原文連結:https://www.cnblogs.com/cjsblog/p/11585145.html
Prometheus(譯:普羅米修斯)用領先的開源監控解決方案為你的指標和警報提供動力(賦能)。
1. 概述
1.1. Prometheus是什麽?
Prometheus是一個開源的系統監控和警報工具包。自2012年啟動以來,許多公司和組織都采用了Prometheus,該計畫擁有非常活躍的開發人員和使用者社群。它現在是一個獨立的開源計畫,獨立於任何公司進行維護。Prometheus於2016年加入雲原生計算基金會,成為繼Kubernetes之後的第二個托管計畫。
1.1.1. Prometheus的主要特性:
一個多維數據模型,包含由指標名稱和鍵/值對(Tag)標識的時間序列數據
PromQL是一種靈活的查詢語音,用於查詢並利用這些維度數據
不依賴分布式儲存,單個伺服器節點是自治的
時間序列收集是透過HTTP上的pull模型進行的(支持Pull)
推播時間序列是透過一個中間閘道器來支持的(也支持Push)
目標是透過服務發現或靜態配置發現的
多種模式的圖形和儀表盤支持
總結一下,就是多維數據模型、PromQL查詢語言、節點自治、HTTP主動拉取或者閘道器主動推播的方式獲取時間序列數據、自動發現目標、多種儀表盤支持
1.1.2. 元件:
Prometheus server,它負責抓取和儲存時間序列數據,是最主要的元件
client libraries,用於檢測應用程式程式碼的客戶端庫
push gateway,用於支持短期的jobs
exporters,用於支持HAProxy等第三方
alertmanager,用於處理告警
各種支持工具
大多數Prometheus元件都是用Go編寫的,這使得它們易於作為靜態二進制檔構建和部署
1.1.3. 架構:
這張圖展示了架構及其生態系的一些組成部份:
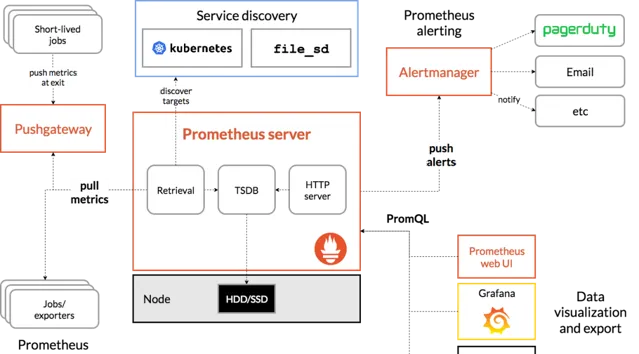
Prometheus從工具化的作業中獲取指標,要麽直接獲取,要麽透過中介推播閘道器獲取短期作業。它在本地儲存所有抓取的樣本,並對這些數據套用規則將這些數據進行聚合,並記錄新的時間序列,或者生成警報。可以用Grafana或其他API來視覺化收集的數據。
1.2. 什麽時候用它合適
Prometheus可以很好地記錄任何純數位時間序列。它既適合以機器為中心的監視,也適合高度動態的面向服務的體系結構的監視。在微服務的世界中,它對多維數據收集和查詢的支持是一個特別的優勢。
Prometheus是為可靠性而設計的,在你的服務宕機的時候,你可以快速診斷問題。每台Prometheus伺服器都是獨立的,不依賴於網路儲存或其他遠端服務。
1.3. 什麽時候用它不合適
Prometheus的值的可靠性。你總是可以檢視有關系統的統計資訊,即使在出現故障的情況下也是如此。如果你需要100%的準確性,例如按請求計費,Prometheus不是一個好的選擇,因為收集的數據可能不夠詳細和完整。在這種情況下,最好使用其他系統來收集和分析用於計費的數據,並使用Prometheus來完成剩下的監視工作。
1.4. Prometheus VS InfluxDB
InfluxDB是一個開源的時間序列資料庫,具有擴充套件和集群的商業選項。InfluxDB計畫是在Prometheus開發開始將近一年後釋出的,所以當時無法考慮將其作為替代方案。盡管如此,Prometheus和fluxdb之間仍然存在顯著的差異。二者有許多相似之處。兩者都有標簽(在InfluxDB中稱為tags)來有效地支持多維度度量。它們基本上使用相同的資料壓縮演算法。兩者都具有廣泛的整合,包括彼此之間的整合。兩者都有掛鉤,允許進一步擴充套件它們,例如在統計工具中分析數據或執行自動化操作。
下列情況,用InfluxDB更好:
如果你正在進行事件日誌記錄
商業選項為InfluxDB提供集群,這對於長期數據儲存也更好
最終實作副本之間數據的一致性
下列情況,用Prometheus更好:
如果你主要做的是度量
如果你需要更強大的查詢語言、警報和通知功能
更高的可用性和正常執行時間,用於繪圖和報警
InfluxDB由一家遵循開放核心模型的商業公司維護,提供高級特性,如閉源集群、托管和支持。
Prometheus是一個完全開源和獨立的計畫,由許多公司和個人維護,其中一些還提供商業服務和支持。
2. 基本概念
2.1. 數據模型
Prometheus基本上將所有數據儲存為時間序列:屬於同一指標和同一組標記維度的時間戳值流。除了儲存時間序列外,Prometheus還可以根據查詢結果生成臨時衍生的時間序列。
(PS:這裏對時間序列的解釋是這樣的,
time series: streams of timestamped values belonging to the same metric and the same set of labeled dimensions
)
2.1.1. Metric names and labels
Every time series is uniquely identified by its metric name and optional key-value pairs called labels .
(每個時間序列都由其指標名稱和稱為標簽的可選鍵值對唯一標識)
指標名稱指定要度量的系統的一般特性(例如,http_requests_total表示接收的HTTP請求的總數)。它可能包含ASCII字母和數位,以及底線和冒號。它必須匹配正規表式[a-zA-Z_:][a-zA-Z0-9_:]*
標簽名稱可以包含ASCII字母、數位和底線。它們必須匹配正規表式[a-zA-Z_][a-zA-Z0-9_]*。以__開頭的標簽名稱保留內部使用。
標簽值可以包含任何Unicode字元。
2.1.2. Sample(樣本)
樣本構成實際的時間序列數據。每個樣本包括:
a float64 value
a millisecond-precision timestamp
2.1.3. notation(記法)
給定一個度量名稱和一組標簽,時間序列通常使用以下符號標識:
<metric name>{<label name>=<label value>,...}
例如,有這樣一個時間序列,指標名稱是api_http_requests_total,有兩個標簽method="POST"和handler="/messages",那麽這個時間序列可以這樣寫:
api_http_requests_total{method="POST", handler="/messages"}
2.2. metric types(指標型別)
2.2.1. Counter(計數器)
計數器是一個累積指標,它表示一個單調遞增的計數器,其值只能在重新開機時遞增或重設為零。例如,可以使用計數器來表示已服務的請求數、已完成的任務數或錯誤數。不要使用計數器來反映一個可能會減小的值。例如,不要使用計數器表示當前正在執行的行程的數量,這種情況下,你應該用gauge。
2.2.2. Gauge(計量器)
計量器表示一個可以任意上下移動的數值。
計量器通常用於測量溫度或當前記憶體使用量等,也用於「計數」,比如並行請求的數量。
2.2.3. Histogram(直方圖、柱狀圖)
直方圖對觀察結果(通常是請求持續時間或響應大小之類的東西)進行采樣,並在可配置的桶中計數。它還提供了所有觀測值的和。
直方圖用一個基本的指標名<basename>暴露在一個抓取期間的多個時間序列:
觀察桶的累積計數器,格式為<basename>_bucket{le="<upper inclusive bound>"}
所有觀測值的總和,格式為<basename>_sum
已觀察到的事件的計數,格式為<basename>_count
2.2.4. Summary(摘要)
與柱狀圖類似,摘要樣例觀察結果(通常是請求持續時間和響應大小之類的內容)。雖然它還提供了觀測值的總數和所有觀測值的總和,但它計算了一個滑動時間視窗上的可配置分位數。
2.3. Jobs AND Instances(作業與例項)
在Prometheus的術語中,可以抓取的端點稱為例項,通常對應於單個行程。具有相同目的的例項集合稱為作業。
例如,一個API Server job 有4個副本instances:
job : api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671
2.3.1. 自動生成標簽和時間序列
當Prometheus抓取目標時,它會自動在抓取的時間序列上附加一些標簽,用來辨識被抓取的目標:
job:目標所屬的已配置作業名稱
instance:<host>:<port>是被抓取的目標URL的一部份
3. 快速開始
Prometheus是一個開源的系統監控和警報工具包,具有活躍的生態系。
3.1. 下載與安裝
Prometheus是一個監控平台,它透過抓取這些目標上的HTTP端點來收集被監控目標的指標。
需要下載、安裝並執行Prometheus。還需要下載並安裝一個exporter,它是將主機和服務上的時間序列數據匯出的工具。
https://prometheus.io/download/
在執行Prometheus之前,我們先配置一下
3.1.1. 配置Prometheus監視它自己
Prometheus透過抓取目標上的HTTP端點數據來從被監控的目標收集數據。由於Prometheus也以同樣的方式公開自己的數據,因此它還可以抓取和監測自己的健康狀況。
雖然Prometheus伺服器在實踐中只收集關於自己的數據不是很有用,但是它是一個很好的開始範例。將以下基本的Prometheus配置保存為一個名為Prometheus.yml的檔:
1global:2scrape_interval: 15s # By default, scrape targets every 15 seconds.34# Attach these labels to any time series or alerts when communicating with5# external systems (federation, remote storage, Alertmanager).6external_labels:7monitor: 'codelab-monitor'89# A scrape configuration containing exactly one endpoint to scrape:10# Here it's Prometheus itself.11scrape_configs:12# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.13- job_name: 'prometheus'1415# Override the global default and scrape targets from this job every 5 seconds.16scrape_interval: 5s1718static_configs:19- targets: ['localhost:9090']
3.1.2. 啟動Prometheus
1# Start Prometheus.2# By default, Prometheus stores its database in ./data (flag --storage.tsdb.path).3./prometheus --config.file=prometheus.yml

3.2. 配置
Prometheus可以透過命令列和配置檔進行配置。配置檔定義了與抓取作業及其例項相關的所有內容,以及要載入哪些規則檔。
執行./prometheus -h可以檢視所有支持的命令
為了指定要載入哪個配置檔,請使用--config選項
配置檔是YAML格式的
配置項太多,不一一列舉,自行檢視
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
global: # How frequently to scrape targets by default.[scrape_interval: <duration> | default = 1m ] # How long until a scrape request times out.[scrape_timeout: <duration> | default = 10s ] # How frequently to evaluate rules.[evaluation_interval: <duration> | default = 1m ] # The labels to add to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager).external_labels:[<labelname>: <labelvalue> ... ] # Rule files specifies a list of globs. Rules and alerts are read from # all matching files.rule_files:[- <filepath_glob> ... ] # A list of scrape configurations.scrape_configs:[- <scrape_config> ... ] # Alerting specifies settings related to the Alertmanager.alerting:alert_relabel_configs:[- <relabel_config> ... ]alertmanagers:[- <alertmanager_config> ... ] # Settings related to the remote write feature.remote_write:[- <remote_write> ... ] # Settings related to the remote read feature.remote_read:[- <remote_read> ... ]
這裏有一個有效的範例配置檔
3.3. 查詢
Prometheus提供了一種名為 PromQL (Prometheus查詢語言)的函式式查詢語言,允許使用者即時選擇和聚合時間序列數據。運算式的結果既可以顯示為圖形,也可以在Prometheus的運算式瀏覽器中作為表格數據檢視,或者透過HTTP API由外部系統使用。
3.3.1. 運算式數據型別
在Prometheus的運算式語言中,運算式或子運算式可以計算為以下四種型別之一:
Instant vector(瞬時向量) :一組時間序列,每個時間序列包含一個樣本,所有樣本共享相同的時間戳
Range vector(範圍向量) :一組時間序列,其中包含每個時間序列隨時間變化的數據點範圍
Scalar(純量) :一個簡單的數值浮點值
String(字串) :一個簡單的字串值,目前未使用
3.3.2. 字面值
字串字面值
字串可以指定為單引號、雙引號或反引號中的文字。例如:
1"this is a string"2'these are unescaped: \n \\ \t'3`these are not unescaped: \n ' " \t`
浮點數位面值
例如:-2.34
3.3.3. 時間序列選擇器
瞬時向量選擇器
瞬時向量選擇器允許在給定的時間戳(瞬時)上為每個時間序列選擇一組時間序列和一個樣本值:在最簡單的形式中,只指定一個度量名稱。這樣一個向量就會包含這個度量名稱的所有時間序列元素。
下面的例子,選擇指標名稱是http_requests_total的所有時間序列:
http_requests_total
透過在花括弧( { } )中添加一組匹配的標簽,可以進一步過濾這些時間序列。
下面的例子,選擇指標名稱是http_requests_total,並且有job標簽值是prometheus,並且group標簽值是canary的時間序列:
http_requests_total{job="prometheus",group="canary"}
標簽匹配操作符:
= :選擇與提供的字串完全相同的標簽(等於)
!= :選擇不等於提供的字串的標簽(不等於)
=~ :正則匹配
!~ :非正則匹配
下面的例子,選擇所有staging, testing, development環境,並且HTTP請求方式不是GET的http_requests_total時間序列
http_requests_total{environment=~"staging|testing|development",method!="GET"}
不要匹配空標簽
{job=~".+"} # Good! {job=~".*",method="get"} # Good!
3.3.4. 範圍向量選擇器
範圍向量字面量的工作原理與瞬時向量字面量類似,只是它們從當前瞬時量中選擇一個樣本範圍。從語法上講,範圍持續時間被添加到向量選擇器末尾的方括弧( [ ] )中,以指定應該為每個結果範圍向量元素獲取多少時間值。
時間期限指定為一個數位,緊接其後的是下列單位之一:s(秒)、m(分鐘)、h(小時)、d(天) 、w(周)、y(年)
下面的例子,選擇指標名是http_requests_total,且job標簽值是prometheus的已經記錄的最近5分鐘內的時間序列:
http_requests_total{job="prometheus"}[5m]
Offset修飾詞
下面的運算式返回http_requests_total在過去5分鐘相對於當前查詢計算時間的值:
http_requests_total offset 5m
註意,offset總是緊跟在選擇器後面的
sum(http_requests_total{method="GET"} offset 5m)
下面的例子,返回一周前的最近5分鐘http_requests_total的時間序列
rate(http_requests_total[5m] offset 1w)
3.3.5. 子查詢
Syntax: <instant_query> '[' <range> ':' [<resolution>] ']' [ offset <duration> ]
3.3.5. 運算子
Prometheus的查詢語言支持基本的邏輯運算子和算術運算子。
算術二元運算子
+(加)、-(減)、*(乘)、/(除)、%(余數)、^(指數)
二進制算術運算子定義在純量/純量、向量/純量和向量/向量值對之間
比較二元運算子
== 、!= 、> 、< 、>= 、<=
邏輯運算子
and 、or 、unless
聚合運算子
sum(求和)、min(最小值)、max(最大值)、avg(求平均)、stddev(標準偏差)、stdvar(變異數)、count(個數)、count_values(相同值的元素個數)、bottomk(樣本值的最小元素)、topk(樣本值的最大元素)、quantile(0 ≤ φ ≤ 1)
這些操作符既可以用於聚合所有標簽維度,也可以透過包含without子句或by子句來保存不同的維度。
1 <aggr-op>([parameter,] <vectorexpression>) [without|by (<labellist>)]
例如,假設http_requests_total有application 、 instance 、 group三個標簽,那麽下面兩個是等價的:
1 sum(http_requests_total) without (instance)2 sum(http_requests_total) by (application, group)
3.3.6. 函式
https://prometheus.io/docs/prometheus/latest/querying/functions/
3.3.7. 範例
1# 返回http_requests_total的所有時間序列2http_requests_total34# 返回http_requests_total的且限定了job和handler標簽的時間序列5http_requests_total{job="apiserver", handler="/api/comments"}6http_requests_total{job="apiserver", handler="/api/comments"}[5m]78# 正規表式9http_requests_total{job=~".*server"}10http_requests_total{status!~"4.."}1112# 過去的5分鐘內每秒HTTP請求速率13rate(http_requests_total{job="api-server"}[5m])14# 過去的30分鐘內每5分鐘15rate(http_requests_total[5m])[30m:1m]16# 過去5分鐘的所有請求速率求和,保留job維度17sum(rate(http_requests_total[5m])) by (job)18# cpu使用率最高的前3個19topk(3, sum(rate(instance_cpu_time_ns[5m])) by (app, proc))
4. Grafana支持
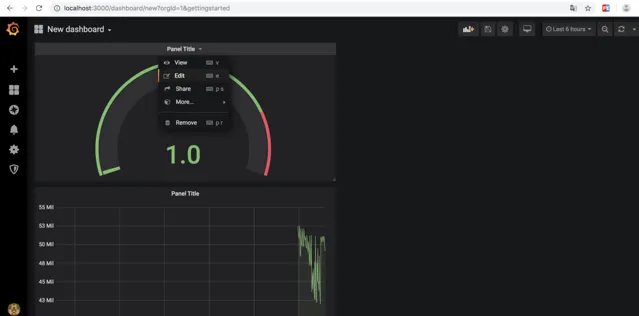
Grafana支持查詢Prometheus
下面是Grafana dashboard查詢Prometheus數據的例子:
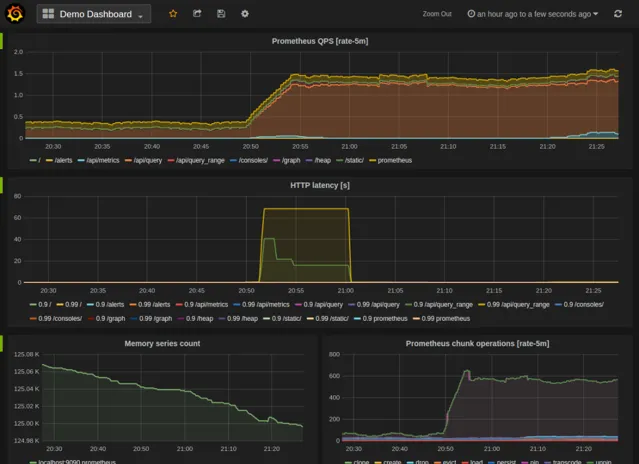
使用
預設情況下,Grafana監聽http://localhost:3000,預設用admin/admin登入
建立一個Prometheus資料來源,接著建立面板並定義查詢的指標

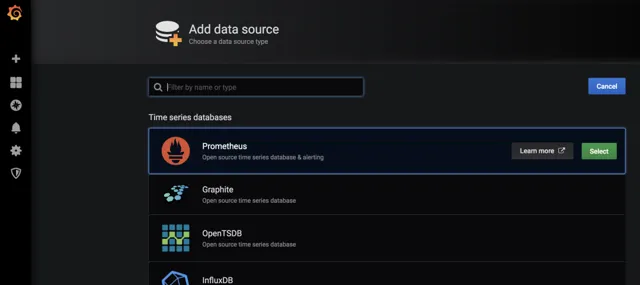
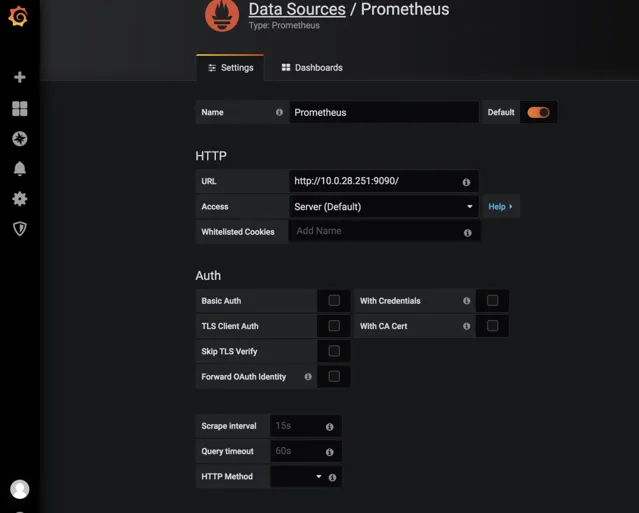
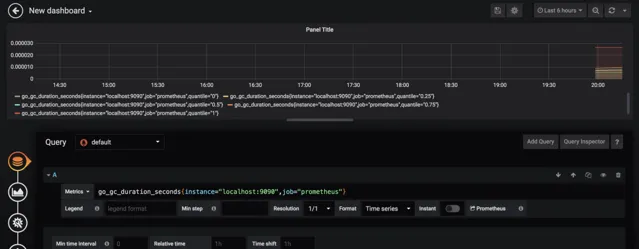
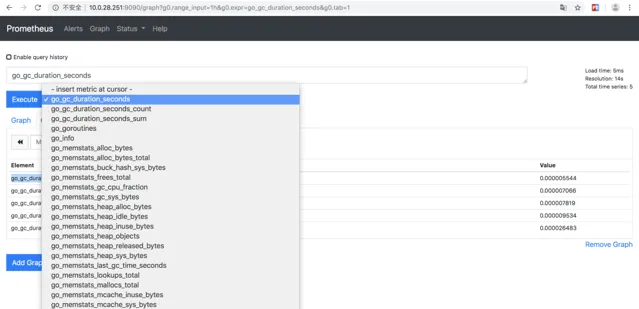
剛開始,如果不知道PromeQL怎麽寫,可以去Prometheus上去找 http://localhost:9090/graph
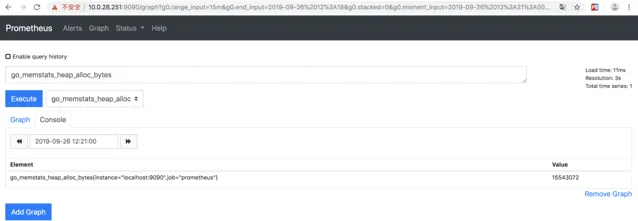
https://prometheus.io/docs/introduction/overview/
https://prometheus.io/docs/alerting/overview/
往期推薦

點亮,伺服器三年不宕機











