HTTP 歷史
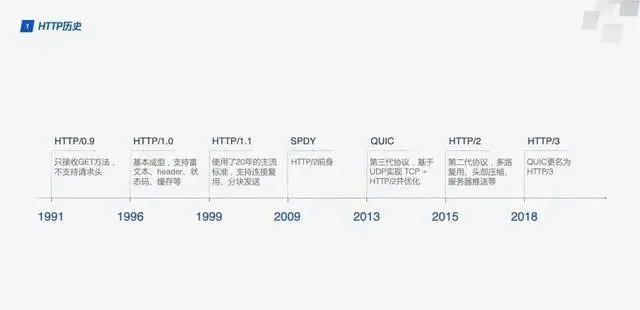
1991 HTTP/1.1
2009 Google 設計了基於TCP的SPDY
2013 QUIC
2015 HTTP/2
2018 HTTP/3
HTTP3是在保持QUIC穩定性的同時使用UDP來實作高速度(選擇QUIC就是選擇UDP), 同時又不會犧牲TLS的安全性.
QUIC 協定概覽
QUIC(Quick UDP Internet Connections, 快速UDP網路連線)是基於UDP的協定, 利用了UDP的速度和效率, 同時整合TCP, TLS和HTTP/2的優點並加以最佳化. 用一張圖可以清晰的表示他們之間的關系.
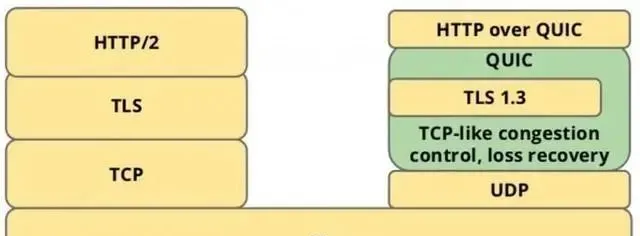
QUIC是用來替代TCP, SSL/TLS的傳輸層協定, 在傳輸層之上還有套用層. 我們熟知的套用層協定有HTTP, FTP, IMAP等, 這些協定理論上都可以執行在QUIC上, 其中執行在QUIC之上的協定被稱為HTTP/3, 這就是HTTP over QUIC即HTTP/3的含義,
因此想要了解HTTP/3, QUIC是繞不過去的, 下面是幾個重要的QUIC特性.
RTT建立連線
RTT: round-trip time, 僅包括請求存取來回的時間
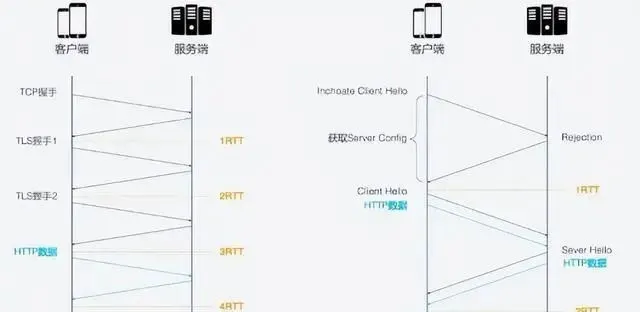
HTTP/2的連線建立需要3 RTT, 如果考慮會話復用, 即把第一次握手計算出來的對稱金鑰緩存起來, 那也需要2 RTT. 更進一步的, 如果TLS升級到1.3, 那麽HTTP/2連線需要2RTT, 考慮會話復用需要1RTT. 如果HTTP/2不急於HTTPS, 則可以簡化, 但實際上幾乎所有瀏覽器的設計都要求HTTP/2需要基於HTTPS.
HTTP/3首次連線只需要1RTT, 後面的連結只需要0RTT, 意味著客戶端發送給伺服端的第一個包就帶有請求數據, 其主要連線過程如下:
首次連線, 客戶端發送Inchoate Client Hello, 用於請求連線;
伺服端生成g, p, a, 根據g, p, a算出A, 然後將g, p, A放到Server Config中在發送Rejection訊息給客戶端.
客戶端接收到g,p,A後, 自己再生成b, 根據g,p,a算出B, 根據A,p,b算出初始金鑰K, B和K算好後, 客戶端會用K加密HTTP數據, 連同B一起發送給伺服端.
伺服端接收到B後, 根據a,p,B生成與客戶端同樣的金鑰, 再用這金鑰解密收到的HTTP數據. 為了進一步的安全(前向安全性), 伺服端會更新自己的隨機數a和公鑰, 在生成新的金鑰S, 然後把公鑰透過Server Hello發送給客戶端. 連同Server Hello訊息, 還有HTTP返回數據.
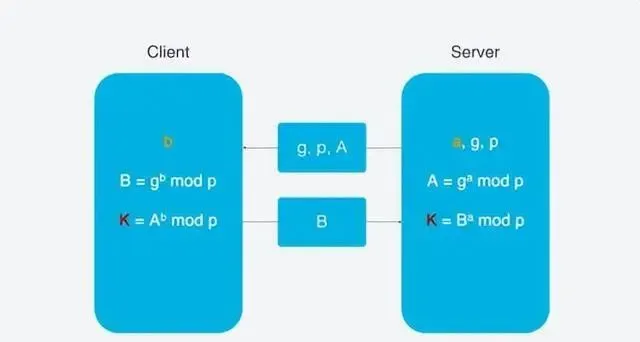
這裏使用DH金鑰交換演算法, DH演算法的核心就是伺服端生成a,g,p3個隨機數, a自己持有, g和p要傳輸給客戶端, 而客戶端會生成b這1個隨機數, 透過DH演算法客戶端和伺服端可以算出同樣的金鑰. 在這過程中a和b並不參與網路傳輸, 安全性大大提升. 因為p和g是大數, 所以即使在網路傳輸中p, g, A, B都被劫持, 靠現在的計算力算力也無法破解.
連線遷移
TCP連線基於四元組(源IP, 源埠, 目的IP, 目的埠), 切換網路時至少會有一個因素發生變化, 導致連線發送變化. 當連線發送變化是, 如果還是用原來的TCP連線, 則會導致連線失敗, 就得等到原來的連線超時後重新建立連線, 所以我們有時候發現切換到一個新的網路時, 即使網路狀況良好, 但是內容還是需要載入很久. 如果實作的好, 當檢測到網路變化時, 立即建立新的TCP連線, 即使這樣, 建立新的連線還是需要幾百毫秒時間.
QUIC不受四元組的影響, 當這四個元素發生變化時, 原連線依然維持. 原理如下:
QUIC不以四元素作為表示, 而是使用一個64位元的隨機數, 這個隨機數被稱為Connection ID, 即使IP或者埠發生變化, 只要Connection ID沒有變化, 那麽連線依然可以維持.
隊頭阻塞/多路復用
HTTP/1.1和HTTP/2都存在隊頭阻塞的問題(Head Of Line blocking).
TCP是個面向連線的協定, 即發送請求後需要收到ACK訊息, 以確認物件已接受數據. 如果每次請求都要在收到上次請求的ACK訊息後再請求, 那麽效率無疑很低. 後來HTTP/1.1提出了Pipeline技術, 允許一個TCP連線同時發送多個請求. 這樣就提升了傳輸效率.
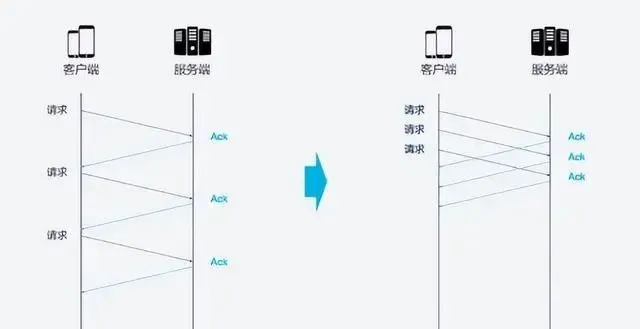
在這樣的背景下, 隊頭阻塞發生了. 比如, 一個TCP連線同時傳輸10個請求, 其中1,2,3個請求給客戶端接收, 但是第四個請求遺失, 那麽後面第5-10個請求都被阻塞. 需要等第四個請求處理完畢後才能被處理. 這樣就浪費了頻寬資源.
因此, HTTP一般又允許每個主機建立6個TCP連線, 這樣可以更加充分的利用頻寬資源, 但每個連線中隊頭阻塞的問題還是存在的.
HTTP/2的多路復用解決了上述的隊頭阻塞問題. 在HTTP/2中, 每個請求都被拆分為多個Frame透過一條TCP連線同時被傳輸, 這樣即使一個請求被阻塞, 也不會影響其他的請求.
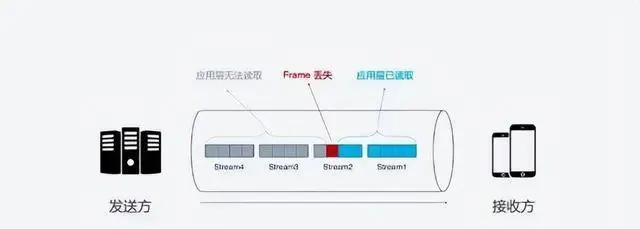
但是, HTTP/2雖然可以解決請求這一粒度下的阻塞, 但HTTP/2的基礎TCP協定本身卻也存在隊頭阻塞的問題. HTTP/2的每個請求都會被拆分成多個Frame, 不同請求的Frame組合成Stream, Stream是TCP上的邏輯傳輸單元, 這樣HTTP/2就達到了一條連線同時發送多個請求的目標, 其中Stram1已經正確送達, Stram2中的第三個Frame遺失
TCP處理數據是有嚴格的前後順序, 先發送的Frame要先被處理, 這樣就會要求發送方重新發送第三個Frame, Steam3和Steam4雖然已到達但卻不能被處理, 那麽這時整條鏈路都會被阻塞.
不僅如此, 由於HTTP/2必須使用HTTPS, 而HTTPS使用TLS協定也存在隊頭阻塞問題. TLS基於Record組織數據, 將一對數據放在一起加密, 加密完成後又拆分成多個TCP包傳輸. 一般每個Record 16K, 包含12個TCP包, 這樣如果12個TCP包中有任何一個包遺失, 那麽整個Record都無法解密.
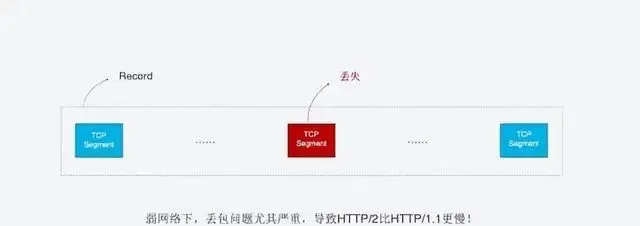
隊頭阻塞會導致HTTP/2在更容易丟包的弱網路環境下比HTTP/1.1更慢.
QUIC是如何解決隊頭阻塞的問題的? 主要有兩點:
QUIC的傳輸單位是Packet, 加密單元也是Packet, 整個加密, 傳輸, 解密都基於Packet, 這就能避免TLS的阻塞問題.
QUIC基於UDP, UDP的封包在接收端沒有處理順序, 即使中間遺失一個包, 也不會阻塞整條連線. 其他的資源會被正常處理.
擁塞控制
擁塞控制的目的是避免過多的數據一下子湧入網路, 導致網路超出最大負荷. QUIC的擁塞控制與TCP類似, 並在此基礎上做了改進. 先來看看TCP的擁塞控制.
慢啟動: 發送方像接收方發送一個單位的數據, 收到確認後發送2個單位, 然後是4個, 8個依次指數增長, 這個過程中不斷試探網路的擁塞程度.
避免擁塞: 指數增長到某個限制之後, 指數增長變為線性增長
快速重傳: 發送方每一次發送都會設定一個超時計時器, 超時後認為遺失, 需要重發
快速恢復: 在上面快速重傳的基礎上, 發送方重新發送數據時, 也會啟動一個超時定時器, 如果收到確認訊息則進入擁塞避免階段, 如果仍然超時, 則回到慢啟動階段.
QUIC重新實作了TCP協定中的Cubic演算法進行擁塞控制, 下面是QUIC改進的擁塞控制的特性:
1. 熱插拔
TCP中如果要修改擁塞控制策略, 需要在系統層面今次那個操作, QUIC修改擁塞控制策略只需要在套用層操作, 並且QUIC會根據不同的網路環境, 使用者來動態選擇擁塞控制演算法.
2. 前向錯誤更正 FEC
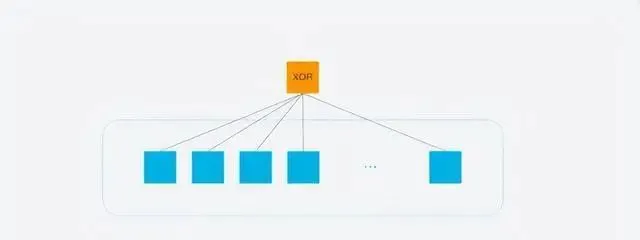
QUIC使用前向錯誤更正(FEC, Forword Error Correction)技術增加協定的容錯性. 一段數據被切分為10個包後, 一次對每個包進行異或運算, 運算結果會作為FEC包與封包一起被傳輸, 如果傳輸過程中有一個封包遺失, 那麽就可以根據剩余9個包以及FEC包推算出遺失的那個包的數據, 這樣就大大增加了協定的容錯性.
這是符合現階段網路傳輸技術的一種方案, 現階段頻寬已經不是網路傳輸的瓶頸, 往返時間才是, 所以新的網路傳輸協定可以適當增加數據冗余, 減少重傳操作.
3. 單調遞增的Packer Number
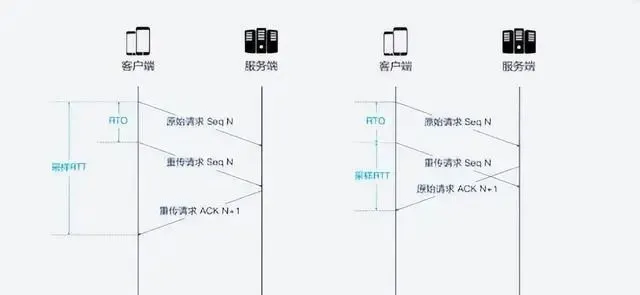
TCP為了保證可靠性, 使用Sequence Number和ACK來確認訊息是否有序到達, 但這樣的設計存在缺陷.超時發生後客戶端發起重傳, 後來接受到了ACK確認訊息, 但因為原始請求和重傳請求接受到的ACK訊息一樣, 所以客戶端就不知道這個ACK對應的是原始請求還是重傳請求. 這就會造成歧義.
RTT: Round Trip Time, 往返事件
RTO: Retransmission Timeout, 超時重傳時間
如果客戶端認為是重傳的ACK, 但實際上是右圖的情形, 會導致RTT偏小, 反之會導致RTT偏大.
QUCI解決了上面的的歧義問題, 與Sequence Number不同, Packet Number嚴格單調遞增, 如果Packet N遺失了, 那麽重傳時Packet的標識就不會是N, 而是比N大的數位, 比如N+M, 這樣發送方接收到確認訊息時, 就能方便的知道ACK對應的原始請求還是重傳請求.
4. ACK Delay
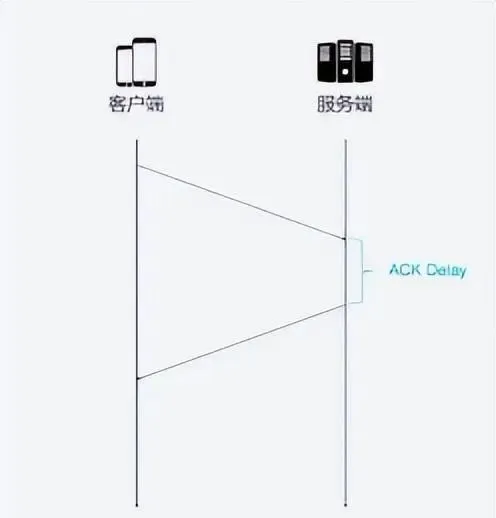
TCP計算RTT時沒有考慮接收方接受到數據發發送方確認訊息之間的延遲, 如下圖所示, 這段延遲即ACK Delay. QUIC考慮了這段延遲, 使得RTT的計算更加準確.
5. 更多的ACK塊
一般來說, 接收方收到發送方的訊息後都應該發送一個ACK恢復, 表示收到了數據. 但每收到一個數據就返回一個ACK恢復實在太麻煩, 所以一般不會立即回復, 而是接受到多個數據後再回復, TCP SACK最多提供3個ACK block. 但在有些場景下, 比如下載, 只需要伺服器返回數據就好, 但按照TCP的設計, 每收到三個封包就要返回一個ACK, 而QUIC最多可以捎帶256個ACK block, 在丟包率比較嚴重的網路下, 更多的ACK可以減少重傳量, 提升網路效率.
瀏覽控制
TCP 會對每個TCP連線進行流量控制, 流量控制的意思是讓發送方不要發送太快, 要讓接收方來得及接受, 不然會導致數據溢位而遺失, TCP的流量控制主要透過滑動視窗來實作的. 可以看到, 擁塞控制主要是控制發送方的發送策略, 但沒有考慮接收方的接收能力, 流量控制是對部份能力的不起.
QUIC只需要建立一條連線, 在這條連線上同時傳輸多條Stream, 好比有一條道路, 量都分別有一個倉庫, 道路中有很多車輛運送物資. QUIC的流量控制有兩個級別: 連線級別(Connection Level)和Stream 級別(Stream Level).
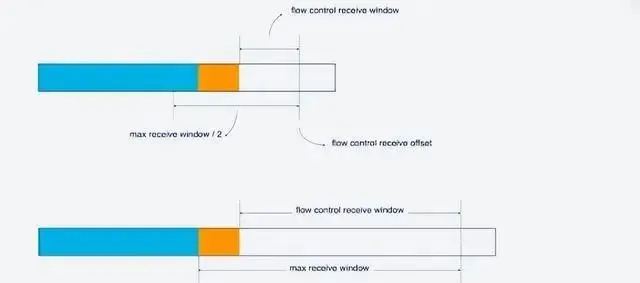
對於單條的Stream的流量控制: Stream還沒傳輸數據時, 接收視窗(flow control recevice window)就是最大接收視窗, 隨著接收方接收到數據後, 接收視窗不斷縮小. 在接收到的數據中, 有的數據已被處理, 而有的數據還沒來得及處理. 如下圖, 藍色塊表示已處理數據, 黃色塊表示違背處理數據, 這部份數據的到來, 使得Stream的接收視窗縮小.
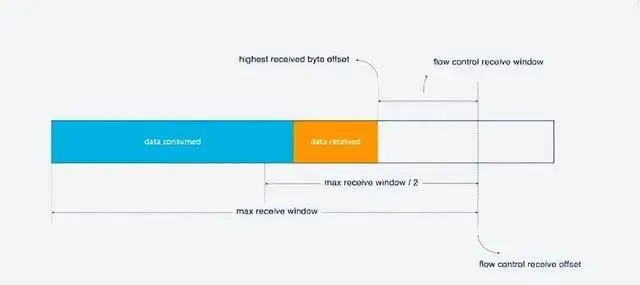
隨著數據不斷被處理, 接收方就有能力處理更多數據. 當滿足(flow control receivce offset - consumed bytes) < (max receive window/2)時, 接收方會發送WINDOW_UPDATE frame告訴發送方你可以再多發送數據, 這時候flow control receive offset就會偏移, 接收視窗增大, 發送方可以發送更多數據到接收方.
Stream級別對防止接收端接收過多數據作用有限, 更需要借助Connection級別的流量控制. 理解了Stream流量那麽也很好理解Connection的流控. Stream中,
接收視窗=最大接受視窗 - 已接收數據
而對於Connection來說:
接收視窗 = Stream1 接收視窗 + Stream2 接收視窗 + ... + StreamN 接收視窗
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
來源: 網路
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











