作者簡介:馬宜萱,西安郵電大學研一在讀,作業系統愛好者,主要方向為記憶體方向。目前在學習作業系統底層原理和內核編程。
記憶體檢測
一般的記憶體存取錯誤如下
越界存取(out-of-bounds)。
存取已經被釋放的記憶體(use after free)。
重復釋放(double free)。
記憶體泄漏(memory leak)。
棧溢位(stack overflow)。
跟蹤記憶體活動的各種事件源
| 事件型別 | 事件源 |
|---|---|
| 使用者態記憶體分配 | 使用uprobes跟蹤記憶體分配器函式,使用USDT probes跟蹤libc |
| 內核態記憶體分配 | 使用kprobes跟蹤記憶體分配器函式,以及kmem跟蹤點 |
| 堆記憶體擴充套件 | brk系統呼叫跟蹤點 |
| 共享記憶體函式 | 系統呼叫跟蹤點 |
| 缺頁錯誤 | kprobes、軟體事件、exception跟蹤點 |
| 頁面遷移 | migration跟蹤點 |
| 頁面壓縮 | compaction跟蹤點 |
| VM掃描器 | Vmscan跟蹤點 |
| 記憶體存取周期 | PMC |
對使用libc記憶體分配器的行程來說,libc提供了⼀系列記憶體分配的函式,包括malloc()和 free()等。在libc庫中已經內建了一些USDT追蹤點,可以在應用程式中使用這些追蹤點來監視libc的行為。
以下是libc中可用的USDT探針:
# sudo bpftrace -l usdt:/lib/x86_64-linux-gnu/libc-2.31.so
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:setjmp
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:longjmp
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:longjmp_target
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:lll_lock_wait_private
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_arena_max
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_arena_test
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tunable_tcache_max_bytes
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tunable_tcache_count
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tunable_tcache_unsorted_limit
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_trim_threshold
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_top_pad
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_mmap_threshold
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_mmap_max
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_perturb
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_mxfast
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_new
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_reuse_free_list
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_reuse
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_reuse_wait
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_new
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_sbrk_less
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_free
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_less
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tcache_double_free
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_more
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_sbrk_more
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_malloc_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_memalign_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_free_dyn_thresholds
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_realloc_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_calloc_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt
oomkill
使用kprobes來跟蹤
oom_kill_process()
函式,來跟蹤OOM Killer事件的資訊,以及可以從
/proc/loadavg
獲取負載平均值,打印出平均負載等詳細資訊。平均負載資訊可以在OOM發生時提供整個系統狀態的一些上下文資訊,展示出系統整體是正在變忙還是處於穩定狀態。
staticvoidoom_kill_process(struct oom_control *oc, constchar *message)
# cat /proc/loadavg
0.05 0.10 0.13 1/875 23359
memleak
memleak可以用來跟蹤記憶體分配和釋放事件對應的呼叫棧資訊。隨著時間的推移,這個工具可以顯示長期不被釋放的記憶體。
在跟蹤使用者態行程時,memleak跟蹤的是使用者態記憶體分配函式:
malloc()
、
calloc()
和
free()
等。對內核態記憶體來說,使用的是k跟蹤點:
kmem:kfree [Tracepoint event]
kmem:kmalloc [Tracepoint event]
kmem:kmalloc_node [Tracepoint event]
kmem:kmem_cache_alloc [Tracepoint event]
kmem:kmem_cache_alloc_node [Tracepoint event]
kmem:kmem_cache_free [Tracepoint event]
kmem:mm_page_alloc [Tracepoint event]
kmem:mm_page_free [Tracepoint event]
percpu:percpu_alloc_percpu [Tracepoint event]
percpu:percpu_free_percpu [Tracepoint event]
使用工具模擬記憶體泄漏:
寫一個c程式:
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
longlong *fibonacci(longlong *n0, longlong *n1){
// 分配1024個長整數空間方便觀測記憶體的變化情況
longlong *v = (longlong *) calloc(1024, sizeof(longlong));
*v = *n0 + *n1;
return v;
}
void *child(void *arg){
longlong n0 = 0;
longlong n1 = 1;
longlong *v = NULL;
int n = 2;
for (n = 2; n > 0; n++) {
v = fibonacci(&n0, &n1);
n0 = n1;
n1 = *v;
printf("%dth => %lld\n", n, *v);
sleep(1);
}
}
intmain(void){
pthread_t tid;
pthread_create(&tid, NULL, child, NULL);
pthread_join(tid, NULL);
printf("main thread exit\n");
return0;
}
執行該檔
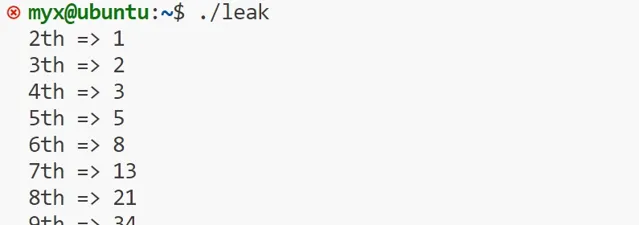
再開一個終端,使用命令vmstat 3
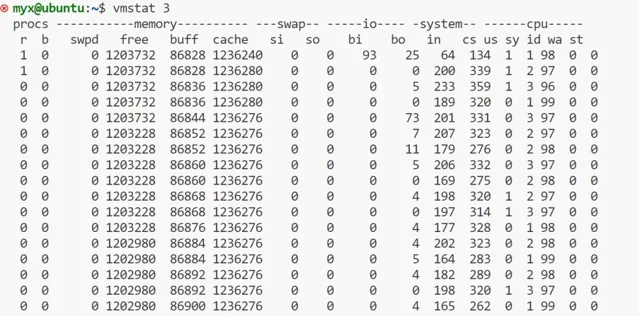
上面的 "free", "buff", "cache" 欄目分別以 KB 為單位顯示了空閑記憶體、儲存 I/O 緩沖區占用的記憶體,以及檔案系統緩存占用的記憶體數量。"si" 和 "so" 欄目分別展示了頁換入和頁換出操作的數量,如果系統中存在這些操作的話。
第一行輸出的是"自系統啟動以來"的統計資訊,這一行的大部份欄目是自從系統啟動以來的平均值。然而,"memory"欄顯示的仍然是系統記憶體的當前狀態。而第二行和之後的行顯示的都是一秒之內的統計資訊。
可以看出free(可用記憶體)上下浮動慢慢減少,而buff(磁盤緩存),cache(檔緩存)上下浮動基本保持不變。
再次使用命令執行上面C程式
在開啟第二個終端中使用命令:ps aux | grep app檢視行程id
使用命令: sudo /usr/sbin/memleak-bpfcc -p 6867 執行

從圖中可以看出來泄露位置:
fibonacci+0x23 [leak] child+0x5a [leak]
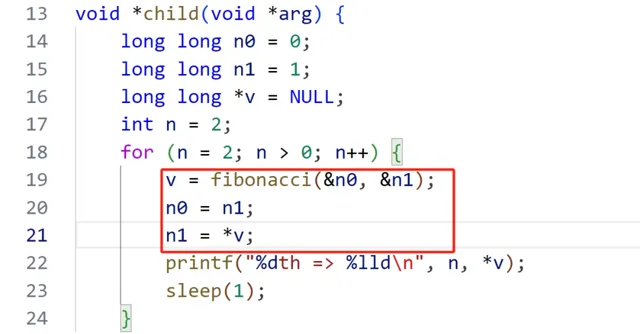
可以看出程式碼中的*v,沒有釋放,造成記憶體泄漏。
改後程式碼:
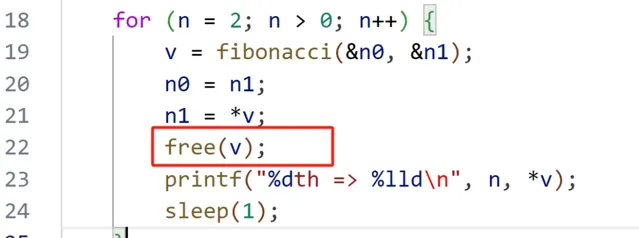
改進後,重復上面的操作,結果如下

單靠memleak無法判斷這些記憶體分配操作是真正的記憶體泄漏(即,分配的記憶體沒有任何參照,永遠不會被釋放),還是只是記憶體用量的正常增長,或者僅僅是真正的長期記憶體。為了區分這幾種型別,需要閱讀和理解這些程式碼路徑的真正意圖。
如果沒有
-p PID
命令列參數,那麽memleak跟蹤的是內核中的記憶體分配資訊:
mmapsnoop
使用
syscall:sys_enter_mmap
跟蹤點跟蹤全系統
mmap
系統呼叫並打印對映請求詳細資訊。
sys_enter_mmap
是一個用於跟蹤
mmap
系統呼叫的跟蹤點的名稱。
syscalls:sys_enter_mmap [Tracepoint event]
一個應用程式,特別是在其啟動和初始化期間,可以顯式地使用mmap() 系統呼叫來載入數據檔或建立各種段,在這個上下文中,我們聚焦於那些比較緩慢的套用增長,這種情況可能是由於分配器函式呼叫了mmap()而不是brk()造成的。而libc通常用mmap()分配較大的記憶體,可以使用munmap()將分配的記憶體返還給系統。
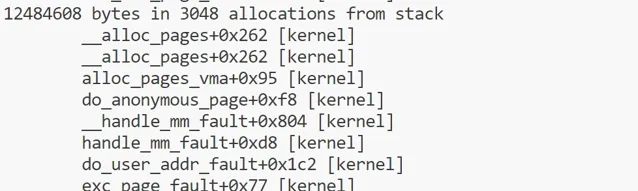
brkstack
一般來說,應用程式的數據存放於堆記憶體中,堆記憶體透過
brk
系統呼叫進行擴充套件。跟蹤
brk
呼叫,並且展示導致增長的使用者態呼叫棧資訊相對來說是很有用的分析資訊。同時還有一個
sbrk
變體呼叫。在 Linux 中,
sbrk
是以庫函式形式實作的,內部仍然使用
brk
系統呼叫。
brk
可以用
syscall:sys_enter_brk
跟蹤點來跟蹤,同時該跟蹤點對應的呼叫棧資訊,可以用
bpftrace
版本的單行程式等方式來獲取。
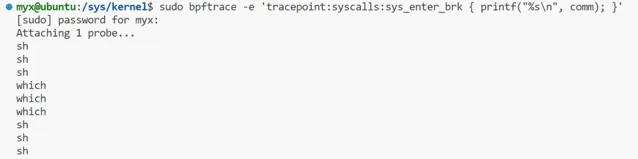
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_brk { printf("%s\n", comm); }'
上面命令可以跟蹤brk系統呼叫。
shmsnoop
shmsnoop
跟蹤 System V 的共享記憶體系統呼叫:shmget、shmat、shmdt以及shmctl。可以用來偵錯共享記憶體的使用情況和資訊。

這個輸出顯示了一個Renderer行程透過
shmget
分配了共享記憶體,然後顯示了該 Renderer 行程執行了幾種不同的共享記憶體操作,以及對應的參數資訊。
shmget
呼叫的返回結果是
0x28
,這個識別元接下來被 Renderer 和 Xorg 行程同時使用;換句話說,它們在共享記憶體中。
共享記憶體
共享記憶體就是允許兩個不相關的行程存取同一個邏輯記憶體。共享記憶體是在兩個正在執行的行程之間共享和傳遞數據的一種非常有效的方式。
不同行程之間共享的記憶體通常安排為同一段實體記憶體。行程可以將同一段共享記憶體連線到它們自己的地址空間中,所有行程都可以存取共享記憶體中的地址,就好像它們是由用C語言函式malloc()分配的記憶體一樣。而如果某個行程向共享記憶體寫入數據,所做的改動將立即影響到可以存取同一段共享記憶體的任何其他行程。
共享記憶體並未提供同步機制,也就是說,在第一個行程結束對共享記憶體的寫操作之前,並無自動機制可以阻止第二個行程開始對它進行讀取。所以通常需要用其他的機制來同步對共享記憶體的存取,例如號誌。
shmget()函式
得到一個共享記憶體識別元或建立一個共享記憶體物件。
asmlinkage longsys_shmget(key_t key, size_t size, int flag);
SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg)
{
return ksys_shmget(key, size, shmflg);
}
longksys_shmget(key_t key, size_t size, int shmflg)
{
structipc_namespace *ns;
staticconststructipc_opsshm_ops = {
.getnew = newseg,
.associate = security_shm_associate,
.more_checks = shm_more_checks,
};
structipc_paramsshm_params;
ns = current->nsproxy->ipc_ns;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;
return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}
成功:共享記憶體段識別元 出錯:-1
函式參數:
Key:共享記憶體的鍵值,多個行程可以透過它,來存取同一個共享記憶體;其中特殊的值IPC_PRIVATE,用於建立當前行程的私有共享記憶體, 多用於父子行程間。
size:共享記憶體區大小 。
Shmflg:同 open 函式的許可權位,也可以用八進制表示法
返回值:
shmat( )函式
連線共享記憶體識別元為shmid的共享記憶體,連線成功後把共享記憶體區物件對映到呼叫行程的地址空間,隨後可像本地空間一樣存取。
asmlinkage longsys_shmat(int shmid, char __user *shmaddr, int shmflg);
SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg)
{
unsignedlong ret;
long err;
err = do_shmat(shmid, shmaddr, shmflg, &ret, SHMLBA);
if (err)
return err;
force_successful_syscall_return();
return (long)ret;
}
成功:被對映的段地址 出錯:-1
函式原型
shmid:要對映的共享記憶體區識別元
shmaddr:將共享記憶體對映到指定位置
Shmflg:SHM_RDONLY:共享記憶體唯讀,預設0:共享記憶體可讀寫
返回值:
shmdt()函式
與shmat函式相反,是用來斷開與共享記憶體附加點的地址,禁止本行程存取此片共享記憶體。
本函式呼叫並不刪除所指定的共享記憶體區,而只是將先前用shmat函式連線(attach)好的共享記憶體脫離(detach)目前的行程。
asmlinkage longsys_shmdt(char __user *shmaddr);
SYSCALL_DEFINE1(shmdt, char __user *, shmaddr)
{
return ksys_shmdt(shmaddr);
}
longksys_shmdt(char __user *shmaddr)
{
// 獲取當前行程的記憶體管理結構
structmm_struct *mm = current->mm;
// 定義虛擬記憶體區域結構體指標
structvm_area_struct *vma;
// 將共享記憶體地址轉換為無符號長整型
unsignedlong addr = (unsignedlong)shmaddr;
// 初始化返回值,預設為無效參數錯誤
int retval = -EINVAL;
#ifdef CONFIG_MMU
// 定義大小變量和檔指標
loff_t size = 0;
structfile *file;
structvm_area_struct *next;
#endif
// 檢查共享記憶體地址是否有效
if (addr & ~PAGE_MASK)
return retval;
// 嘗試獲取記憶體對映寫鎖,可被訊號中斷
if (mmap_write_lock_killable(mm))
return -EINTR;
// 尋找給定地址的虛擬記憶體區域
vma = find_vma(mm, addr);
#ifdef CONFIG_MMU
while (vma) {
next = vma->vm_next;
// 檢查地址是否匹配,並且 vma 與 shm 相關
if ((vma->vm_ops == &shm_vm_ops) &&
(vma->vm_start - addr)/PAGE_SIZE == vma->vm_pgoff) {
// 記錄 shm 段的檔和大小
file = vma->vm_file;
size = i_size_read(file_inode(vma->vm_file));
// 取消對映 shm 段
do_munmap(mm, vma->vm_start, vma->vm_end - vma->vm_start, NULL);
// 設定返回值為成功
retval = 0;
vma = next;
break;
}
vma = next;
}
// 遍歷所有可能的 vma
size = PAGE_ALIGN(size);
while (vma && (loff_t)(vma->vm_end - addr) <= size) {
next = vma->vm_next;
// 檢查地址是否匹配,並且 vma 與 shm 相關
if ((vma->vm_ops == &shm_vm_ops) &&
((vma->vm_start - addr)/PAGE_SIZE == vma->vm_pgoff) &&
(vma->vm_file == file))
// 取消對映 shm 段
do_munmap(mm, vma->vm_start, vma->vm_end - vma->vm_start, NULL);
vma = next;
}
#else/* CONFIG_MMU */
// 在 NOMMU 條件下,必須給出要銷毀的確切地址
if (vma && vma->vm_start == addr && vma->vm_ops == &shm_vm_ops) {
// 取消對映 shm 段
do_munmap(mm, vma->vm_start, vma->vm_end - vma->vm_start, NULL);
// 設定返回值為成功
retval = 0;
}
#endif
// 解鎖記憶體對映
mmap_write_unlock(mm);
return retval;
}
函式原型
shmaddr:連線的共享記憶體的起始地址
shmctl函式
完成對共享記憶體的控制
asmlinkage longsys_shmctl(int shmid, int cmd, struct shmid_ds __user *buf);
SYSCALL_DEFINE3(shmctl, int, shmid, int, cmd, struct shmid_ds __user *, buf)
{
return ksys_shmctl(shmid, cmd, buf, IPC_64);
}
staticlongksys_shmctl(int shmid, int cmd, struct shmid_ds __user *buf, int version)
{
int err;
structipc_namespace *ns;
structshmid64_dssem64;
if (cmd < 0 || shmid < 0)
return -EINVAL;
ns = current->nsproxy->ipc_ns;
switch (cmd) {
case IPC_INFO: {
structshminfo64shminfo;
err = shmctl_ipc_info(ns, &shminfo);
if (err < 0)
return err;
if (copy_shminfo_to_user(buf, &shminfo, version))
err = -EFAULT;
return err;
}
case SHM_INFO: {
structshm_infoshm_info;
err = shmctl_shm_info(ns, &shm_info);
if (err < 0)
return err;
if (copy_to_user(buf, &shm_info, sizeof(shm_info)))
err = -EFAULT;
return err;
}
case SHM_STAT:
case SHM_STAT_ANY:
case IPC_STAT: {
err = shmctl_stat(ns, shmid, cmd, &sem64);
if (err < 0)
return err;
if (copy_shmid_to_user(buf, &sem64, version))
err = -EFAULT;
return err;
}
case IPC_SET:
if (copy_shmid_from_user(&sem64, buf, version))
return -EFAULT;
fallthrough;
case IPC_RMID:
return shmctl_down(ns, shmid, cmd, &sem64);
case SHM_LOCK:
case SHM_UNLOCK:
return shmctl_do_lock(ns, shmid, cmd);
default:
return -EINVAL;
}
}
函式原型
shmid:共享記憶體識別元
cmd:IPC_STAT:得到共享記憶體的狀態,把共享記憶體的shmid_ds結構復制到buf中;IPC_SET:改變共享記憶體的狀態,把buf所指的shmid_ds結構中的uid、gid、mode復制到共享記憶體的shmid_ds結構內;IPC_RMID:刪除這片共享記憶體
buf:共享記憶體管理結構體。
faults
跟蹤缺頁錯誤和對應的呼叫棧資訊,可以為記憶體使用量分析提供一個新的視角。缺頁錯誤會直接導致 RSS 的增長,所以這裏截取的呼叫棧資訊可以用來解釋行程記憶體使用量的增長。正如 brk() 一樣,可以透過單行程式來直接跟蹤這個事件並進行分析。
跟蹤page_fault_user和page_fault_kernel來對使用者態和內核態的缺頁錯誤對應的頻率統計資訊進行分析。
exceptions:page_fault_user [Tracepoint event]
exceptions:page_fault_kernel [Tracepoint event]
vmscan
使用vmscan跟蹤點觀察頁面換出守護行程(kswapd)的操作。這個行程在系統記憶體壓力上升時負責釋放記憶體以便重用。值得註意的是,盡管內核函式的名稱仍然使用scanner,但為了提高效率,內核已經采用連結串列方式來管理活躍記憶體和不活躍記憶體。
vmscan:mm_shrink_slab_end [Tracepoint event]
vmscan:mm_shrink_slab_start [Tracepoint event]
vmscan:mm_vmscan_direct_reclaim_begin [Tracepoint event]
vmscan:mm_vmscan_direct_reclaim_end [Tracepoint event]
vmscan:mm_vmscan_memcg_reclaim_begin [Tracepoint event]
vmscan:mm_vmscan_memcg_reclaim_end [Tracepoint event]
vmscan:mm_vmscan_wakeup_kswapd [Tracepoint event]
vmscan:mm_vmscan_writepage [Tracepoint event]
vmscan:mm_shrink_slab_end,vmscan:mm_shrink_slab_start
使用這兩個跟蹤點計算收縮slab所花的全部時間,以毫秒為單位。這是從各種內核緩存中回收記憶體。
vmscan:mm_vmscan_direct_reclaim_begin,vmscan:mm_vmscan_direct_reclaim_end
使用這兩個跟蹤點計算直接接回收所花的時間,以毫秒為單位。這是前台回收過程,在此期間記憶體被換入磁盤中,並且記憶體分配處於阻塞狀態。
vmscan:mm_vmscan_memcg_reclaim_begin,vmscan:mm_vmscan_memcg_reclaim_end
記憶體cgroup回收所花的時間,以毫秒為單位。如果使用了記憶體cgroups,此列顯示當cgroup超出記憶體限制,導致該cgroup進行記憶體回收的時間。
vmscan:mm_vmscan_wakeup_kswapd
kswapd 喚醒的次數。
vmscan:mm_vmscan_writepage
kswapd寫入頁的數量。
drsnoop
drsnoop使用mm_vmscan_direct_reclaim_begin 和 mm_vmscan_direct_reclaim_end 跟蹤點,來 跟蹤記憶體釋放過程中的直接回收部份 。它能夠顯示受到影響的行程以及對應的延遲,即直接回收所需的時間。可以用來定量分析記憶體受限的系統中對應用程式的效能影響。
直接記憶體回收
在直接記憶體回收過程中,有可能會造成當前需要分配記憶體的行程被加入一個等待佇列,當整個node的空閑頁數量滿足要求時,由kswapd喚醒它重新獲取記憶體。這個等待佇列頭就是node結點描述符pgdat中的pfmemalloc_wait。如果當前行程加入到了pgdat->pfmemalloc_wait這個等待佇列中,那麽行程就不會進行直接記憶體回收,而是由kswapd喚醒後直接進行記憶體分配。
直接記憶體回收執行路徑是:
__alloc_pages_slowpath()
->
__alloc_pages_direct_reclaim()
->
__perform_reclaim()
->
try_to_free_pages()
->
do_try_to_free_pages()
->
shrink_zones()
->
shrink_zone()
在
__alloc_pages_slowpath()
中可能喚醒了所有node的kswapd內核執行緒,也可能沒有喚醒,每個node的kswapd是否在
__alloc_pages_slowpath()
中被喚醒有兩個條件:
而在kswapd中會對node中每一個不平衡的zone進行記憶體回收,直到所有zone都滿足 zone分配頁框後剩余的頁框數量 > 此zone的high閥值 + 此zone保留的頁框數量。 kswapd就會停止記憶體回收,然後喚醒在等待佇列的行程。
之後行程由於記憶體不足,對zonelist進行直接回收時,會呼叫到try_to_free_pages(),在這個函式內,決定了行程是否加入到node結點的pgdat->pfmemalloc_wait這個等待佇列中,如下:
unsignedlongtry_to_free_pages(struct zonelist *zonelist, int order,
gfp_t gfp_mask, nodemask_t *nodemask)
{
unsignedlong nr_reclaimed;
structscan_controlsc = {
/* 打算回收32個頁框 */
.nr_to_reclaim = SWAP_CLUSTER_MAX,
.gfp_mask = current_gfp_context(gfp_mask),
.reclaim_idx = gfp_zone(gfp_mask),
/* 本次記憶體分配的order值 */
.order = order,
/* 允許進行回收的node掩碼 */
.nodemask = nodemask,
/* 優先級為預設的12 */
.priority = DEF_PRIORITY,
/* 與/proc/sys/vm/laptop_mode檔有關
* laptop_mode為0,則允許進行回寫操作,即使允許回寫,直接記憶體回收也不能對臟檔頁進行回寫
* 不過允許回寫時,可以對非檔頁進行回寫
*/
.may_writepage = !laptop_mode,
/* 允許進行unmap操作 */
.may_unmap = 1,
/* 允許進行非檔頁的操作 */
.may_swap = 1,
};
BUILD_BUG_ON(MAX_ORDER > S8_MAX);
BUILD_BUG_ON(DEF_PRIORITY > S8_MAX);
BUILD_BUG_ON(MAX_NR_ZONES > S8_MAX);
/* 當zonelist中獲取到的第一個node平衡,則返回,如果獲取到的第一個node不平衡,則將當前行程加入到pgdat->pfmemalloc_wait這個等待佇列中
* 這個等待佇列會在kswapd進行記憶體回收時,如果讓node平衡了,則會喚醒這個等待佇列中的行程
* 判斷node平衡的標準:
* 此node的ZONE_DMA和ZONE_NORMAL的總共空閑頁框數量 是否大於 此node的ZONE_DMA和ZONE_NORMAL的平均min閥值數量,大於則說明node平衡
* 加入pgdat->pfmemalloc_wait的情況
* 1.如果分配標誌禁止了檔案系統操作,則將要進行記憶體回收的行程設定為TASK_INTERRUPTIBLE狀態,然後加入到node的pgdat->pfmemalloc_wait,並且會設定超時時間為1s
* 2.如果分配標誌沒有禁止了檔案系統操作,則將要進行記憶體回收的行程加入到node的pgdat->pfmemalloc_wait,並設定為TASK_KILLABLE狀態,表示允許 TASK_UNINTERRUPTIBLE 響應致命訊號的狀態
* 返回真,表示此行程加入過pgdat->pfmemalloc_wait等待佇列,並且已經被喚醒
* 返回假,表示此行程沒有加入過pgdat->pfmemalloc_wait等待佇列
*/
if (throttle_direct_reclaim(sc.gfp_mask, zonelist, nodemask))
return1;
set_task_reclaim_state(current, &sc.reclaim_state);
trace_mm_vmscan_direct_reclaim_begin(order, sc.gfp_mask);
/* 進行記憶體回收,有三種情況到這裏
* 1.當前行程為內核執行緒
* 2.最優node是平衡的,當前行程沒有加入到pgdat->pfmemalloc_wait中
* 3.當前行程接收到了kill訊號
*/
nr_reclaimed = do_try_to_free_pages(zonelist, &sc);
trace_mm_vmscan_direct_reclaim_end(nr_reclaimed);
set_task_reclaim_state(current, NULL);
return nr_reclaimed;
}
主要透過throttle_direct_reclaim()函式判斷是否加入到pgdat->pfmemalloc_wait等待佇列中,主要看此函式:
staticboolthrottle_direct_reclaim(gfp_t gfp_mask, struct zonelist *zonelist,
nodemask_t *nodemask)
{
structzoneref *z;
structzone *zone;
pg_data_t *pgdat = NULL;
/* 如果標記了PF_KTHREAD,表示此行程是一個內核執行緒,則不會往下執行 */
if (current->flags & PF_KTHREAD)
goto out;
/* 此行程已經接收到了kill訊號,準備要被殺掉了 */
if (fatal_signal_pending(current))
goto out;
/* 遍歷zonelist,但是裏面只會在獲取到第一個pgdat時就跳出 */
for_each_zone_zonelist_nodemask(zone, z, zonelist,
gfp_zone(gfp_mask), nodemask) {
/* 只遍歷ZONE_NORMAL和ZONE_DMA區 */
if (zone_idx(zone) > ZONE_NORMAL)
continue;
/* 獲取zone對應的node */
pgdat = zone->zone_pgdat;
/* 判斷node是否平衡,如果平衡,則返回真
* 如果不平衡,如果此node的kswapd沒有被喚醒,則喚醒,並且這裏喚醒kswapd只會對ZONE_NORMAL以下的zone進行記憶體回收
* node是否平衡的判斷標準是:
* 此node的ZONE_DMA和ZONE_NORMAL的總共空閑頁框數量 是否大於 此node的ZONE_DMA和ZONE_NORMAL的平均min閥值數量,大於則說明node平衡
*/
if (allow_direct_reclaim(pgdat))
goto out;
break;
}
if (!pgdat)
goto out;
count_vm_event(PGSCAN_DIRECT_THROTTLE);
if (!(gfp_mask & __GFP_FS))
/* 如果分配標誌禁止了檔案系統操作,則將要進行記憶體回收的行程設定為TASK_INTERRUPTIBLE狀態,然後加入到node的pgdat->pfmemalloc_wait,並且會設定超時時間為1s
* 1.allow_direct_reclaim(pgdat)為真時被喚醒,而1s沒超時,返回剩余timeout(jiffies)
* 2.睡眠超過1s時會喚醒,而allow_direct_reclaim(pgdat)此時為真,返回1
* 3.睡眠超過1s時會喚醒,而allow_direct_reclaim(pgdat)此時為假,返回0
* 4.接收到訊號被喚醒,返回-ERESTARTSYS
*/
wait_event_interruptible_timeout(pgdat->pfmemalloc_wait,
allow_direct_reclaim(pgdat), HZ);
else
/* 如果分配標誌沒有禁止了檔案系統操作,則將要進行記憶體回收的行程加入到node的pgdat->pfmemalloc_wait,並設定為TASK_KILLABLE狀態,表示允許 TASK_UNINTERRUPTIBLE 響應致命訊號的狀態
* 這些行程在兩種情況下被喚醒
* 1.allow_direct_reclaim(pgdat)為真時
* 2.接收到致命訊號時
*/
wait_event_killable(zone->zone_pgdat->pfmemalloc_wait,
allow_direct_reclaim(pgdat));
/* 如果加入到了pgdat->pfmemalloc_wait後被喚醒,就會執行到這 */
/* 喚醒後再次檢查當前行程是否接受到了kill訊號,準備結束 */
if (fatal_signal_pending(current))
returntrue;
out:
returnfalse;
}
分配標誌中沒有__GFP_NO_KSWAPD,只有在透明大頁的分配過程中會有這個標誌。
node中有至少一個zone的空閑頁框沒有達到 空閑頁框數量 >= high閥值 + 1 << order + 保留記憶體,或者有至少一個zone需要進行記憶體壓縮,這兩種情況node的kswapd都會被喚醒。
swapin
使用kprobe跟蹤swap_readpage()內核函式,這會在觸發換頁所在的行程上下文中進行,可以跟蹤觸發換頁操作的行程的資訊。展示了哪個行程正在從換頁裝置中換入頁,前提是系統中有正在使用的換頁裝置。
換頁操作在應用程式使用那些已經被換出到換頁裝置上的記憶體時觸發。這是⼀個很重要的由於換頁導致的套用效能影響指標。其他的換頁相關指標,例如掃描和換出操作, 並不直接影響應用程式的效能。
externintswap_readpage(struct page *page, bool do_poll);
hfaults
使用kprobe跟蹤hugetlb_fault()函式,可以從該函式的參數中抓取很多的詳細資訊,包括mm_struct結構體和vm_area_struct結構體。可以透過vm_area_struct結構體來抓取檔名資訊。
透過跟蹤巨頁相關的缺頁錯誤資訊,按行程展示詳細資訊,同時可以用來確保巨頁確實被啟用了。
vm_fault_thugetlb_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsignedlong address, unsignedint flags);











