前言
介面效能最佳化 對於從事後端開發的同學來說,肯定再熟悉不過了,因為它是一個跟開發語言無關的公共問題。
該問題說簡單也簡單,說復雜也復雜。
有時候,只需加個索引就能解決問題。
有時候,需要做程式碼重構。
有時候,需要增加緩存。
有時候,需要引入一些中介軟體,比如mq。
有時候,需要需要分庫分表。
有時候,需要拆分服務。
等等。。。
導致介面效能問題的原因千奇百怪,不同的計畫不同的介面,原因可能也不一樣。
本文我總結了一些行之有效的,最佳化介面效能的辦法,給有需要的朋友一個參考。
1.索引
介面效能最佳化大家第一個想到的可能是:
最佳化索引
。
沒錯,最佳化索引的成本是最小的。
你透過檢視線上日誌或者監控報告,查到某個介面用到的某條sql語句耗時比較長。
這時你可能會有下面這些疑問:
該sql語句加索引了沒?
加的索引生效了沒?
mysql選錯索引了沒?
1.1 沒加索引
sql語句中
where
條件的關鍵欄位,或者
order by
後面的排序欄位,忘了加索引,這個問題在計畫中很常見。
計畫剛開始的時候,由於表中的數據量小,加不加索引sql查詢效能差別不大。
後來,隨著業務的發展,表中數據量越來越多,就不得不加索引了。
可以透過命令:
show index from `order`;
能單獨檢視某張表的索引情況。
也可以透過命令:
show create table `order`;
檢視整張表的建表語句,裏面同樣會顯示索引情況。
透過
ALTER TABLE
命令可以添加索引:
ALTER TABLE `order` ADD INDEX idx_name(name);
也可以透過
CREATE INDEX
命令添加索引:
CREATE INDEX idx_name ON `order` (name);
不過這裏有一個需要註意的地方是:想透過命令修改索引,是不行的。
目前在mysql中如果想要修改索引,只能先刪除索引,再重新添加新的。
刪除索引可以用
DROP INDEX
命令:
ALTER TABLE `order` DROP INDEX idx_name;
用
DROP INDEX
命令也行:
DROP INDEX idx_name ON `order`;
1.2 索引沒生效
透過上面的命令我們已經能夠確認索引是有的,但它生效了沒?此時你內心或許會冒出這樣一個疑問。
那麽,如何檢視索引有沒有生效呢?
答:可以使用
explain
命令,檢視mysql的執行計劃,它會顯示索引的使用情況。
例如:
explain select * from `order` where code='002';
結果: 透過這幾列可以判斷索引使用情況,執行計劃包含列的含義如下圖所示:
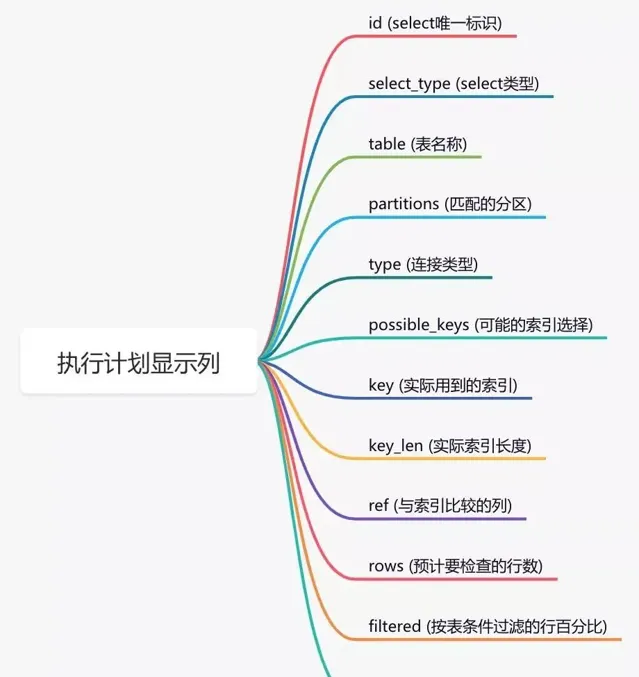
說實話,sql語句沒有走索引,排除沒有建索引之外,最大的可能性是索引失效了。
下面說說索引失效的常見原因:
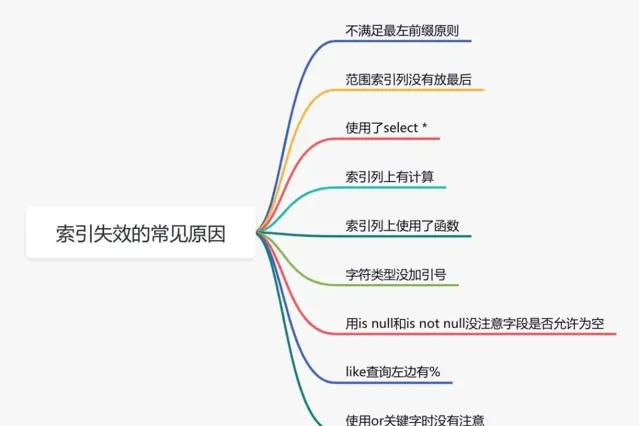
1.3 選錯索引
此外,你有沒有遇到過這樣一種情況:明明是同一條sql,只有入參不同而已。有的時候走的索引a,有的時候卻走的索引b?
沒錯,有時候mysql會選錯索引。
必要時可以使用
force index
來強制查詢sql走某個索引。
至於為什麽mysql會選錯索引,後面有專門的文章介紹的,這裏先留點懸念。
2. sql最佳化
如果最佳化了索引之後,也沒啥效果。
接下來試著最佳化一下sql語句,因為它的改造成本相對於java程式碼來說也要小得多。
下面給大家列舉了sql最佳化的15個小技巧:
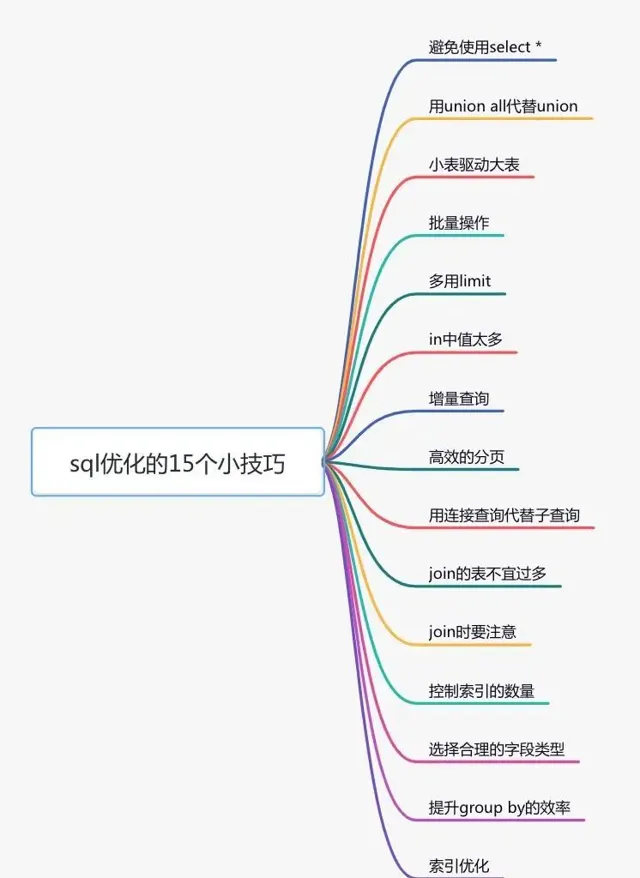
3. 遠端呼叫
很多時候,我們需要在某個介面中,呼叫其他服務的介面。
比如有這樣的業務場景:
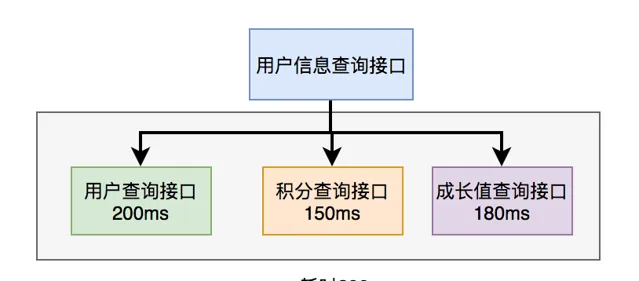
在使用者資訊查詢介面中需要返回:使用者名稱稱、性別、等級、頭像、積分、成長值等資訊。
而使用者名稱稱、性別、等級、頭像在使用者服務中,積分在積分服務中,成長值在成長值服務中。為了匯總這些數據統一返回,需要另外提供一個對外介面服務。
於是,使用者資訊查詢介面需要呼叫使用者查詢介面、積分查詢介面 和 成長值查詢介面,然後匯總數據統一返回。
呼叫過程如下圖所示: 呼叫遠端介面總耗時 530ms = 200ms + 150ms + 180ms
顯然這種序列呼叫遠端介面效能是非常不好的,呼叫遠端介面總的耗時為所有的遠端介面耗時之和。
那麽如何最佳化遠端介面效能呢?
3.1 並列呼叫
上面說到,既然序列呼叫多個遠端介面效能很差,為什麽不改成並列呢?
如下圖所示:
在java8之前可以透過實作
Callable
介面,獲取執行緒返回結果。
java8以後透過
CompleteFuture
類實作該功能。我們這裏以CompleteFuture為例:
public UserInfo getUserInfo(Long id)throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}
溫馨提醒一下,這兩種方式別忘了使用執行緒池。範例中我用到了executor,表示自訂的執行緒池,為了防止高並行場景下,出現執行緒過多的問題。
3.2 數據異構
上面說到的使用者資訊查詢介面需要呼叫使用者查詢介面、積分查詢介面 和 成長值查詢介面,然後匯總數據統一返回。
那麽,我們能不能把數據冗余一下,把使用者資訊、積分和成長值的數據統一儲存到一個地方,比如:redis,存的數據結構就是使用者資訊查詢介面所需要的內容。然後透過使用者id,直接從redis中查詢數據出來,不就OK了?
如果在高並行的場景下,為了提升介面效能,遠端介面呼叫大機率會被去掉,而改成保存冗余數據的數據異構方案。
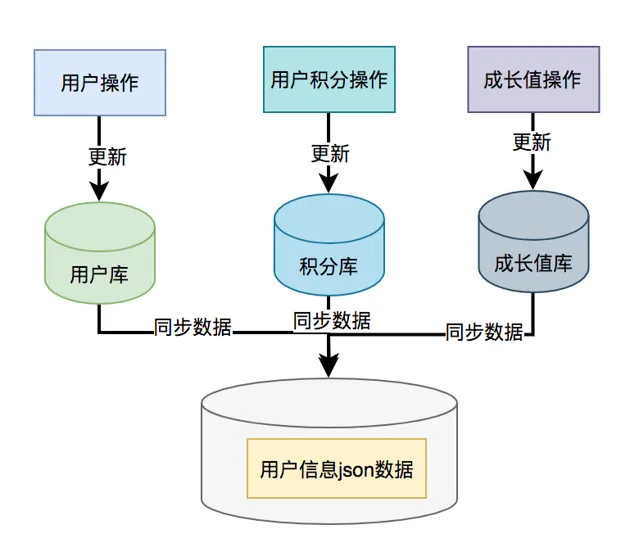
使用者資訊、積分和成長值有更新的話,大部份情況下,會先更新到資料庫,然後同步到redis。但這種跨庫的操作,可能會導致兩邊數據不一致的情況產生。
4. 重復呼叫
重復呼叫
在我們的日常工作程式碼中可以說隨處可見,但如果沒有控制好,會非常影響介面的效能。
不信,我們一起看看。
4.1 迴圈查資料庫
有時候,我們需要從指定的使用者集合中,查詢出有哪些是在資料庫中已經存在的。
實作程式碼可以這樣寫:
public List<User> queryUser(List<User> searchList){
if (CollectionUtils.isEmpty(searchList)) {
return Collections.emptyList();
}
List<User> result = Lists.newArrayList();
searchList.forEach(user -> result.add(userMapper.getUserById(user.getId())));
return result;
}
這裏如果有50個使用者,則需要迴圈50次,去查詢資料庫。我們都知道,每查詢一次資料庫,就是一次遠端呼叫。
如果查詢50次資料庫,就有50次遠端呼叫,這是非常耗時的操作。
那麽,我們如何最佳化呢?
具體程式碼如下:
public List<User> queryUser(List<User> searchList){
if (CollectionUtils.isEmpty(searchList)) {
return Collections.emptyList();
}
List<Long> ids = searchList.stream().map(User::getId).collect(Collectors.toList());
return userMapper.getUserByIds(ids);
}
提供一個根據使用者id集合批次查詢使用者的介面,只遠端呼叫一次,就能查詢出所有的數據。
這裏有個需要註意的地方是:id集合的大小要做限制,最好一次不要請求太多的數據。要根據實際情況而定,建議控制每次請求的記錄條數在500以內。
4.2 死迴圈
有些小夥伴看到這個標題,可能會感到有點意外,死迴圈也算?
程式碼中不是應該避免死迴圈嗎?為啥還是會產生死迴圈?
有時候死迴圈是我們自己寫的,例如下面這段程式碼:
while(true) {
if(condition) {
break;
}
System.out.println("do samething");
}
這裏使用了while(true)的迴圈呼叫,這種寫法在
CAS自旋鎖
中使用比較多。
當滿足condition等於true的時候,則自動結束該迴圈。
如果condition條件非常復雜,一旦出現判斷不正確,或者少寫了一些邏輯判斷,就可能在某些場景下出現死迴圈的問題。
出現死迴圈,大機率是開發人員人為的bug導致的,不過這種情況很容易被測出來。
還有一種隱藏的比較深的死迴圈,是由於程式碼寫的不太嚴謹導致的。如果用正常數據,可能測不出問題,但一旦出現異常數據,就會立即出現死迴圈。
4.3 無限遞迴
如果想要打印某個分類的所有父分類,可以用類似這樣的遞迴方法實作:
publicvoidprintCategory(Category category){
if(category == null
|| category.getParentId() == null) {
return;
}
System.out.println("父分類名稱:"+ category.getName());
Category parent = categoryMapper.getCategoryById(category.getParentId());
printCategory(parent);
}
正常情況下,這段程式碼是沒有問題的。
但如果某次有人誤操作,把某個分類的parentId指向了它自己,這樣就會出現無限遞迴的情況。導致介面一直不能返回數據,最終會發生堆疊溢位。
建議寫遞迴方法時,設定一個遞迴的深度,比如:分類最大等級有4級,則深度可以設定為4。然後在遞迴方法中做判斷,如果深度大於4時,則自動返回,這樣就能避免無限迴圈的情況。
5. 異步處理
有時候,我們介面效能最佳化,需要重新梳理一下業務邏輯,看看是否有設計上不太合理的地方。
比如有個使用者請求介面中,需要做業務操作,發站內通知,和記錄操作日誌。為了實作起來比較方便,通常我們會將這些邏輯放在介面中同步執行,勢必會對介面效能造成一定的影響。
介面內部流程圖如下:
這個介面表面上看起來沒有問題,但如果你仔細梳理一下業務邏輯,會發現只有業務操作才是
核心邏輯
,其他的功能都是
非核心邏輯
。
在這裏有個原則就是:核心邏輯可以同步執行,同步寫庫。非核心邏輯,可以異步執行,異步寫庫。
上面這個例子中,發站內通知和使用者操作日誌功能,對即時性要求不高,即使晚點寫庫,使用者無非是晚點收到站內通知,或者營運晚點看到使用者操作日誌,對業務影響不大,所以完全可以異步處理。
通常異步主要有兩種:
多執行緒
和
mq
。
5.1 執行緒池
使用
執行緒池
改造之後,介面邏輯如下:
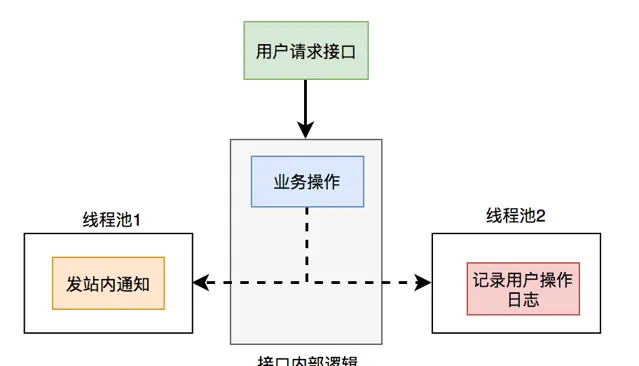
這樣介面中重點關註的是業務操作,把其他的邏輯交給執行緒異步執行,這樣改造之後,讓介面效能瞬間提升了。
但使用執行緒池有個小問題就是:如果伺服器重新開機了,或者是需要被執行的功能出現異常了,無法重試,會丟數據。
那麽這個問題該怎麽辦呢?
5.2 mq
使用
mq
改造之後,介面邏輯如下:

這樣改造之後,介面效能同樣提升了,因為發送mq訊息速度是很快的,我們只需關註業務操作的程式碼即可。
6. 避免大事務
很多小夥伴在使用spring框架開發計畫時,為了方便,喜歡使用
@Transactional
註解提供事務功能。
沒錯,使用@Transactional註解這種聲明式事務的方式提供事務功能,確實能少寫很多程式碼,提升開發效率。
但也容易造成大事務,引發其他的問題。
下面用一張圖看看大事務引發的問題。

我們該如何最佳化大事務呢?
少用@Transactional註解
將查詢(select)方法放到事務外
事務中避免遠端呼叫
事務中避免一次性處理太多數據
有些功能可以非事務執行
有些功能可以異步處理
7. 鎖粒度
在某些業務場景中,為了防止多個執行緒並行修改某個共享數據,造成數據異常。
為了解決並行場景下,多個執行緒同時修改數據,造成數據不一致的情況。通常情況下,我們會:
加鎖
。
但如果鎖加得不好,導致鎖的粒度太粗,也會非常影響介面效能。
7.1 synchronized
在java中提供了
synchronized
關鍵字給我們的程式碼加鎖。
通常有兩種寫法:
在方法上加鎖
和
在程式碼塊上加鎖
。
先看看如何在方法上加鎖:
publicsynchronizeddoSave(String fileUrl){
mkdir();
uploadFile(fileUrl);
sendMessage(fileUrl);
}
這裏加鎖的目的是為了防止並行的情況下,建立了相同的目錄,第二次會建立失敗,影響業務功能。
但這種直接在方法上加鎖,鎖的粒度有點粗。因為doSave方法中的上傳檔和發訊息方法,是不需要加鎖的。只有建立目錄方法,才需要加鎖。
我們都知道檔上傳操作是非常耗時的,如果將整個方法加鎖,那麽需要等到整個方法執行完之後才能釋放鎖。顯然,這會導致該方法的效能很差,變得得不償失。
這時,我們可以改成在程式碼塊上加鎖了,具體程式碼如下:
publicvoiddoSave(String path,String fileUrl){
synchronized(this) {
if(!exists(path)) {
mkdir(path);
}
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
這樣改造之後,鎖的粒度一下子變小了,只有並行建立目錄功能才加了鎖。而建立目錄是一個非常快的操作,即使加鎖對介面的效能影響也不大。
最重要的是,其他的上傳檔和發送訊息功能,任然可以並行執行。
當然,這種做在單機版的服務中,是沒有問題的。但現在部署的生產環境,為了保證服務的穩定性,一般情況下,同一個服務會被部署在多個節點中。如果哪天掛了一個節點,其他的節點服務任然可用。
多節點部署避免了因為某個節點掛了,導致服務不可用的情況。同時也能分攤整個系統的流量,避免系統壓力過大。
同時它也帶來了新的問題:synchronized只能保證一個節點加鎖是有效的,但如果有多個節點如何加鎖呢?
答:這就需要使用:
分布式鎖
了。目前主流的分布式鎖包括:redis分布式鎖、zookeeper分布式鎖 和 資料庫分布式鎖。
由於zookeeper分布式鎖的效能不太好,真實業務場景用的不多,這裏先不講。
下面聊一下redis分布式鎖。
7.2 redis分布式鎖
在分布式系統中,由於redis分布式鎖相對於更簡單和高效,成為了分布式鎖的首先,被我們用到了很多實際業務場景當中。
使用redis分布式鎖的虛擬碼如下:
publicvoiddoSave(String path,String fileUrl){
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
uploadFile(fileUrl);
sendMessage(fileUrl);
}
returntrue;
}
} finally{
unlock(lockKey,requestId);
}
returnfalse;
}
跟之前使用
synchronized
關鍵字加鎖時一樣,這裏鎖的範圍也太大了,換句話說就是鎖的粒度太粗,這樣會導致整個方法的執行效率很低。
其實只有建立目錄的時候,才需要加分布式鎖,其余程式碼根本不用加鎖。
於是,我們需要最佳化一下程式碼:
publicvoiddoSave(String path,String fileUrl){
if(this.tryLock()) {
mkdir(path);
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
privatebooleantryLock(){
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
returntrue;
}
} finally{
unlock(lockKey,requestId);
}
returnfalse;
}
上面程式碼將加鎖的範圍縮小了,只有建立目錄時才加了鎖。這樣看似簡單的最佳化之後,介面效能能提升很多。說不定,會有意外的驚喜喔。哈哈哈。
redis分布式鎖雖說好用,但它在使用時,有很多註意的細節,隱藏了很多坑,如果稍不註意很容易踩中。
7.3 資料庫分布式鎖
mysql資料庫中主要有三種鎖:
表鎖:加鎖快,不會出現死結。但釘選粒度大,發生鎖沖突的機率最高,並行度最低。
行鎖:加鎖慢,會出現死結。但釘選粒度最小,發生鎖沖突的機率最低,並行度也最高。
間隙鎖:開銷和加鎖時間界於表鎖和行鎖之間。它會出現死結,釘選粒度界於表鎖和行鎖之間,並行度一般。
並行度越高,意味著介面效能越好。
所以資料庫鎖的最佳化方向是:
優先使用
行鎖
,其次使用
間隙鎖
,再其次使用
表鎖
。
趕緊看看,你用對了沒?
8.分頁處理
有時候我會呼叫某個介面批次查詢數據,比如:透過使用者id批次查詢出使用者資訊,然後給這些使用者送積分。
但如果你一次性查詢的使用者數量太多了,比如一次查詢2000個使用者的數據。參數中傳入了2000個使用者的id,遠端呼叫介面,會發現該使用者查詢介面經常超時。
呼叫程式碼如下:
List<User> users = remoteCallUser(ids);
眾所周知,呼叫介面從資料庫獲取數據,是需要經過網路傳輸的。如果數據量太大,無論是獲取數據的速度,還是網路傳輸受限於頻寬,都會導致耗時時間比較長。
那麽,這種情況要如何最佳化呢?
答:
分頁處理
。
將一次獲取所有的數據的請求,改成分多次獲取,每次只獲取一部份使用者的數據,最後進行合並和匯總。
其實,處理這個問題,要分為兩種場景:
同步呼叫
和
異步呼叫
。
8.1 同步呼叫
如果在
job
中需要獲取2000個使用者的資訊,它要求只要能正確獲取到數據就好,對獲取數據的總耗時要求不太高。
但對每一次遠端介面呼叫的耗時有要求,不能大於500ms,不然會有信件預警。
這時,我們可以同步分頁呼叫批次查詢使用者資訊介面。
具體範例程式碼如下:
List<List<Long>> allIds = Lists.partition(ids,200);
for(List<Long> batchIds:allIds) {
List<User> users = remoteCallUser(batchIds);
}
程式碼中我用的
google
的
guava
工具中的
Lists.partition
方法,用它來做分頁簡直太好用了,不然要巴拉巴拉寫一大堆分頁的程式碼。
8.2 異步呼叫
如果是在
某個介面
中需要獲取2000個使用者的資訊,它考慮的就需要更多一些。
除了需要考慮遠端呼叫介面的耗時之外,還需要考慮該介面本身的總耗時,也不能超時500ms。
這時候用上面的同步分頁請求遠端介面,肯定是行不通的。
那麽,只能使用
異步呼叫
了。
程式碼如下:
List<List<Long>> allIds = Lists.partition(ids,200);
final List<User> result = Lists.newArrayList();
allIds.stream().forEach((batchIds) -> {
CompletableFuture.supplyAsync(() -> {
result.addAll(remoteCallUser(batchIds));
return Boolean.TRUE;
}, executor);
})
使用CompletableFuture類,多個執行緒異步呼叫遠端介面,最後匯總結果統一返回。
9.加緩存
解決介面效能問題,
加緩存
是一個非常高效的方法。
但不能為了緩存而緩存,還是要看具體的業務場景。畢竟加了緩存,會導致介面的復雜度增加,它會帶來數據不一致問題。
在有些並行量比較低的場景中,比如使用者下單,可以不用加緩存。
還有些場景,比如在商城首頁顯示商品分類的地方,假設這裏的分類是呼叫介面獲取到的數據,但頁面暫時沒有做靜態化。
如果查詢分類樹的介面沒有使用緩存,而直接從資料庫查詢數據,效能會非常差。
那麽如何使用緩存呢?
9.1 redis緩存
通常情況下,我們使用最多的緩存可能是:
redis
和
memcached
。
但對於java套用來說,絕大多數都是使用的redis,所以接下來我們以redis為例。
由於在關系型資料庫,比如:mysql中,選單是有上下級關系的。某個四級分類是某個三級分類的子分類,這個三級分類,又是某個二級分類的子分類,而這個二級分類,又是某個一級分類的子分類。
這種儲存結構決定了,想一次性查出這個分類樹,並非是一件非常容易的事情。這就需要使用程式遞迴查詢了,如果分類多的話,這個遞迴是比較耗時的。
所以,如果每次都直接從資料庫中查詢分類樹的數據,是一個非常耗時的操作。
這時我們可以使用緩存,大部份情況,介面都直接從緩存中獲取數據。操作redis可以使用成熟的框架,比如:jedis和redisson等。
用jedis虛擬碼如下:
String json = jedis.get(key);
if(StringUtils.isNotEmpty(json)) {
CategoryTree categoryTree = JsonUtil.toObject(json);
return categoryTree;
}
return queryCategoryTreeFromDb();
先從redis中根據某個key查詢是否有選單數據,如果有則轉換成物件,直接返回。如果redis中沒有查到選單數據,則再從資料庫中查詢選單數據,有則返回。
此外,我們還需要有個job每隔一段時間,從資料庫中查詢選單數據,更新到redis當中,這樣以後每次都能直接從redis中獲取選單的數據,而無需存取資料庫了。
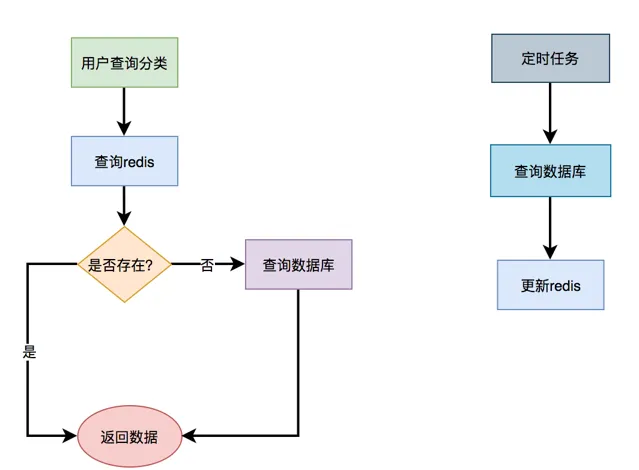
但這樣做效能提升不是最佳的,還有其他的方案,我們一起看看下面的內容。
9.2 二級緩存
上面的方案是基於redis緩存的,雖說redis存取速度很快。但畢竟是一個遠端呼叫,而且選單樹的數據很多,在網路傳輸的過程中,是有些耗時的。
有沒有辦法,不經過請求遠端,就能直接獲取到數據呢?
答:使用
二級緩存
,即基於記憶體的緩存。
除了自己手寫的記憶體緩存之後,目前使用比較多的記憶體緩存框架有:guava、Ehcache、caffine等。
我們在這裏以
caffeine
為例,它是spring官方推薦的。
第一步,引入caffeine的相關jar包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.0</version>
</dependency>
第二步,配置CacheManager,開啟EnableCaching
@Configuration
@EnableCaching
public classCacheConfig{
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
//Caffeine配置
Caffeine<Object, Object> caffeine = Caffeine.newBuilder()
//最後一次寫入後經過固定時間過期
.expireAfterWrite(10, TimeUnit.SECONDS)
//緩存的最大條數
.maximumSize(1000);
cacheManager.setCaffeine(caffeine);
return cacheManager;
}
}
第三步,使用Cacheable註解獲取數據
@Service
public classCategoryService{
@Cacheable(value = "category", key = "#categoryKey")
public CategoryModel getCategory(String categoryKey){
String json = jedis.get(categoryKey);
if(StringUtils.isNotEmpty(json)) {
CategoryTree categoryTree = JsonUtil.toObject(json);
return categoryTree;
}
return queryCategoryTreeFromDb();
}
}
呼叫categoryService.getCategory()方法時,先從caffine緩存中獲取數據,如果能夠獲取到數據,則直接返回該數據,不進入方法體。
如果不能獲取到數據,則再從redis中查一次數據。如果查詢到了,則返回數據,並且放入caffine中。
如果還是沒有查到數據,則直接從資料庫中獲取到數據,然後放到caffine緩存中。
具體流程圖如下:
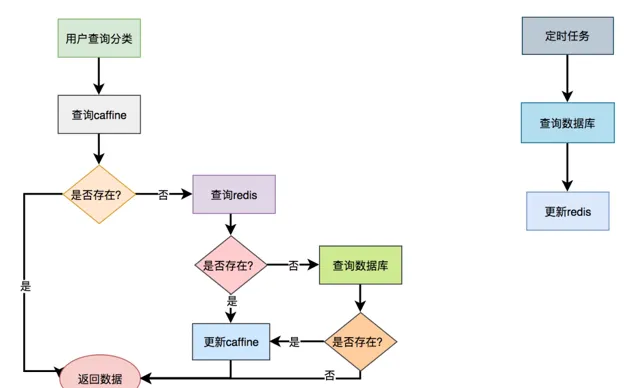
由此可見,二級緩存給我們帶來效能提升的同時,也帶來了數據不一致的問題。使用二級緩存一定要結合實際的業務場景,並非所有的業務場景都適用。
但上面我列舉的分類場景,是適合使用二級緩存的。因為它屬於使用者不敏感數據,即使出現了稍微有點數據不一致也沒有關系,使用者有可能都沒有察覺出來。
10. 分庫分表
有時候,介面效能受限的不是別的,而是資料庫。
當系統發展到一定的階段,使用者並行量大,會有大量的資料庫請求,需要占用大量的資料庫連線,同時會帶來磁盤IO的效能瓶頸問題。
此外,隨著使用者數量越來越多,產生的數據也越來越多,一張表有可能存不下。由於數據量太大,sql語句查詢數據時,即使走了索引也會非常耗時。
這時該怎麽辦呢?
答:需要做
分庫分表
。
如下圖所示:
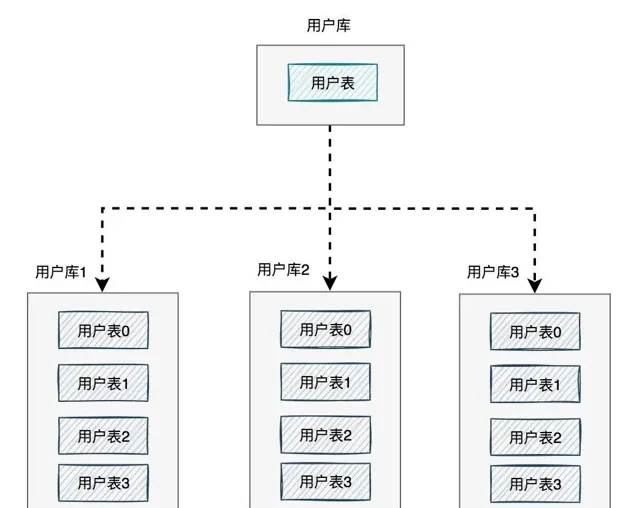
如果有使用者請求過來的時候,先根據使用者id路由到其中一個使用者庫,然後再定位到某張表。
路由的演算法挺多的:
根據id取模
,比如:id=7,有4張表,則7%4=3,模為3,路由到使用者表3。
給id指定一個區間範圍
,比如:id的值是0-10萬,則數據存在使用者表0,id的值是10-20萬,則數據存在使用者表1。
一致性hash演算法
分庫分表主要有兩個方向:
垂直
和
水平
。
說實話垂直方向(即業務方向)更簡單。
在水平方向(即數據方向)上,分庫和分表的作用,其實是有區別的,不能混為一談。
分庫
:是為了解決資料庫連線資源不足問題,和磁盤IO的效能瓶頸問題。
分表
:是為了解決單表數據量太大,sql語句查詢數據時,即使走了索引也非常耗時問題。此外還可以解決消耗cpu資源問題。
分庫分表
:可以解決 資料庫連線資源不足、磁盤IO的效能瓶頸、檢索數據耗時 和 消耗cpu資源等問題。
如果在有些業務場景中,使用者並行量很大,但是需要保存的數據量很少,這時可以只分庫,不分表。
如果在有些業務場景中,使用者並行量不大,但是需要保存的數量很多,這時可以只分表,不分庫。
如果在有些業務場景中,使用者並行量大,並且需要保存的數量也很多時,可以分庫分表。
11. 輔助功能
最佳化介面效能問題,除了上面提到的這些常用方法之外,還需要配合使用一些輔助功能,因為它們真的可以幫我們提升尋找問題的效率。
11.1 開啟慢查詢日誌
通常情況下,為了定位sql的效能瓶頸,我們需要開啟mysql的慢查詢日誌。把超過指定時間的sql語句,單獨記錄下來,方面以後分析和定位問題。
開啟慢查詢日誌需要重點關註三個參數:
slow_query_log
慢查詢開關
slow_query_log_file
慢查詢日誌存放的路徑
long_query_time
超過多少秒才會記錄日誌
透過mysql的
set
命令可以設定:
setglobal slow_query_log='ON';
setglobal slow_query_log_file='/usr/local/mysql/data/slow.log';
setglobal long_query_time=2;
設定完之後,如果某條sql的執行時間超過了2秒,會被自動記錄到slow.log檔中。
當然也可以直接修改配置檔
my.cnf
[mysqld]
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 2
但這種方式需要重新開機mysql服務。
很多公司每天早上都會發一封慢查詢日誌的信件,開發人員根據這些資訊最佳化sql。
11.2 加監控
為了出現sql問題時,能夠讓我們及時發現,我們需要對系統做
監控
。
目前業界使用比較多的開源監控系統是:
Prometheus
。
它提供了
監控
和
預警
的功能。
架構圖如下:
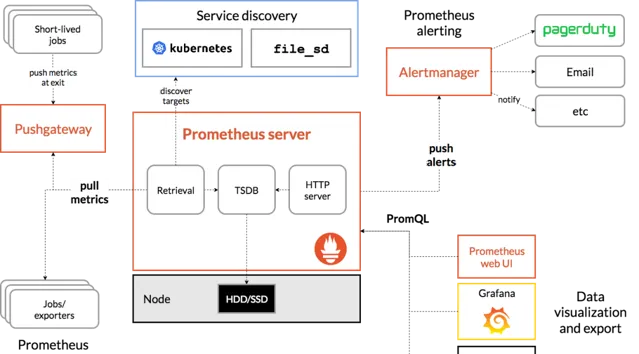
我們可以用它監控如下資訊:
介面響應時間
呼叫第三方服務耗時
慢查詢sql耗時
cpu使用情況
記憶體使用情況
磁盤使用情況
資料庫使用情況
等等。。。
它的界面大概長這樣子:
如果發現數據量連線池占用太多,對介面的效能肯定會有影響。
這時可能是程式碼中開啟了連線忘了關,或者並行量太大了導致的,需要做進一步排查和系統最佳化。
截圖中只是它一小部份功能,如果你想了解更多功能,可以存取Prometheus的官網:https://prometheus.io/
11.3 鏈路跟蹤
有時候某個介面涉及的邏輯很多,比如:查資料庫、查redis、遠端呼叫介面,發mq訊息,執行業務程式碼等等。
該介面一次請求的鏈路很長,如果逐一排查,需要花費大量的時間,這時候,我們已經沒法用傳統的辦法定位問題了。
有沒有辦法解決這問題呢?
用分布式鏈路跟蹤系統:
skywalking
。
架構圖如下:

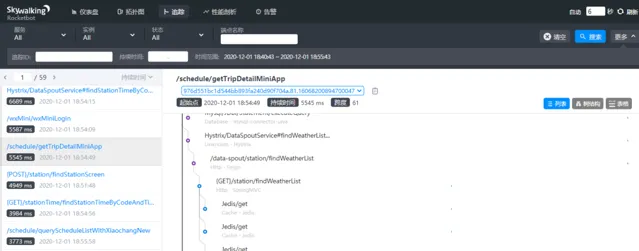
traceId
(全域唯一的id),串聯一個介面請求的完整鏈路。可以看到整個介面的耗時,呼叫的遠端服務的耗時,存取資料庫或者redis的耗時等等,功能非常強大。
之前沒有這個功能的時候,為了定位線上介面效能問題,我們還需要在程式碼中加日誌,手動打印出鏈路中各個環節的耗時情況,然後再逐一排查。
如果你用過skywalking排查介面效能問題,不自覺的會愛上它的。如果你想了解更多功能,可以存取skywalking的官網:https://skywalking.apache.org/
👇🏻 點選下方閱讀原文,獲取魚皮往期編程幹貨。
往期推薦











