Spring 如何解決迴圈依賴,網上的資料很多,但是感覺寫得好的極少,特別是源碼解讀方面.
不 BB,上文章目錄。
1. 基礎知識
1.1 什麽是迴圈依賴 ?
一個或多個物件之間存在直接或間接的依賴關系,這種依賴關系構成一個環形呼叫,有下面 3 種方式。
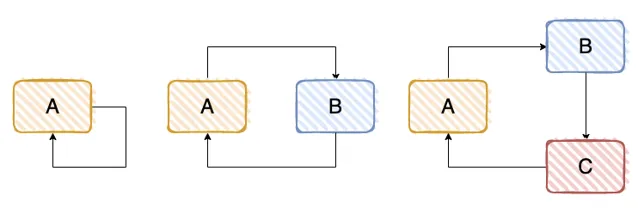
我們看一個簡單的 Demo,對標「情況 2」。
@Service
public classLouzai1{
@Autowired
private Louzai2 louzai2;
publicvoidtest1(){
}
}
@Service
public classLouzai2{
@Autowired
private Louzai1 louzai1;
publicvoidtest2(){
}
}
這是一個經典的迴圈依賴,它能正常執行,後面我們會透過源碼的角度,解讀整體的執行流程。
1.2 三級緩存
解讀源碼流程之前,spring 內部的三級緩存邏輯必須了解,要不然後面看程式碼會蒙圈。
第一級緩存 :singletonObjects,用於保存例項化、註入、初始化完成的 bean 例項;
第二級緩存 :earlySingletonObjects,用於保存例項化完成的 bean 例項;
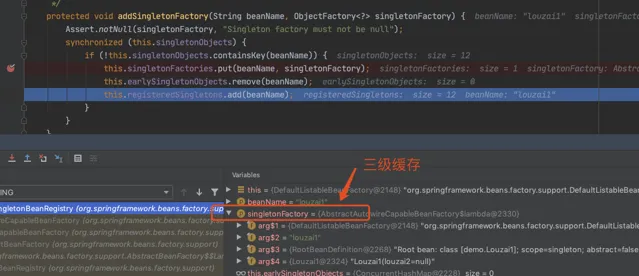
第三級緩存 :singletonFactories,用於保存 bean 建立工廠,以便後面有機會建立代理物件。
這是最核心,我們直接上源碼:
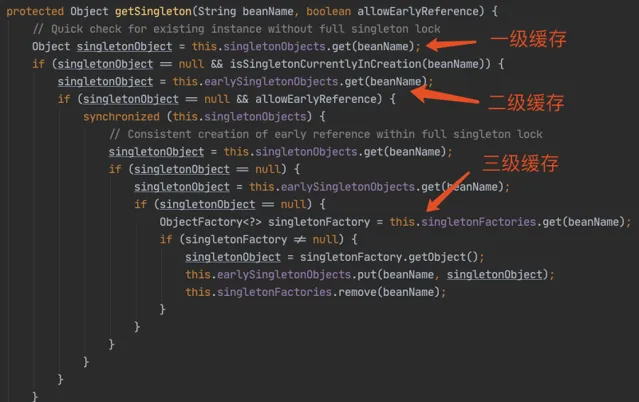
執行邏輯:
先從「第一級緩存」找物件,有就返回,沒有就找「二級緩存」;
找「二級緩存」,有就返回,沒有就找「三級緩存」;
找「三級緩存」,找到了,就獲取物件,放到「二級緩存」,從「三級緩存」移除。
1.3 原理執行流程
我把「情況 2」執行的流程分解為下面 3 步,是不是和「套娃」很像 ?
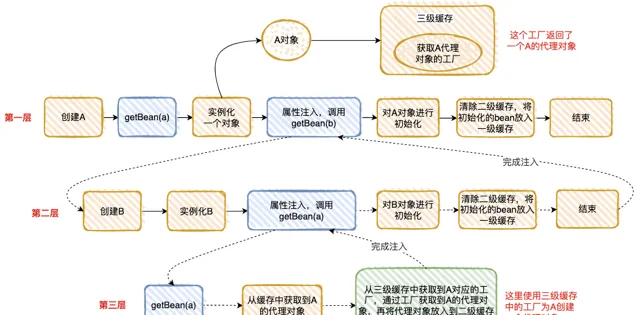
整個執行邏輯如下:
在第一層中,先去獲取 A 的 Bean,發現沒有就準備去建立一個,然後將 A 的代理工廠放入「三級緩存」( 這個 A 其實是一個半成品,還沒有對裏面的內容進行註入 ),但是 A 依賴 B 的建立,就必須先去建立 B;
在第二層中,準備建立 B,發現 B 又依賴 A,需要先去建立 A;
在第三層中,去建立 A,因為第一層已經建立了 A 的代理工廠, 直接從「三級緩存」中拿到 A 的代理工廠,獲取 A 的代理物件,放入「二級緩存」 ,並清除「三級緩存」;
回到第二層,現在有了 A 的代理物件,對 A 的依賴完美解決( 這裏的 A 仍然是個半成品 ),B 初始化成功;
回到第一層,現在 B 初始化成功,完成 A 物件的內容註入,然後再填充 A 的其它內容,以及 A 的其它步驟(包括 AOP),完成對 A 完整的初始化功能( 這裏的 A 才是完整的 Bean )。
將 A 放入「一級緩存」。
為什麽要用 3 級緩存 ?我們先看源碼執行流程,後面我會給出答案。
2. 源碼解讀
註意:Spring 的版本是 5.2.15.RELEASE ,否則和我的程式碼不一樣!!!
上面的知識,網上其實都有,下面才是我們的重頭戲,讓你跟著樓仔,走一遍程式碼流程。
2.1 程式碼入口
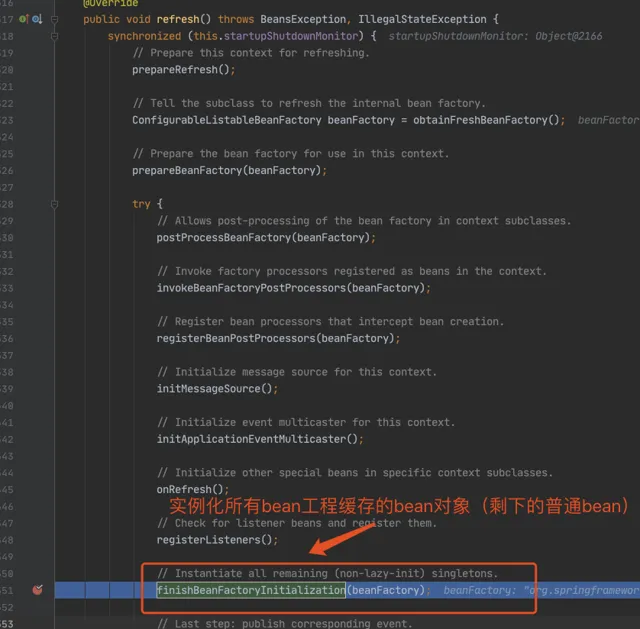
這裏需要多跑幾次,把前面的 beanName 跳過去,只看 louzai1。
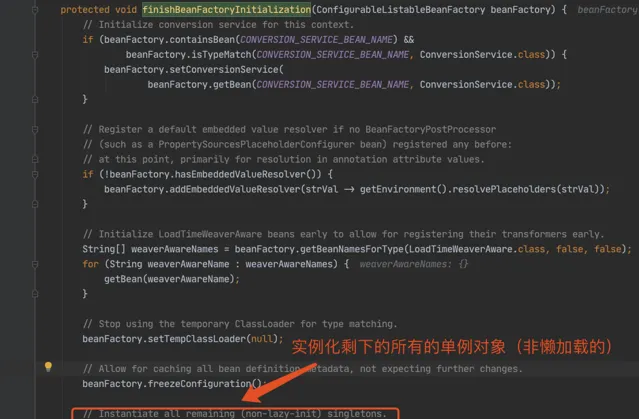
2.2 第一層

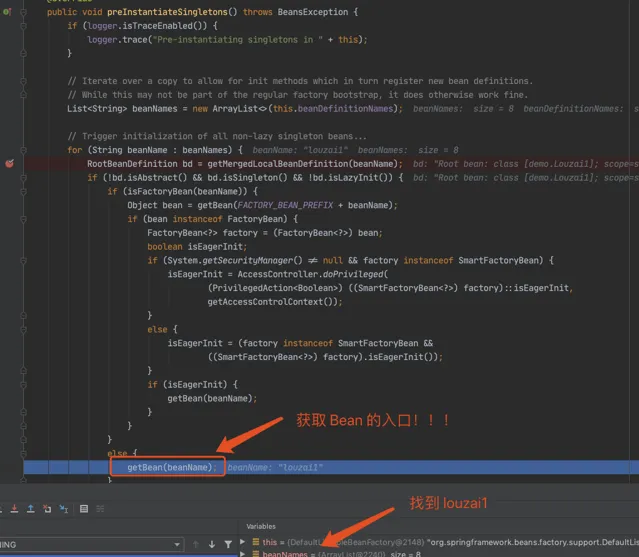
進入 doGetBean(),從 getSingleton() 沒有找到物件,進入建立 Bean 的邏輯。
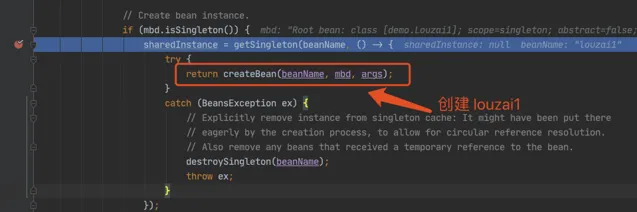
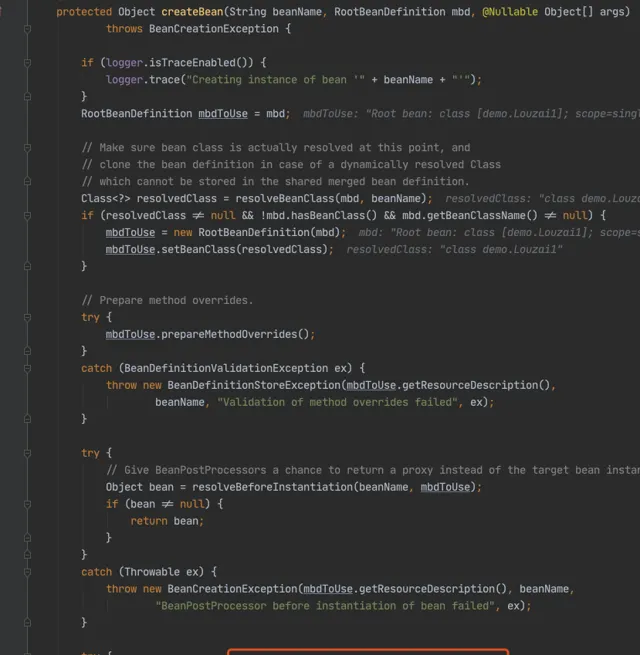
進入 doCreateBean() 後,呼叫 addSingletonFactory()。
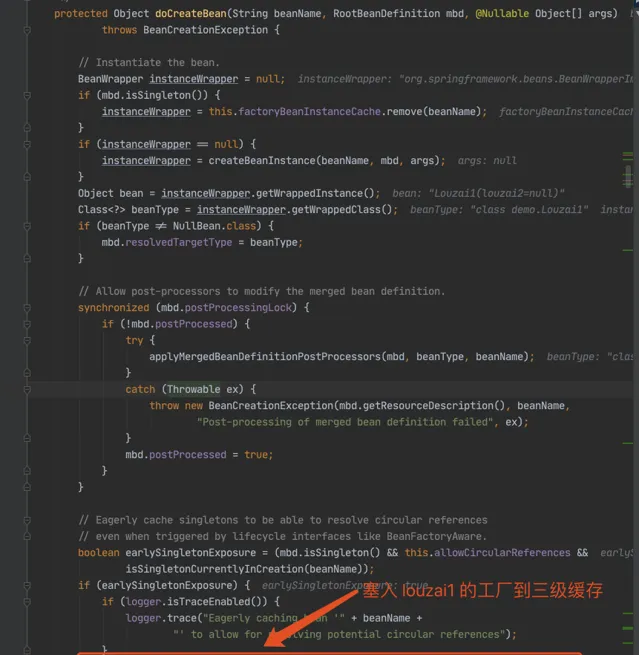
往三級緩存 singletonFactories 塞入 louzai1 的工廠物件。
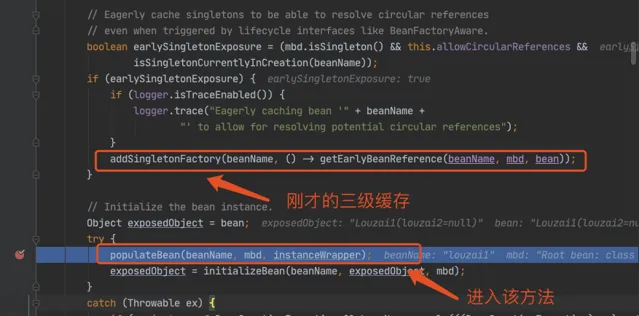
進入到 populateBean(),執行 postProcessProperties(),這裏是一個策略模式,找到下圖的策略物件。
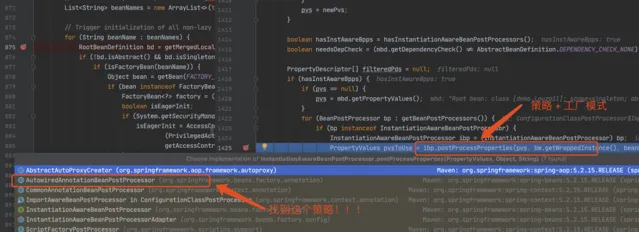
正式進入該策略對應的方法。
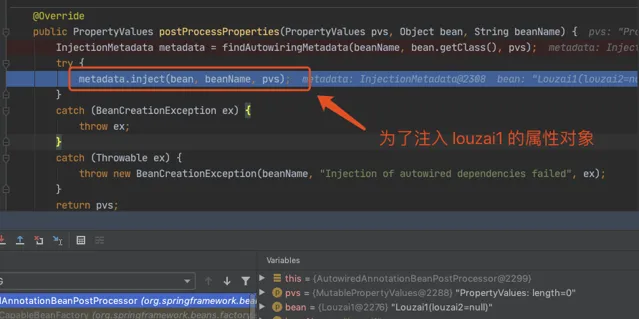
下面都是為了獲取 louzai1 的成員物件,然後進行註入。
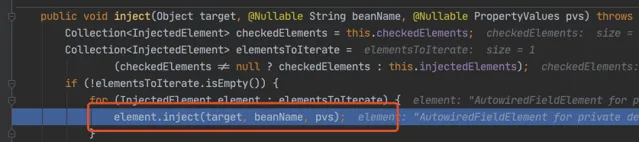
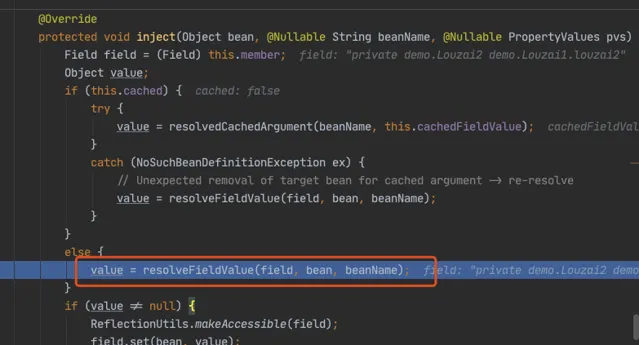
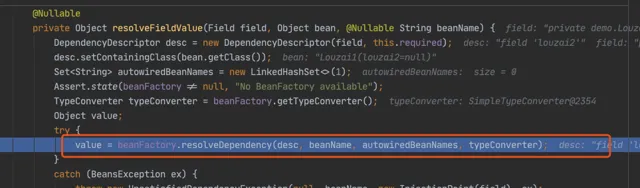
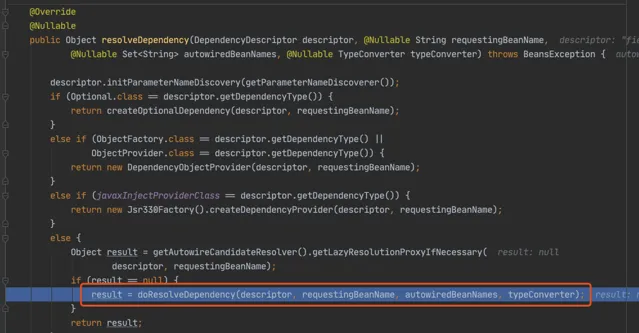
進入 doResolveDependency(),找到 louzai1 依賴的物件名 louzai2

需要獲取 louzai2 的 bean,是 AbstractBeanFactory 的方法。
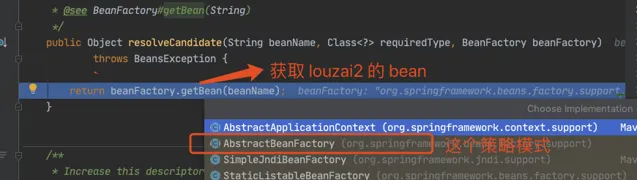
正式獲取 louzai2 的 bean。
到這裏,第一層套娃基本結束,因為 louzai1 依賴 louzai2,下面我們進入第二層套娃。
2.3 第二層
獲取 louzai2 的 bean,從 doGetBean(),到 doResolveDependency(),和第一層的邏輯完全一樣,找到 louzai2 依賴的物件名 louzai1。
前面的流程全部省略,直接到 doResolveDependency()。
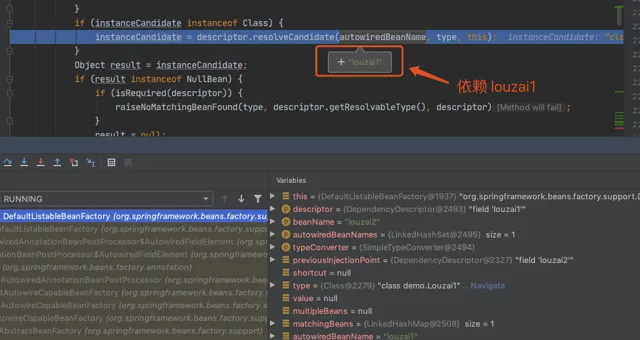
正式獲取 louzai1 的 bean。
到這裏,第二層套娃結束,因為 louzai2 依賴 louzai1,所以我們進入第三層套娃。
2.4 第三層
獲取 louzai1 的 bean,在第一層和第二層中,我們每次都會從 getSingleton() 獲取物件,但是由於之前沒有初始化 louzai1 和 louzai2 的三級緩存,所以獲取物件為空。
敲重點!敲重點!!敲重點!!!
到了第三層,由於第三級緩存有 louzai1 數據,這裏使用三級緩存中的工廠,為 louzai1 建立一個代理物件,塞入二級緩存。
這裏就拿到了 louzai1 的代理物件,解決了 louzai2 的依賴關系,返回到第二層。
2.5 返回第二層
返回第二層後,louzai2 初始化結束,這裏就結束了麽?二級緩存的數據,啥時候會給到一級呢?
甭著急,看這裏,還記得在 doGetBean() 中,我們會透過 createBean() 建立一個 louzai2 的 bean,當 louzai2 的 bean 建立成功後,我們會執行 getSingleton(),它會對 louzai2 的結果進行處理。
我們進入 getSingleton(),會看到下面這個方法。
這裏就是處理 louzai2 的 一、二級緩存的邏輯,將二級緩存清除,放入一級緩存。
2.6 返回第一層
同 2.5,louzai1 初始化完畢後,會把 louzai1 的二級緩存清除,將物件放入一級緩存。
到這裏,所有的流程結束,我們返回 louzai1 物件。
3. 原理深度解讀
3.1 什麽要有 3 級緩存 ?
這是一道非常經典的面試題,前面已經告訴大家詳細的執行流程,包括源碼解讀,但是沒有告訴大家為什麽要用 3 級緩存?
這裏是重點!敲黑板!!!
我們先說「一級緩存」的作用,變量命名為 singletonObjects,結構是 Map<String, Object>,它就是一個單例池,將初始化好的物件放到裏面,給其它執行緒使用, 如果沒有第一級緩存,程式不能保證 Spring 的單例內容。
「二級緩存」先放放,我們直接看「三級緩存」的作用,變量命名為 singletonFactories,結構是 Map<String, ObjectFactory<?>>,Map 的 Value 是一個物件的代理工廠,所以「三級緩存」的作用,其實就是用來存放物件的代理工廠。
那這個物件的代理工廠有什麽作用呢,我先給出答案, 它的主要作用是存放半成品的單例 Bean,目的是為了「打破迴圈」 ,可能大家還是不太懂,這裏我再稍微解釋一下。
我們回到文章開頭的例子,建立 A 物件時,會把例項化的 A 物件存入「三級緩存」,這個 A 其實是個半成品,因為沒有完成 A 的依賴內容 B 的註入,所以後面當初始化 B 時,B 又要去找 A,這時就需要從「三級緩存」中拿到這個半成品的 A(這裏描述,其實也不完全準確,因為不是直接拿,為了讓大家好理解,我就先這樣描述),打破迴圈。
那我再問一個問題, 為什麽「三級緩存」不直接存半成品的 A,而是要存一個代理工廠呢 ?答案是因為 AOP。
在解釋這個問題前,我們看一下這個代理工廠的源碼,讓大家有一個更清晰的認識。
直接找到建立 A 物件時,把例項化的 A 物件存入「三級緩存」的程式碼,直接用前面的兩幅截圖。
下面我們主要看這個物件工廠是如何得到的,進入 getEarlyBeanReference() 方法。
最後一幅圖太重要了,我們知道這個物件工廠的作用:
如果 A 有 AOP,就建立一個代理物件;
如果 A 沒有 AOP,就返回原物件。
那「二級緩存」的作用就清楚了,就是用來存放物件工廠生成的物件,這個物件可能是原物件,也可能是個代理物件。
我再問一個問題,為什麽要這樣設計呢?把二級緩存幹掉不行麽 ?我們繼續往下看。
3.2 能幹掉第 2 級緩存麽 ?
@Service
public classA{
@Autowired
private B b;
@Autowired
private C c;
publicvoidtest1(){
}
}
@Service
public classB{
@Autowired
private A a;
publicvoidtest2(){
}
}
@Service
public classC{
@Autowired
private A a;
publicvoidtest3(){
}
}
根據上面的套娃邏輯,A 需要找 B 和 C,但是 B 需要找 A,C 也需要找 A。
假如 A 需要進行 AOP ,因為代理物件每次都是生成不同的物件,如果幹掉第二級緩存,只有第一、三級緩存:
B 找到 A 時,直接透過三級緩存的工廠的代理物件,生成物件 A1。
C 找到 A 時,直接透過三級緩存的工廠的代理物件,生成物件 A2。
看到問題沒? 你透過 A 的工廠的代理物件,生成了兩個不同的物件 A1 和 A2 ,所以為了避免這種問題的出現,我們搞個二級緩存,把 A1 存下來,下次再獲取時,直接從二級緩存獲取,無需再生成新的代理物件。
所以「二級緩存」的目的是為了避免因為 AOP 建立多個物件,其中儲存的是半成品的 AOP 的單例 bean。
如果沒有 AOP 的話,我們其實只要 1、3 級緩存,就可以滿足要求。
4. 寫在最後
我們再回顧一下 3 級緩存的作用:
一級緩存: 為「Spring 的單例內容」而生 ,就是個單例池,用來存放已經初始化完成的單例 Bean;
二級緩存: 為「解決 AOP」而生 ,存放的是半成品的 AOP 的單例 Bean;
三級緩存: 為「打破迴圈」而生 ,存放的是生成半成品單例 Bean 的工廠方法。
如果你能理解上面我說的三條,恭喜你,你對 Spring 的迴圈依賴理解得非常透徹!
關於迴圈依賴的知識,其實還有,因為篇幅原因,我就不再寫了, 這篇文章的重點,一方面是告訴大家迴圈依賴的核心原理,另一方面是讓大家自己去 debug 程式碼 ,跑跑流程,挺有意思的。
可能有同學會問 「樓哥,你之前是不是經常看源碼,然後這個流程,你是不是 debug 了很久?」
我之前其實沒怎麽看過開原始碼,這個流程,前期理論知識看了 2.5 個小時,然後 debug 4.5 小時,就基本全部走通了, 最難的地方,就是三層套娃,稍微有些繞。
這裏也簡單說一下我看源碼的心得:
需要掌握基本的設計模式;
看源碼前,最好能找一些理論知識先看看;
學會讀英文註釋,不會的話就百度轉譯;
debug 時, 要克制自己,不要陷入無用的細節 ,這個最重要。
其中最難的是第 4 步,因為很多同學看 Spring 源碼,每看一個方法,就想多研究研究,這樣很容易被繞進去了,這個 要學會克制,有大局觀,並能分辨哪裏是核心邏輯 ,至於如何分辨,可以在網上先找些資料,如果沒有的話,就只能多看程式碼了。
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:樓仔
來源:樓仔
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!
關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











