一、容災介紹
我們通常會把故障分為三大類,一是主機故障,二是機房故障,三是地域故障。每類故障都有各自的誘發因素,而從主機到機房再到地域,故障發生機率依次越來越小,而故障的影響卻越來越大。
容災能力的建設目標是非常明確的,就是要能夠應對和處理這種機房級和地域級的大規模故障,從而來保障業務的連續性。近幾年,業界也發生了多次數據中心級別的故障,對相關公司的業務和品牌產生了非常大的負面影響。當前容災能力已經成為眾多IT企業建設資訊化系統的必選項。

二、業務容災架構
1.容災架構演進
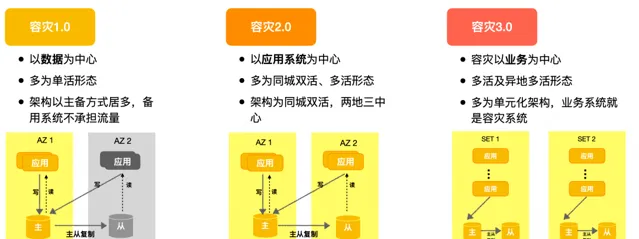
容災架構從最早期的單活形態(同城主備)到同城多活形態,再演化到異地多活,根據這個路徑可以將容災分為容災1.0、容災2.0、容災3.0三個階段。
容災1.0: 容災體系圍繞數據建設,多以主-備的方式部署,但備用機房不承擔流量,基本上都是單活結構。
容災2.0:
容災視角從數據轉換為套用系統,業務具有同城雙活或同城多活能力,采用同城雙活或同城雙活加異地冷備(兩地三中心)的部署架構,除冷備以外的每個機房都有流量處理能力。
容災3.0:
以業務為中心,多采用單元化架構,容災基於單元間的兩兩互備實作,根據單元的部署位置可以實作同城多活和異地多活。采用單元化架構的套用本身具有很好的容災能力和擴充套件能力。
由於各公司所處發展階段不同,采用的方案也會有所區別,美團大部份業務處於2.0階段(即同城雙活或多活架構),但對於大體量、有地域容災及有地域擴充套件性要求的業務則處在容災3.0階段。下面會介紹一下美團的容災架構。
2.美團容災架構
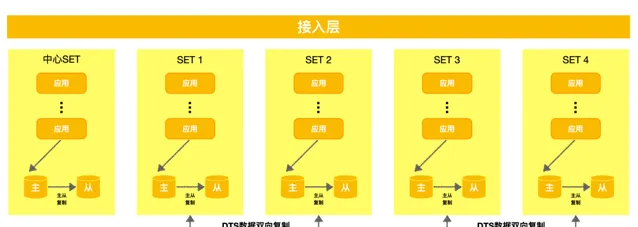
美團的容災架構主要包括兩種,一種是N+1容災架構,一種是SET化架構。
N+1架構: 在業界也稱散部或者多AZ部署⽅案,將容量為C的系統部署在N+1個機房,每個機房能提供至少C/N的容量,掛掉任何一個機房時,剩余系統仍能支撐C的容量。
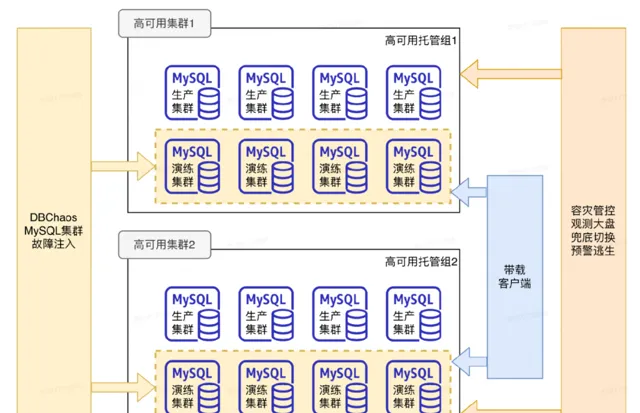
該方案的核心是把容災能力下沈到PaaS元件來完成,在出現機房級或者地域級故障的時候,由各個PaaS元件獨立完成容災切換,實作業務恢復。整體架構如下圖所示,業務上表現是多機房、多活形態,資料庫采用這種主從架構,單機房處理寫流量、多機房的負載均攤讀流量。下面要講「資料庫容災體系建設實踐」 就是面向N+1架構的。
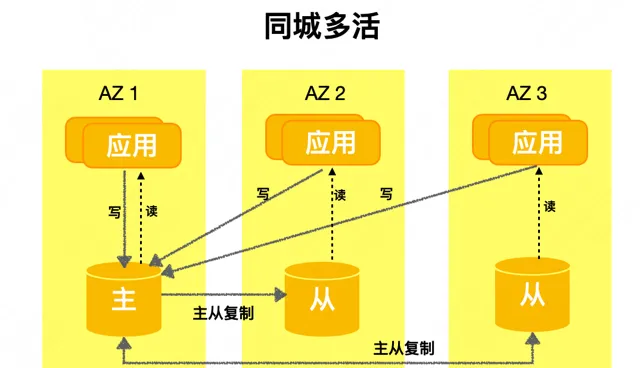
單元化架構: 也叫SET化架構,這是一種偏套用層的容災架構,它將套用,數據,基礎元件按照統一的維度切分成多個單元,每個單元處理一部份閉環流量。業務以單元作為部署單位,透過單元互備方式實作同城容災或者異地容災。
一般金融業務或者超大規模的業務會選擇此類架構,它的好處就是流量可以閉環且資源隔離,具有很強的容災能力和跨域擴充套件能力,不過SET化架構的落地需要業務系統做大量的改造,運維管理也較為復雜。簡化示意圖如下:
美團內部的大部份業務都是N+1架構,外賣和金融等業務采用了單元化架構。總體上美團內部既有同城多活,也有異地多活,兩種容災方案並存。
三、資料庫容災建設
1.面臨的挑戰
超大規模的集群帶來的挑戰: 公司業務高速發展,伺服器規模指數級增⻓,數據中心規模越來越大,大機房已有大幾千資料庫集群,上萬個例項。
效能問題: 高可用系統的故障並行處理能力出現明顯瓶頸。
容災失效風險:
管控鏈路隨集群數量的增加變得越來越復雜,一個環節出問題就會導致整體容災能力失效。
故障頻發:
集群數量和規模變大,使原來機率很低的大規模故障變成了稀松平常的故障,其發生的頻次和機率越來越高。
演練成本高、頻次低:
核心能力驗證不充分,大規模故障的應對能力處於不可知狀態,已知容災能力「保鮮」困難。拿應對機房級大規模故障的相關能力來講,很大一部份是處於不可知狀態或者僅存在於「紙面」分析中,而對於已驗證過的能力隨著架構演進叠代,「保鮮」也很困難。
資料庫作為有狀態的服務之一,本身建設應對大規模故障能力的難度和挑戰都相對更大。
2.基礎高可用
資料庫架構在美團主要有兩種一種是主從架構,一種是MGR架構。
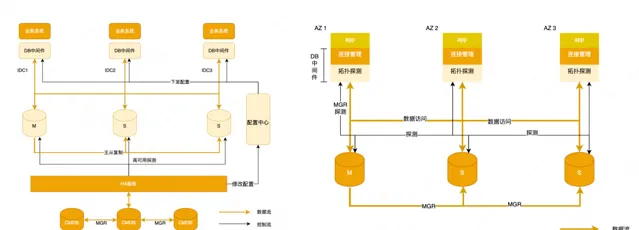
主從架構: 套用透過資料庫中介軟體存取資料庫,在故障發生時,高可用做故障探測、拓撲調整、配置下發,進而套用恢復。
MGR架構: 套用也是透過中介軟體存取資料庫,不過中介軟體對MGR做了適配,內部叫Zebra for MGR,中介軟體自動進行拓撲探測感知,一旦MGR發生了切換,新拓撲會被探測到,資料來源會進行調整,進而業務恢復。
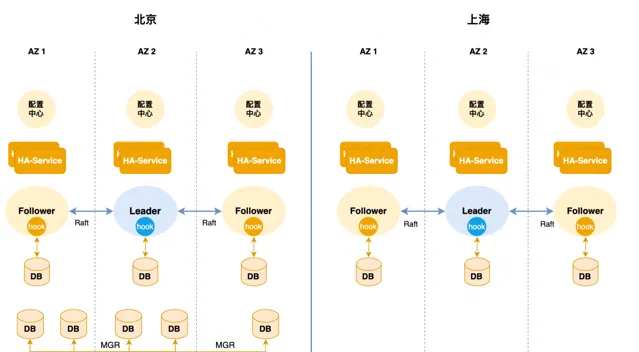
美團的高可用架構: 美團主從集群的高可用是基於Orchestrator二次開發的,本質上是一個中心化的管控架構。
如下圖所示,有多個高可用分組,每個分組托管一部份資料庫集群,分組在北京和上海實作兩Region部署,底層核心元件只在北京部署,比如我們的核心CMBD、WorkflowDB等,一旦北上專線出現問題,上海側的高可用會失效不可用。
3.容災建設路徑
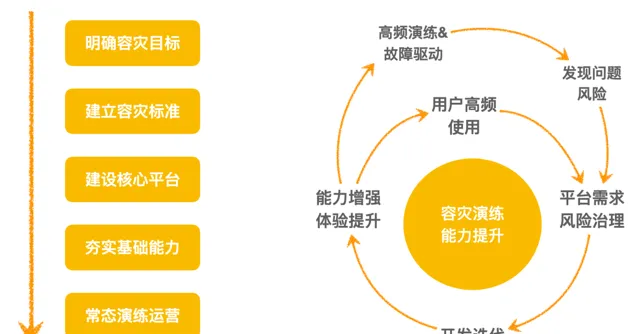
容災建設路徑: 確定容災目標、制定容災標準、建設容災平台、夯實基礎能力、演練驗證和風險營運。
容災建設飛輪: 內環是平台能力建設,從容災需求的提出到研發上線,體驗提升,使用者使用,發現問題提出新需求,不斷的叠代提升。另一個方面就是完善演練平台建設,開展高頻演練(或者真實故障驅動),發現問題、提出改進,促進平台能力持續叠代提升。
4.平台能力建設
為了建設提升資料庫服務的容災能力,內部成立了容災管控計畫DDTP(Database Disaster Tolerance Platform),專註提升資料庫應對大規模故障的能力,核心包括基礎容災管控和故障演練兩大能力,分別對應兩個平台產品:一是容災管控平台,一個是資料庫演練平台。
容災管控平台主要專註於防守,它的核心功能主要包括事前逃生、事中觀測以及止損、事後恢復等,資料庫演練平台則專註於進攻,支持多種故障型別和多種故障註入方式,具備故障編排,故障復盤等核心能力。
這個系列的第二篇【資料庫攻防演練建設實踐】就是對演練平台的詳細介紹。接下來,我們將重點介紹一下容災管控平台的主要內容,首先看一下全景圖:
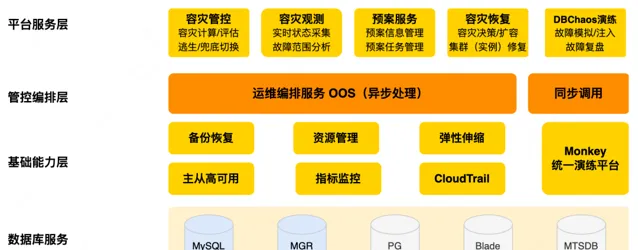
資料庫服務: 包括MySQL、Blade、MGR等基礎資料庫服務。
基礎能力層:
主要是備份恢復、資源管理、彈性伸縮、主從高可用以及指標監控能力,這些能力是穩定性保障的基本部份,但在容災場景下需要進一步加強,以處理大規模故障場景。
管控編排層:
核心是運維編排服務OOS(Operation Orchestration Service),會把基礎能力按需編排生成對應的處理流程也叫服務化預案,每個預案對應一個或者多個具體的運維場景。容災預案也在這個範疇。
平台服務層:
是容災管控平台的能力層,包括:1)
容災管控
,容災計算評估和隱患治理,還有故障前容災逃生、故障中的兜底切換,故障摘流等。2)
容災觀測
,明確故障範圍,支持故障中的容災決策。3)
容災恢復
,故障後透過例項修復、集群擴容等功能快速恢復集群的容災能力。4)
預案服務
,包含了常見故障應急預案的管理和執行等等。
1)容量達標
資料庫建立了一套N+1容災計算標準,分為6個等級,如果集群容災等級≥4級則容災達標,否則容災不達標。
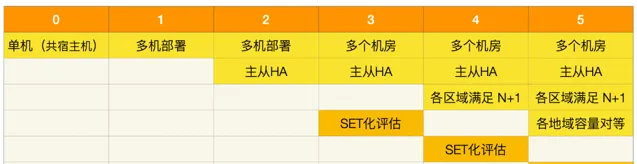
從標準可以看出,從等級3開始就是多機房部署了。3級和4、5級的區別是,3級不滿足N+1要求,即如果一個機房的節點都出問題,剩余節點無法承擔峰值流量。等級4、5都是具備N+1要求的,等級5會滿足region間容量對等。
除基礎標準以外,SET化集群有特殊規則,比如路由策略要閉環、SET集群的繫結機房要統一、互備SET容量要對等、集群內機型要統一等。這些規則都會納入容災計算來確定集群的最終容災等級。
在基礎容災數據建設中,會把上述規則程式碼化、計算流程化,透過近即時的方式做基礎數據「保鮮」。
容災數據是容災管控平台上用於逃生切換和事中止損的基礎數據,同時還會基於容災數據建設風險隱患(即容災不達標隱患),並透過一定的營運治理來消除這種隱患。
2)故障前逃生
故障前逃逸能力就是批次主庫切換和從庫摘流,主要用於在故障前收到預警,提前感知災難來臨,快速將一個機房的所有資料庫服務切走或者下線從庫流量,以降低真實故障帶來的影響。
我們知道對於主從架構的集群,如果因為斷電或者斷網發生故障切換,很可能會發生數據遺失。數據一旦遺失,業務需要進行確認並做善後工作,有時候會非常繁瑣。如果能夠在事前逃走就會把這些風險都規避掉。同時除了主庫逃走以外,從庫也可以提前把流量「摘掉」,從而做到故障對業務方「無感」。
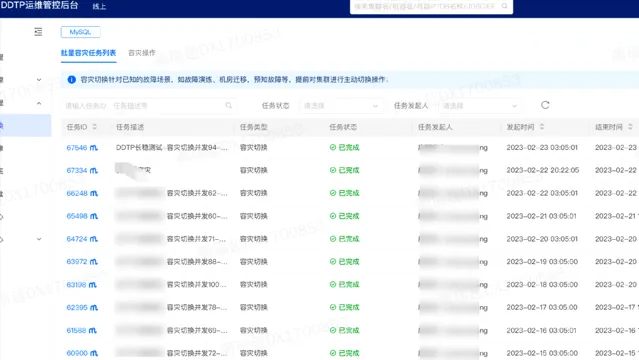
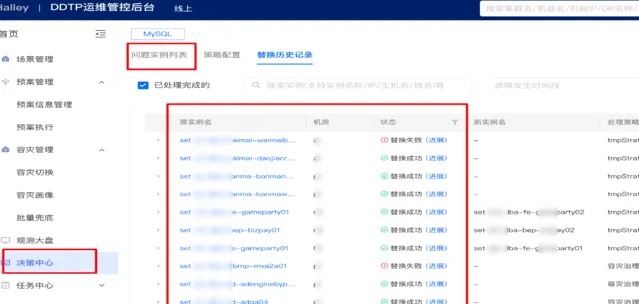
3)故障中觀測
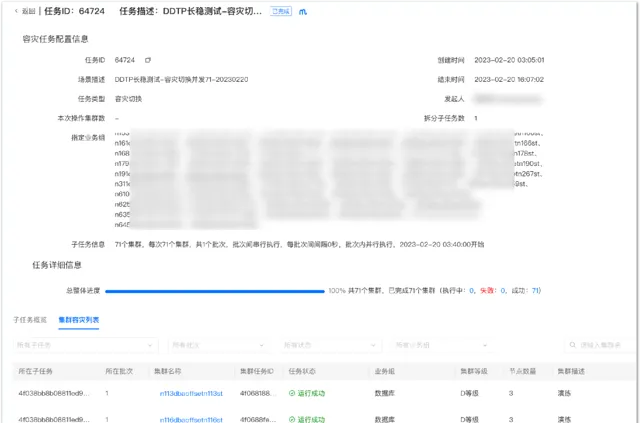
在大規模故障發生的時候,一般會出現告警轟炸,電話咨詢轟炸等情況,如果沒有全域的故障感知能力,就會使故障處理比較混亂,處理時間比較長,讓故障影響放大,所以我們建設了容災觀測大盤,它能夠即時、準確、可靠地對故障進行觀測,以確保值班同學能夠掌握故障的即時情況。
如下圖所示,如果發生了故障,可以快速拿到故障集群或者例項列表,並在對應的頁面上發起兜底切換動作,進而實作快速止損。對觀測大盤的核心訴求就是要即時、準確、可靠。可以透過減少服務依賴來提升自身的可用性。
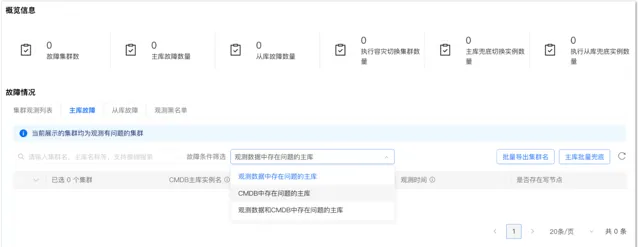
4)故障中止損
在介紹故障中的止損之前,先了解一下預案服務。預案服務的核心功能就是管理常見故障以及對應的各種處理預案,並提供執行控制能力,讓預案可以方便、可控地執行。

故障止損: 在有了預案以後,我們就可以進行兜底止損。如下圖所示,當大規模故障發生的時候,HA會自動進行故障處理。如果集群切換失敗或者漏切,那麽它就會進入兜底階段。首先從DDTP平台化兜底,如果平台受故障影響不可用,可以在運維編排層進行兜底。
如果運維編排服務也失效,則需要人工透過CLI工具進行兜底。CLI是DBA最底層的工具,它和高可用是兩個獨立的鏈路。CLI會進行集群拓撲探測、選主選舉、拓撲調整、配置修改、配置下發等邏輯,等同於手工集群切換步驟。
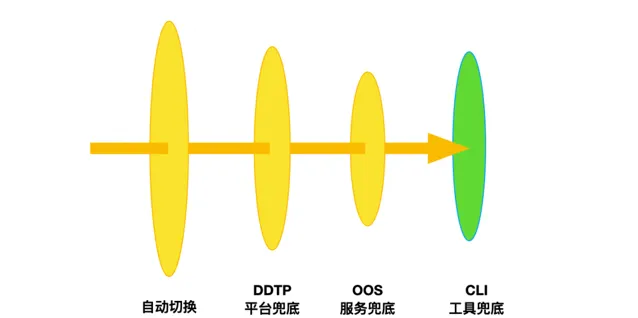
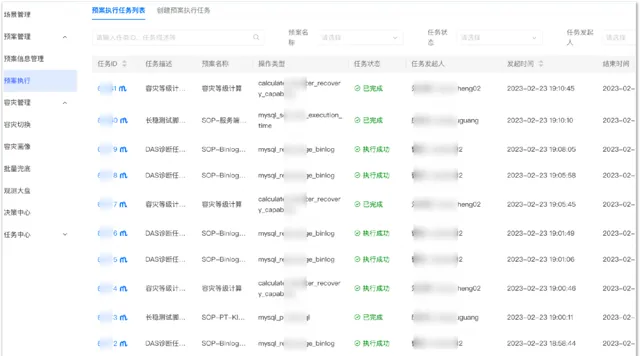
總體原則優先提升高可用自動切換的成功率,減少透傳到兜底階段的集群數量。其次提升預案可靠性,優先選擇白屏,逐級下沈,易用性下降,可靠性提升。
5)故障後恢復
雖然集群具備N+1能力,一個機房故障的時候,集群剩余節點是能夠支撐峰值流量,但它不具備再一次AZ故障的容災能力,所以在故障後會根據各機房的資源情況,透過容災決策中心快速進行集群擴容來補齊核心集群的容災容量,使其重新具備AZ容災能力。
上述方案有一個比較大的弊端就是需要有足夠的資源來進行擴容,這是非常困難的,目前我們在建設更快速的恢復能力,如例項原地修復,集群原地擴容等,在AZ恢復之後,可以快速復用發生故障的機房內的機器資源,實作容災快速恢復。
5.演練體系建設
各項基礎容災能力不能只存在於架構設計、理論評估層面,必須實打實的可用,這就要需要透過演練進行驗證。容災管控計畫之初,就制定了以演練為抓手的策略,驗證並驅動各項基礎能力的提升。
截至目前,已經初步建成了多環境、高頻次、大規模、長鏈路的演練體系。

多環境: 我們建設了多種演練環境,滿足各個PaaS元件的各類容災演練需求。一是容災管控平台的⻓穩環境,二是線下專用於演練的隔離環境,三是生產環境,有演練專區以及正常生產環境。
高頻次:
目前能做到天、周級別。天級別屬於常態化的演練,主要是在長穩環境下自動發起,幾百個集群的演練規模;周級別主要是在隔離環境、演練專區定期組織的斷網、斷電真實演練等。
大規模:
是在生產環境開展的演練,用於驗證基礎高可用、兜底預案、逃生預案、容災恢復等功能的大規模、高並行處理能力,確定管控系統的服務容量。
長鏈路:
整個容災鏈路涉及到很多元件,包括CMDB資料庫、流程資料庫,高可用元件,配置中心、預案服務等,我們會逐步把這些元件都納入演練,可以讓一個或者多個元件服務同時故障,發現潛在問題,驗證多服務的多節點同時故障對於整個故障處理能力的影響。
1)隔離環境演練
隔離環境演練顧名思義,它是一套和生產機房完全隔離的演練環境,有自己獨立的TOR、機櫃,風險能做到完全隔離,可以開展獨立斷網或斷電操作。參與演練的PaaS元件和業務服務要在該環境獨立部署。在隔離環境除了會定期開展各種容災演練發現容災問題外,還可以驗證各PaaS的獨立部署能力,為國際化業務支撐提供基礎。
2)生產環境演練
常態化、大規模故障演練: 此類演練是日常持續開展的,透過演練平台對資料庫集群註入故障,高可用進行故障切換。透過不同的演練規模來驗證高可用的並行切換能力。此外,在容災管控平台上,可以驗證逃生能力、止損預案、及大規模故障的觀測等。總而言之,它是利用「攻」和「防」相結合的形式,實作能力的驗證驗收和最佳化提升。
這類演練主要特點:
一是參演集群都是由生產環境的高可用分組進行托管,就是說演練驗證的都是生產環境的高可用的能力;
二是參演的大規模集群是非業務集群,是每次演練前新建立的專門用於演練的集群,規模可以做到很大,目前可以常態化的進行1500+集群同時進行演練;
三是有一定的仿真效果,為使演練更為真實並對RTO做精準評估,對演練集群增加了帶載能力。
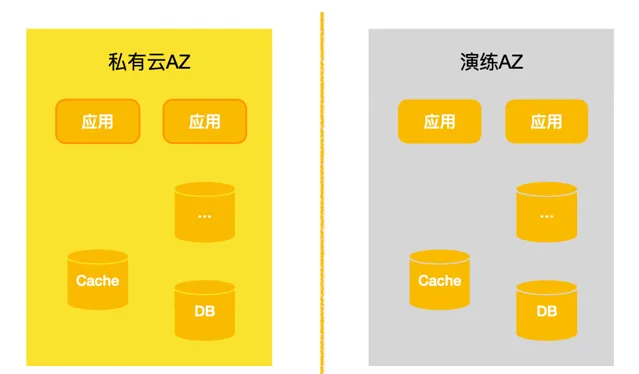
真實專區演練: 上文介紹的隔離環境演練、大規模演練都是偏模擬性質的,和真實的故障場景有比較大的區別。為了彌補和真實故障主鍵的GAP,我們基於公有雲構建了一個專用演練AZ,可以理解為就是一個獨立的機房。
參演業務和組PaaS件將部份承載業務流量的服務節點部署到演練AZ中,實際演練的時候會進行真實的斷網,業務和元件可以在斷網的時候觀測和評估自己的容災情況。這種透過真實機房、真實元件集群、真實的業務流量來驗證元件和業務的實際容災情況,會更加真實。
Game Day: 此外我們還在評估論證在真實機房開展演練的可行性,隨著隔離環境演練、專區演練的常態化開展,各個元件的基礎容災能力會越來越強,在真實機房進行常態化機房演練的終極目標也會隨之達成。
四、未來思考
經過兩年多的建設,雖然在高可用自動切換、容災能力營運治理、大規模故障觀測、故障止損預案、容災恢復等方面取得了一定的成果。但是還有很多能力短板需要建設補齊,業務新的發展也帶來了新的需求和挑戰。
未來我們會補齊短板、叠代技術架構兩個方向上進行持續提升。
1.補齊短板
超大規模逃生能力、止損能力不足: 隨著我們自建數據中心的落地,我們自建的AZ規模會更大,這對能力的要求會更高,我們主要透過平台叠代和演練驗證逐步提升能力。
跨域專線故障導致Region級高可用失效:
接下來我們會探索單元化方案或者獨立部署方案,實作Region級或者更細粒度的閉環管理。
業務出海新挑戰:
出海會給容災架構帶來一些新需求和挑戰,是采用「長臂管轄」還是獨立部署,是復用現有技術體系還是打造一套全新架構,這些問題都還需要進一步的探索和論證。
容災效率問題:
平台基礎功能已經相對完善,不過容災決策以及處理協同等還需要人工進行,效率相對較低,未來會把容災管控、應急止損等能力逐步向自動化演進;多環境演練成本比較高,也要逐步做自動化演練,把核心的演練場景逐步納到長穩環境,透過定時或一定的策略讓它自動去跑故障場景,我們只需要關註核心指標營運即可。
2.叠代架構
資料庫相關技術發展很快,比如Database Mesh、Serverless等新技術形態會逐步落地,屆時中介軟體、高可用、內核等會有比較大的變化,新型客戶端HA方案的建設成熟及新Proxy架構,存計分離產品的引入都會使容災的能力發生比較大的變化。容災能力建設會隨著這些確定的產品演進進行叠代。
容災建設是一件非常有挑戰的事,也是所有公司業務發展壯大後必須面對的一件事。歡迎大家在文末留言,跟我們一起交流。
作者丨瑞超
來源丨公眾號:美團技術團隊(ID:meituantech)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












