作者:奇月
轉自:量子位 | 公眾號 QbitAI
提速8倍!
速度更快、效果更好的混元視訊模型—— FastHunyuan 來了!
新模型僅用 1分鐘 就能生成 5秒 長的視訊,比之前提速 8倍 ,步驟也從50步減少到了 6步 ,甚至畫面細節也更逼真了。
和普通速度的混元對比一下,原來50步才能生成1條視訊,而現在新模型在相同的時間裏可以生成 8條 :
再來看看和Sora的畫面對比,可以看到Fast-Hunyuan和Sora兩者的效果都更逼真一些,衣服、水果和山峰的細節也非常清晰。
甚至在一些 物理細節的理解 上,Fast-Hunyuan比Sora還強,比如下面拿取檸檬的視訊:
更重要的是,Fast-Hunyuan的程式碼也 開源 了,這下不用為Sora的訂閱費和限額發愁了。
研究團隊來自 加州大學聖地亞哥分校(UCSD) 的 Hao AI 實驗室,他們主要專註機器學習演算法和分布式系統的研究。


混元官方帳號還特意發博感謝了他們:
有網友看完後直呼,混元才是最好的開源視訊模型。
開創性的視訊DiT蒸餾配方
團隊是如何做到8倍提速的情況下還能提升視訊解析度呢?
下面就一起來看一下Fast-Hunyuan的技術原理——
首先,他們開發了全新的 視訊DiT蒸餾配方 。
具體來說,他們的蒸餾配方基於 階段一致性(Phased Consistency Model, PCM)模型 。
在嘗試使用多階段蒸餾後發現效果沒有顯著改進,最終他們選擇 保持單階段設定 ,與原始PCM模型的配置相似。
其次,團隊使用了OpenSoraPlan中的 MixKit數據集 進行了蒸餾。
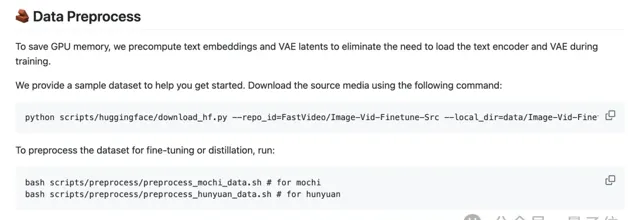
為了避免在訓練過程中執行文本編碼器和VAE,團隊還 預處理 了所有數據,用來生成文本嵌入和VAE潛在變量。
在推理階段,使用者可以透過FSDP、序列並列和選擇性啟用檢查點進行 可延伸訓練 ,模型可以近乎線性擴充套件到64個GPU。測試程式碼在Python 3.10.0、CUDA 12.1和H100上執行。
官方推薦使用80GB記憶體的GPU,不同模型有相應的下載權重和推理命令。
最低硬體要求 如下:
40 GB GPU 記憶體,每個 GPU 配備 lora
30 GB GPU 記憶體,每 2 個 GPU 配備 CPU 解除安裝和 LoRa。
在模型微調方面,Fast-Hunyuan提供了 全微調 (需準備符合格式的數據,提供了一些可下載的預處理數據及對應命令)和 LoRA 微調 (即將上線)兩種方式。
此外,他們還結合了 預計算潛變量 和 預計算文本嵌入 ,使用者可以根據自己的硬體條件選擇不同的微調方式來執行命令,也支持影像和視訊的 混合微調 。
模型已於2024年12月17日釋出了v0.1版本。
未來的開發計劃還包括添加 更多蒸餾方法 (如分布匹配蒸餾)、支持 更多模型 (如CogvideoX模型)以及 程式碼更新 (如fp8支持、更快的載入和保存模型支持)等等。

One More Thing
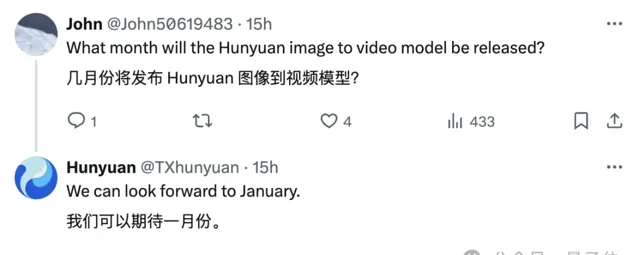
除了加速模型,混元還預告了大家都非常期待的 影像到視訊 生成功能。
最快 1月份 ,也就是下個月就可以看到!期待住了。
GitHub:https://github.com/hao-ai-lab/FastVideo
HuggingFace:https://huggingface.co/FastVideo/FastHunyuan
參考連結:
[1]https://x.com/TXhunyuan/status/1869282002786292097
— 完 —











