這一天來的猝不及防,一夜之間「王位」易主!!
Transformer架構作為現在AI領域的霸主,地位不保😱😱
最新釋出的測試時間訓練層
Test-Time Training——TTT
橫空出世!
TTT是具有表達性隱藏狀態的 RNN層,它能夠 代替 Transformer中的自註意力層。
這個一舉打敗transformer和mamba的新層次架構近日在AI界掀起驚濤駭浪,吸引了所有人的註意。
作者分別來自史丹佛、加州柏克萊、加州聖地牙哥和 Meta聯合研究發表。

掃碼加入AI交流群
獲得更多技術支持和交流

Transformer的自註意力層在處理長文本上下文時表現突出,但其計算復雜度為二次方,成本十分昂貴。
而Mamba中的迴圈神經網路RNN層會在時間步上壓縮為固定大小,在處理非常長文本時,隱藏狀態表達能力十分受限。
由此產生了一個奇妙的想法:能不能讓隱藏狀態像模型一樣學習?🤔
於是TTT將RNN隱藏狀態本身變成一個機器學習模型,並將更新規則設定為自監督學習的一個步驟,自監督學習將上下文壓縮為模型權重進行參數學習。
這種創新使得隱藏狀態在測試序列上的更新相當於在測試時間進行訓練,因此被稱為 測試時間訓練層 。TTT因此具有 線性復雜度和強大的隱藏狀態表達能力。
參數學習器需要定義模型和最佳化器,每個學習器唯一地誘導一個TTT層。團隊提出了兩個誘導 TTT 層:TTT-Linear 和 TTT-MLP,其中隱藏狀態分別是線性模型和兩層多層感知機MLP。
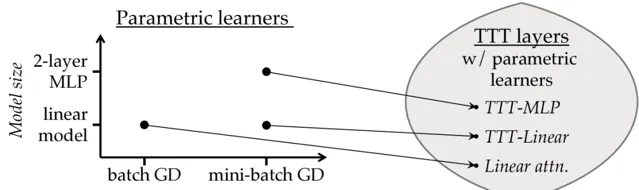
團隊在規模從125M到1.3B參數的模型上對TTT-Linear和TTT-MLP進行了評估,並與Transformer和Mamba進行了比較。
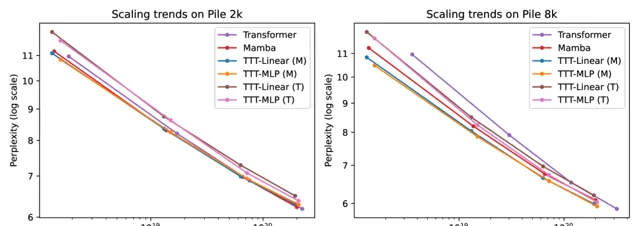
與Mamba和Transformer相比,TTT-Linear 具有更好的困惑度和更少的 FLOPs,並且更好地利用了長上下文。
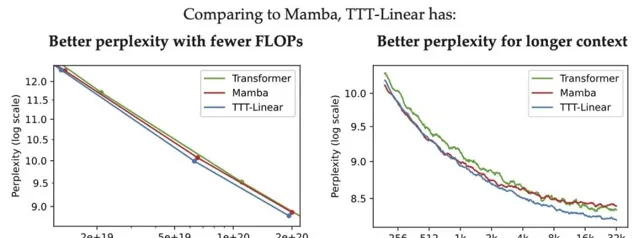
TTT-MLP 與TTT-Linear相比在短上下文中的表現略差,但在長上下文中表現更好,這表現出作為隱藏狀態的 MLP 比線性模型更具表現力。
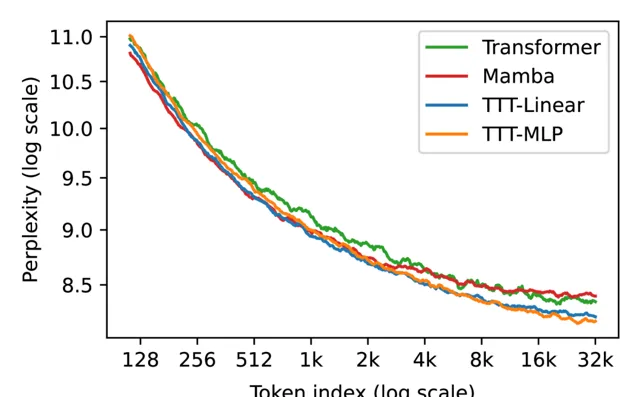
團隊在大規模數據集The Pile 上下文長度 2k 和 8k 進行評估,TTT的表現都比較優秀。
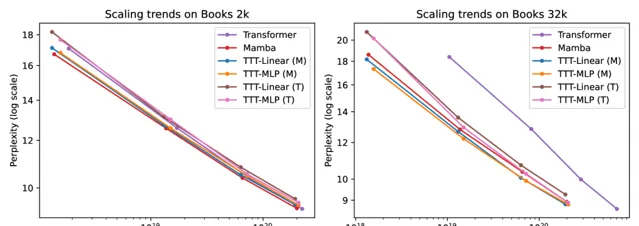
為了評估長上下文中的能力,團隊使用從 1k 到 32k 的上下文長度的Pile 的一個流行子集 Books進行評估。
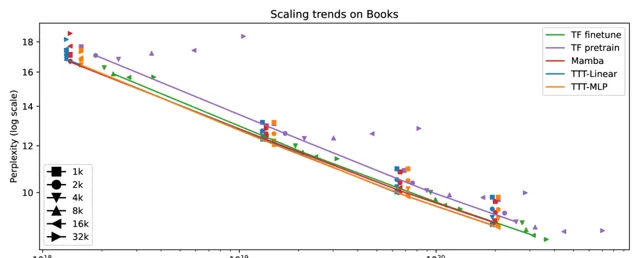
同時團隊在上下文長度從1k到32k的Books上進行實驗,將上下文長度視為超參數並連線選定的點,得到完整結果,其中包括效能更好的微調後的transformer。
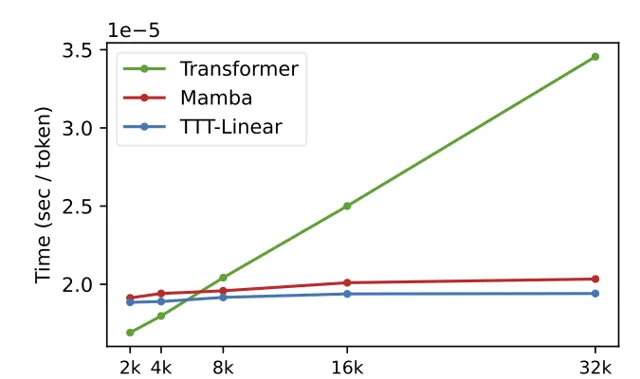
TTT層在硬體效率方面也進行了最佳化,透過小批次TTT和雙重形式,使TTT-Linear在8k上下文長度時已經比Transformer更快,和Mamba持平,並隨著上下文的增加差距愈加明顯。
由此大量比較數據可見TTT-Linear和TTT-MLP在多個實驗中表現優異,小編相信這會在未來研究中的閃閃發光。
盡管TTT-Linear和TTT-MLP在現有實驗中表現出色,但TTT-MLP在記憶體I/O方面仍面臨挑戰,且在長文本上下文中顯示出更大的潛力。
這為未來的研究指出了一個有前景的方向,即進一步最佳化TTT層的記憶體使用和平行計算能力。
🔗 計畫連結 :
https://github.com/test-time-training/ttt-lm-jax
關註「 向量光年 」公眾號
加速全行業向AI的改變
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新咨詢











