作者:碼猿技術專欄
連結:https://juejin.cn/post/7176428890896728101
插入式註解處理器在【深入理解Java虛擬機器】一書中有一些介紹(前端編譯篇有提到),但一直沒有機會使用,直到碰到這個需求,覺得再合適不過了,就簡單用了一下,這裏做個記錄。
了解過lombok底層原理的都知道其使用的就是的插入式註解,那麽今天筆者就以真實場景演示一下插入式註解的使用。
# 需求
我們為公司提供了一套通用的JAVA基礎元件包,元件包內有不同的模組,比如熔斷模組、負載均模組、rpc模組等等,這些模組均會被打成jar包,然後釋出到公司的內部程式碼倉庫中,供其他人引入使用。
這份程式碼會不斷的叠代,我們希望可以透過promethus來監控現在公司內使用各版本程式碼庫的比例,希望達到的效果圖如下:
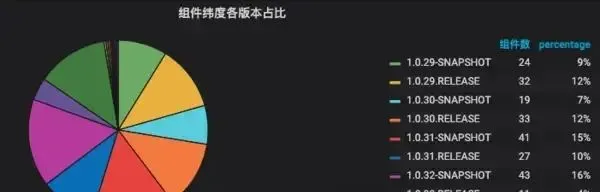
我們希望看到每一個版本的使用率,這有利於我們做版本相容,必要的時候可以對古早版本使用者溯源。
# 問題
需求似乎很簡單,但真要獲取自身的jar版本號還是挺麻煩的,有個比較簡單但陰間的辦法,就是給每一個元件都加上當前的jar版本號,寫到配置檔裏或者直接設定成常量,這樣上報promethus時就可以直接獲取到jar包版本號了,這個方法雖然可以解決問題,但每次叠代版本都要跟著改一遍所有元件包的版本號數據,過於麻煩。
有沒有更好的解決辦法呢?比如我們可不可以在gradle打包構建時拿到jar包的版本號,然後註入到每個元件中去呢?就像lombok那樣,不需要寫get、set方法,只需要加個註解標記就可以自動註入get、set方法。
比如我們可以給每個元件定義一個空常量,加上自訂的註解:
@TrisceliVersionpublicstatic final String version = "";
然後像lombok生成set/get方法那樣註入真正的版本號:
@TrisceliVersionpublicstatic final String version = "1.0.31-SNAPSHOT";
參考lombok的實作,這其實是可以做到的,下面來看解決方案。
# 解決
java中解析一個註解的方式主要有兩種:編譯期掃描、執行期反射,這是lombok @Setter的實作:
@Target({ElementType.FIELD, ElementType.TYPE})@Retention(RetentionPolicy.SOURCE)public@interface Setter {// 略...}
可以看到@Setter的Retention是SOURCE型別的,也就是說這個註解只在編譯期有效,它甚至不會被編入 class檔,所以lombok無疑是第一種解析方式,那用什麽方式可以在編譯期就讓註解被解析到並執行我們的解析程式碼呢?
答案就是定義插入式註解處理器(透過JSR-269提案定義的Pluggable Annotation Processing API實作)
插入式註解處理器的觸發點如下圖所示:
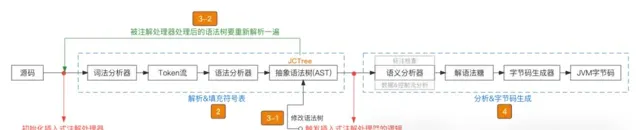
也就是說插入式註解處理器可以幫助我們在編譯期修改抽象語法樹(AST)!所以現在我們只需要自訂一個這樣的處理器,然後其內部拿到jar版本資訊(因為是編譯期,可以找到源碼的path,源碼裏隨便搞個檔存放版本號,然後用java io讀取進來即可),再將註解對應語法樹上的常量值設定成jar包版本號,語法樹變了,最終生成的字節碼也會跟著變,這樣就實作了我們想在編譯期給常量version註入值的願望。
自訂一個插入式註解處理器也很簡單,首先要將自己的註解定義出來:
@Documented@Retention(RetentionPolicy.SOURCE)//只在編譯期有效,最終不會打進 class檔中@Target({ElementType.FIELD})//僅允許作用於類內容之上public@interface TrisceliVersion {}
然後定義一個繼承了AbstractProcessor的處理器:
/** * {@link AbstractProcessor} 就屬於 Pluggable Annotation Processing API */public classTrisceliVersionProcessorextendsAbstractProcessor{private JavacTrees javacTrees;private TreeMaker treeMaker;private ProcessingEnvironment processingEnv;/** * 初始化處理器 * * @param processingEnv 提供了一系列的實用工具 */@SneakyThrows@Overridepublic synchronized void init(ProcessingEnvironment processingEnv) {super.init(processingEnv);this.processingEnv = processingEnv;this.javacTrees = JavacTrees.instance(processingEnv); Context context = ((JavacProcessingEnvironment) processingEnv).getContext();this.treeMaker = TreeMaker.instance(context); }@Overridepublic SourceVersion getSupportedSourceVersion() {return SourceVersion.latest(); }@Overridepublic Set<String> getSupportedAnnotationTypes() { HashSet<String> set = new HashSet<>();set.add(TrisceliVersion. class.getName()); // 支持解析的註解returnset; }@Overridepublic boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {for (TypeElement t : annotations) {for (Element e : roundEnv.getElementsAnnotatedWith(t)) { // 獲取到給定註解的element(element可以是一個類、方法、包等)// JCVariableDecl為欄位/變量定義語法樹節點 JCTree.JCVariableDecl jcv = (JCTree.JCVariableDecl) javacTrees.getTree(e); String varType = jcv.vartype.type.toString();if (!"java.lang.String".equals(varType)) { // 限定變量型別必須是String型別,否則拋異常 printErrorMessage(e, "Type '" + varType + "'" + " is not support."); } jcv.init = treeMaker.Literal(getVersion()); // 給這個欄位賦值,也就是getVersion的返回值 } }returntrue; }/** * 利用processingEnv內的Messager物件輸出一些日誌 * * @param e element * @param m error message */private void printErrorMessage(Element e, String m) { processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR, m, e); }private String getVersion() {/** * 獲取version,這裏省略掉復雜的程式碼,直接返回固定值 */return"v1.0.1"; }
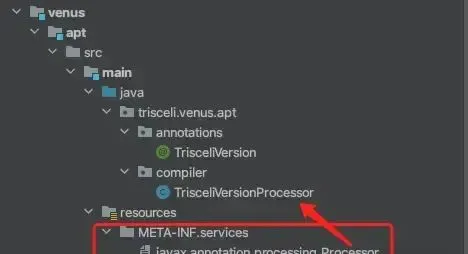
定義好的處理器需要SPI機制被發現,所以需要定義META.services:
# 測試
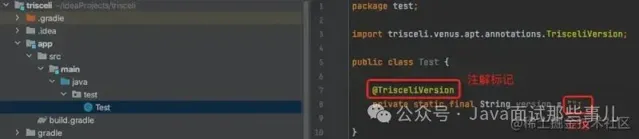
新建測試模組,引入剛才寫好的程式碼包:
這是Test類:
現在我們只需要讓gradle build一下,新得到的字節碼中該欄位就有值了:
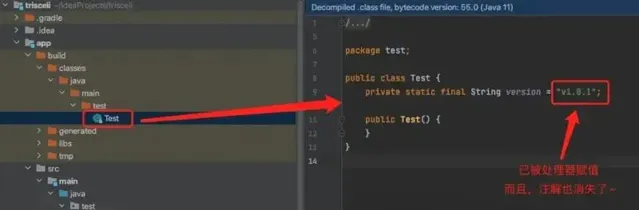
這只是插入式註解處理器功能的冰山一角,既然它可以透過修改抽象語法樹來控制生成的字節碼,那麽自然就有人能充分利用其特性來實作一些很酷的外掛程式,比如lombok,我們再也不用寫諸如set/get這種樣版式的程式碼了,只要我們足夠有創意,就可以讓基於這一套API實作的外掛程式在功能上有很大的發揮空間。
熱門推薦











