
「給你一瓶魔法藥水
喝下去就不怕身體結冰
輕輕念著你懂的咒語
一扇門就通往
銀河系」
——————【給你一瓶魔法藥水】
告五人
潞晨雲上新SD3映像!低價實作dream畫面再也不是夢
近日SD模型迎來重磅更新,網友們都開始玩起了接力大賽。例如從下面這幾幅「1girl,在錯誤的方向上攔出租車,紐約」 能看出SD3模型對AI繪圖不會畫手的問題做了很好的修復,目前已經能很好
處理手部細節
。
網友評價:「看,媽媽,我有一只功能齊全的手!」

透過SD3,你可以輕松實作腦海中天馬行空的創意:
想 融合大師的畫風 嗎?無論是梵高、畢加索、達芬奇與林布蘭的混搭,還是大衛·霍克尼與莫奈的融合,SD3都能輕松駕馭,讓你成為大師之上的大師!


還想看到Hello Kitty、Snoopy、Garfield和Homer Simpson等動畫角色的大亂鬥嗎?用 SD3創造你自己的動畫故事集 吧!


Stability AI 的 Stable Diffusion 家族最新成員——Stable Diffusion 3 (SD3) 現已登陸潞晨雲。潞晨雲平台支持一鍵呼叫,提供全網最低算力租賃價格,搭配高端GPU機型H800和A800,等你來體驗!

潞晨雲網址: https://cloud.luchentech.com
潞晨雲ComfyUI with SD3 映像操作教程
1.為機器添加 ssh 公鑰
#本地terminal輸入cd /root/.ssh
#本地terminal 輸入nano authorized_keys
在潞晨雲「雲主機」頁面,點選 「添加新SSH公鑰」 添加 public key 後保存
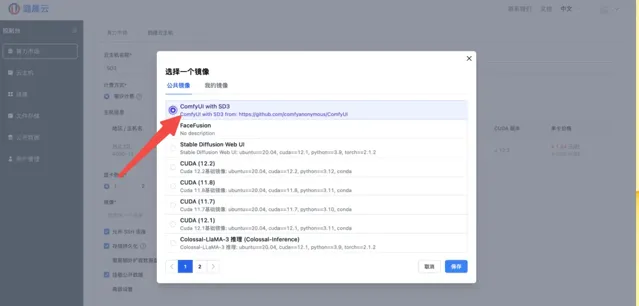
在算力市場選擇GPU(推薦使用1卡4090),並選擇 「ComfyUI with SD3」 映像
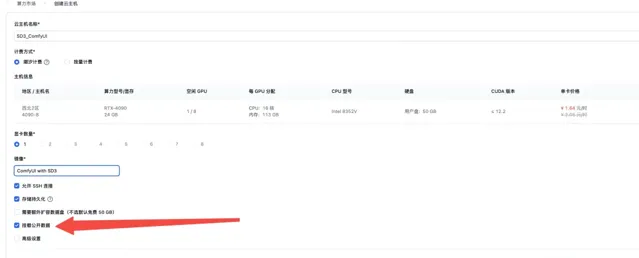
勾選 「掛載公開數據」
2.本映像已預選內建 ComfyUI 程式碼,詳細路徑可見:
/root/ComfyUI
#存取指定資料夾cd /root/ComfyUI
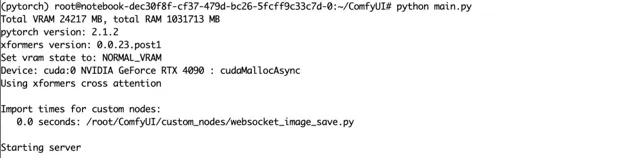
#執行python main.py
執行成功後可以看到以下界面
3.開放本地口,登入ComfyUI開始作畫:
a.雲主機界面復制並保留 ssh 連線方式
#本地 terminal輸入ssh -CNg -L 8003:127.0.0.1:8188 root@雲主機地址 -p
b.本地瀏覽器開啟: http://localhost:8003/
可看到以下界面:
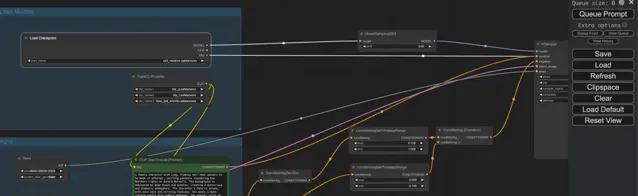
ComfyUI 需手動添加 workflow,可登入 Huggingface 自行下載: https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main/comfy_example_workflows (填寫基礎資訊後即可看到下載頁面)。
也可在 /root/commonData/stable-diffusion-3-medium/comfy_example_workflows 獲取。
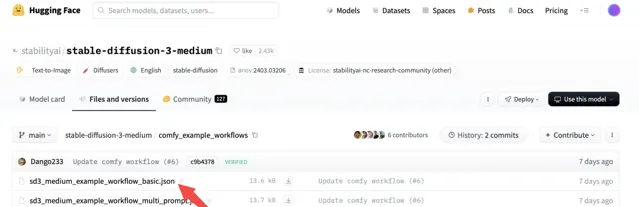
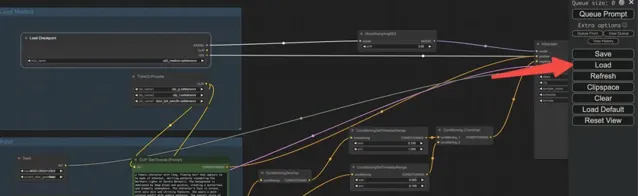
如上圖 點選 load 載入 sd3_medium_example_workflow_basic.json 這個 workflow。
在 load Checkpoint 中選擇 sd3 medium。

輸入 Prompt,Negative prompt 等,點選右側 Queue Prompt。
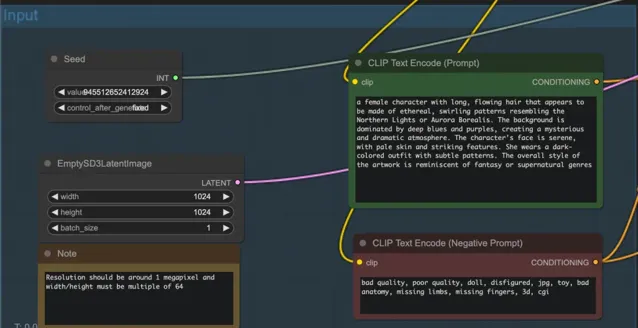

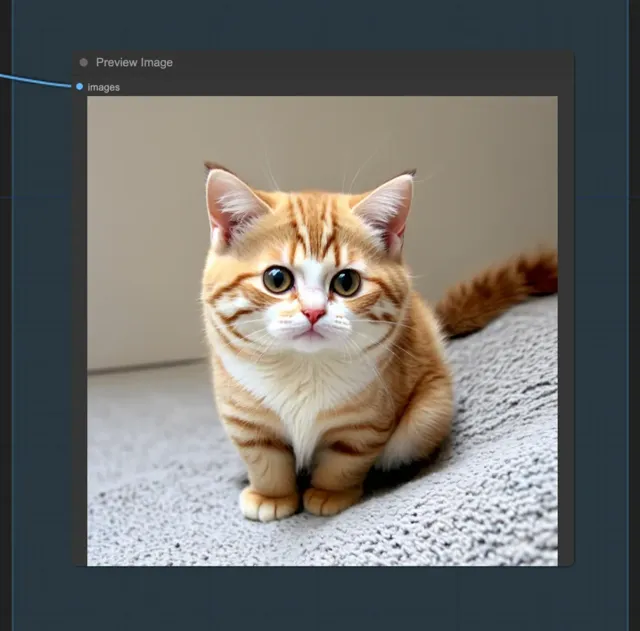
等待片刻,即可收到生成的圖片,如生成一只可愛的貓咪:
SD3技術介紹
Stable Diffusion 3 更新
SD3采用新的多模態擴散變換器 (MMDiT) 架構對影像和語言表示使用單獨的權重集,與以前版本的穩定擴散相比提高了文本理解和拼寫能力。同時使用的重新加權的 Rectified Flow模型、引入了T5-XXL來作為text encoder等進一步提升模型的文本理解能力。
Stable Diffusion 3 模型在基於人類對視覺美學、在文字渲染和對文本提示詞的遵循上,已經達到甚至超過目前STOA的文生圖模型如DALL·E 3、Midjourney v6和Ideogram v1
SD3 最大的亮點在於采用了一種稱為 Diffusion Transformer(MMDiT) 的全新架構,取代了傳統的 U-Net 主幹網路。 不同於 U-Net 對影像進行特征提取, Diffusion Transformer 將影像分割成一個個小方塊(修補程式),並將它們轉換為一系列向量表示這一架構對影像和語言表示使用單獨的權重集。 這一架構對影像和語言表示使用單獨的權重集,與之前版本的穩定擴散相比,它提高了文本理解和拼寫能力,使使用者可以非常精準地控制需要出現在圖片中地文字內容,有望帶來更高品質和更多樣化的影像生成結果。
另一個新功能是條件流匹配 (Conditional Flow Matching), 這一技術可以使 AI 影像生成過程中的指令控制更加精細和同步。傳統上,生成式 AI 系統很難對整個生成過程實作全域控制,因為它們是混沌系統,難以達到完全平衡。條件流匹配為不同生成步驟之間的協調提供了新的可能性。也因此,新模型能夠生成更加以假亂真的逼真圖片,對於完全虛構的圖片也能做到美學和細節真實度的統一,對於人物,面部細節也更加真實手也近乎沒有瑕疵了。
模型核心構架
SD3的核心技術在於StabilityAI 開發的MMDiT技術。
來源:官網
模型使用三種不同的文本嵌入器(兩個 CLIP 模型和 T5)來編碼文本表示,並使用改進的自動編碼模型來編碼影像編碼影像token。這個構架的核心,采用的是和Sora一樣的DiT技術。
由於文本和影像Embedding在概念上存在顯著差異, 因此他們對這兩種模式使用兩組獨立的權重。相當於為每種模態分配了獨立的轉換器,但是將兩種模態的序列連線起來進行註意力操作,這樣兩種表征都可以在自己的空間中工作,同時考慮另一種表征。基於這種特殊架構,MMDiT的效能超越了傳統UViT或DiT模型。該方法使資訊可在影像和文本標記間流動,提高生成輸出的整體理解和排版品質。此架構還可輕松擴充套件至視訊等多模態場景。再加上SD3改進的提示跟隨能力,模型能建立聚焦於不同主題和品質要求的影像,同時保持對影像風格的高度靈活性。
特別活動
【百萬補貼】 優質線上算力資源百萬補貼等你來薅,隨開隨用。
【企業認證】 企業使用者參與潞晨雲企業認證可得500元代金券(有效期一月)。
【分享有禮】 使用者在社交媒體和專業論壇(如知乎、小紅書、微博、CSDN等)上分享使用體驗,有效分享一次可得100元代金券(有效期一周)。
【使用者社群】 不定時發放特價資源、代金券等優惠活動。
參考連結:SD3官方技術報告: https://github.com/mini-sora/minisora/blob/main/notes/SD3_zh-CN.md











