點,磁盤塊的數據項會大振幅下降,導致樹增高。當數據項等於1時將會退化成線性表。
2、當b+樹的數據項是復合的數據結構,比如(name,age,sex)的時候,b+數是按照從左到右的順序來建立搜尋樹的,比如當(張三,20,F)這樣的數據來檢索的時候,b+樹會優先比較name來確定下一步的所搜方向,如果name相同再依次比較age和sex,最後得到檢索的數據
但當(20,F)這樣的沒有name的數據來的時候,b+樹就不知道下一步該查哪個節點,因為建立搜尋樹的時候name就是第一個比較因子,必須要先根據name來搜尋才能知道下一步去哪裏查詢。
比如當(張三,F)這樣的數據來檢索時,b+樹可以用name來指定搜尋方向,但下一個欄位age的缺失,所以只能把名字等於張三的數據都找到,然後再匹配性別是F的數據了
這個是非常重要的性質,即索引的最左匹配特性。
MySQL 索引實作
在MySQL中,索引屬於儲存引擎級別的概念,不同儲存引擎對索引的實作方式是不同的,本文主要討論MyISAM和InnoDB兩個儲存引擎的索引實作方式。
MyISAM索引實作
MyISAM引擎使用B+Tree作為索引結構,葉節點的data域存放的是數據記錄的地址。
下圖是MyISAM索引的原理圖:
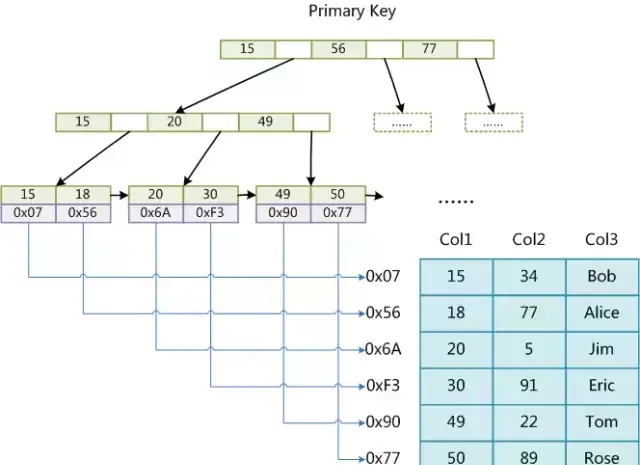
這裏設表一共有三列,假設我們以Col1為主鍵,則上圖便是一個MyISAM表的主索引(Primary key)示意圖。
可以看出MyISAM的索引檔僅僅保存數據記錄的地址。在MyISAM中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重復。
如果我們在Col2上建立一個輔助索引,則此索引的結構如下圖所示:
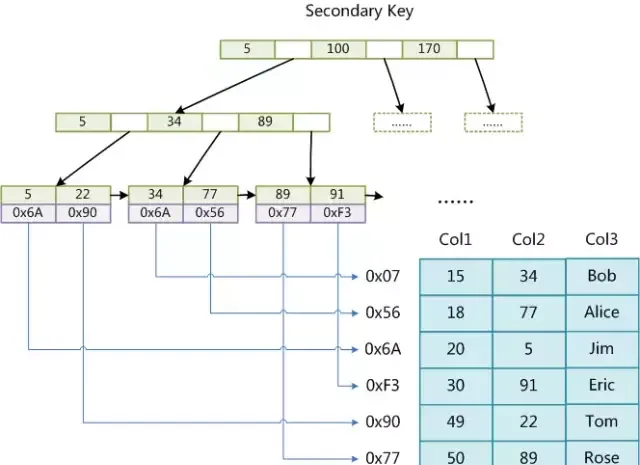
同樣也是一顆B+Tree,data域保存數據記錄的地址。因此,MyISAM中索引檢索的演算法為首先按照B+Tree搜尋演算法搜尋索引,如果指定的Key存在,則取出其data域的值,然後以data域的值為地址,讀取相應數據記錄。
MyISAM的索引方式也叫做「非聚集」的,之所以這麽稱呼是為了與InnoDB的聚集索引區分。
InnoDB索引實作
雖然InnoDB也使用B+Tree作為索引結構,但具體實作方式卻與MyISAM截然不同。
第一個重大區別是InnoDB的數據檔本身就是索引檔。
從上文知道,MyISAM索引檔和數據檔是分離的,索引檔僅保存數據記錄的地址。
而在InnoDB中,表數據檔本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據檔本身就是主索引。
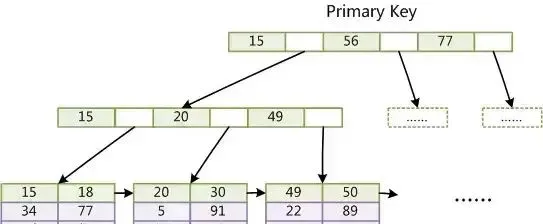
上圖是InnoDB主索引(同時也是數據檔)的示意圖,可以看到葉節點包含了完整的數據記錄,這種索引叫做聚集索引。
因為InnoDB的數據檔本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有)
如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含欄位作為主鍵,這個欄位長度為6個字節,型別為長整形。
第二個與MyISAM索引的不同是InnoDB的輔助索引data域儲存相應記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都參照主鍵作為data域。例如,下圖為定義在Col3上的一個輔助索引:
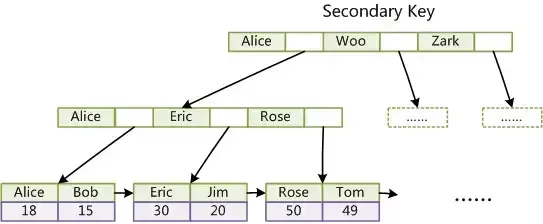
這裏以英文字元的ASCII碼作為比較準則。聚集索引這種實作方式使得按主鍵的搜尋十分高效,但是輔助索引搜尋需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然後用主鍵到主索引中檢索獲得記錄。
了解不同儲存引擎的索引實作方式對於正確使用和最佳化索引都非常有幫助,例如知道了InnoDB的索引實作後,就很容易明白為什麽不建議使用過長的欄位作為主鍵,因為所有輔助索引都參照主索引,過長的主索引會令輔助索引變得過大。
再例如,用非單調的欄位作為主鍵在InnoDB中不是個好主意,因為InnoDB數據檔本身是一顆B+Tree,非單調的主鍵會造成在插入新記錄時數據檔為了維持B+Tree的特性而頻繁的分裂調整,十分低效,而使用自增欄位作為主鍵則是一個很好的選擇。
2
如何建立合適的索引
建立索引的原理
一個最重要的原則是最左字首原理,在提這個之前要先說下聯合索引,MySQL中的索引可以以一定順序參照多個列,這種索引叫做聯合索引
一般的,一個聯合索引是一個有序元組,其中各個元素均為數據表的一列。另外,單列索引可以看成聯合索引元質數為1的特例。
索引匹配的最左原則具體是說,假如索引列分別為A,B,C,順序也是A,B,C:
那麽查詢的時候,如果查詢【A】【A,B】 【A,B,C】,那麽可以透過索引查詢
如果查詢的時候,采用【A,C】,那麽C這個雖然是索引,但是由於中間缺失了B,因此C這個索引是用不到的,只能用到A索引
如果查詢的時候,采用【B】 【B,C】 【C】,由於沒有用到第一列索引,不是最左字首,那麽後面的索引也是用不到了
如果查詢的時候,采用範圍查詢,並且是最左字首,也就是第一列索引,那麽可以用到索引,但是範圍後面的列無法用到索引
因為索引雖然加快了查詢速度,但索引也是有代價的:索引檔本身要消耗儲存空間,同時索引會加重插入、刪除和修改記錄時的負擔,另外,MySQL在執行時也要消耗資源維護索引,因此索引並不是越多越好
在使用InnoDB儲存引擎時,如果沒有特別的需要,請永遠使用一個與業務無關的自增欄位作為主鍵。如果從資料庫索引最佳化角度看,使用InnoDB引擎而不使用自增主鍵絕對是一個糟糕的主意。
InnoDB使用聚集索引,數據記錄本身被存於主索引(一顆B+Tree)的葉子節點上。這就要求同一個葉子節點內(大小為一個記憶體頁或磁盤頁)的各條數據記錄按主鍵順序存放
因此每當有一條新的記錄插入時,MySQL會根據其主鍵將其插入適當的節點和位置,如果頁面達到裝載因子(InnoDB預設為15/16),則開辟一個新的頁(節點)。
如果表使用自增主鍵,那麽每次插入新的記錄,記錄就會順序添加到當前索引節點的後續位置,當一頁寫滿,就會自動開辟一個新的頁。如下:
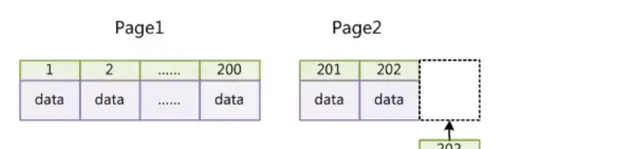
這樣就會形成一個緊湊的索引結構,近似順序填滿。由於每次插入時也不需要移動已有數據,因此效率很高,也不會增加很多開銷在維護索引上。
如果使用非自增主鍵(如果身份證號或學號等),由於每次插入主鍵的值近似於隨機,因此每次新紀錄都要被插到現有索引頁得中間某個位置,如下:
此時MySQL不得不為了將新記錄插到合適位置而行動資料,甚至目標頁面可能已經被回寫到磁盤上而從緩存中清掉
此時又要從磁盤上讀回來,這增加了很多開銷,同時頻繁的移動、分頁操作造成了大量的碎片,得到了不夠緊湊的索引結構,後續不得不透過OPTIMIZE TABLE來重建表並最佳化填充頁面。
因此,只要可以,請盡量在InnoDB上采用自增欄位做主鍵。
建立索引的常用技巧
1、最左字首匹配原則,非常重要的原則,mysql會一直向右匹配直到遇到範圍查詢(>、<、between、like)就停止匹配
比如a 1="" and="" b="2" c=""> 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。
2、=和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢最佳化器會幫你最佳化成索引可以辨識的形式
3、盡量選擇區分度高的列作為索引,區分度的公式是count(distinct col)/count( * ) ,表示欄位不重復的比例,比例越大我們掃描的記錄數越少,唯一鍵的區分度是1,而一些狀態、性別欄位可能在大數據面前區分度就是0
那可能有人會問,這個比例有什麽經驗值嗎?使用場景不同,這個值也很難確定,一般需要join的欄位我們都要求是0.1以上,即平均1條掃描10條記錄
4、索引列不能參與計算,保持列「幹凈」,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引
原因很簡單,b+樹中存的都是數據表中的欄位值,但進行檢索時,需要把所有元素都套用函式才能比較,顯然成本太大。所以語句應該寫成create_time = unix_timestamp(’2014-05-29’);
5、盡量的擴充套件索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那麽只需要修改原來的索引即可,當然要考慮原有數據和線上使用情況。
— END —
PS:防止找不到本篇文章,可以收藏點贊,方便翻閱尋找哦。
往期推薦











