我和很多學python的同學聊過,至少有30%以上的人學Python是為了網路爬蟲,也就是采集網站的數據,不得不說這確實是一個剛性需求。
但一個殘酷的事實是,即使一部份人學了Python,掌握了requests、urllib、bs4等爬蟲技術,也無法有效地獲取標的網站的數據。
因為無論是淘寶、京東、亞馬遜、Ebay這樣的購物網站,還是小紅書、領英、tiktok這樣的社媒平台,都會有各種反爬機制、動態頁面來阻止異常流量。
所以你得了解逆向、解鎖、IP代理等各種知識,才能真正的采集到想要的數據,這次我專門錄了一個 視訊教程 ,告訴你如何簡潔、有效地搞定反爬和動態頁面。
如下視訊教程:
視訊裏會講到我常用的一個爬蟲平台-亮數據,它提供數據采集瀏覽器、網路解鎖器、數據采集托管IDE三種方式,能透過簡單的幾十行Python程式碼實作復雜網路數據的采集,對於反爬、驗證碼、動態網頁等進行自動化處理,完全不需要你操心。

比如說透過亮數據解鎖器抓取亞馬遜網站智慧型手機商品名稱和價格資訊,可以實作批次無憂抓取。
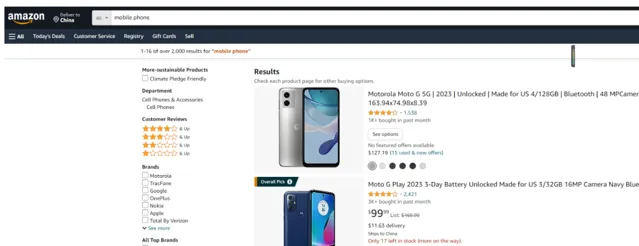
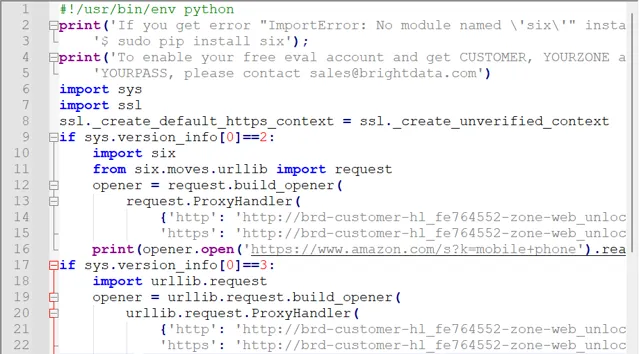
輸出:
再比如使用亮數據瀏覽器抓取紐約時報新聞標題和釋出時間數據
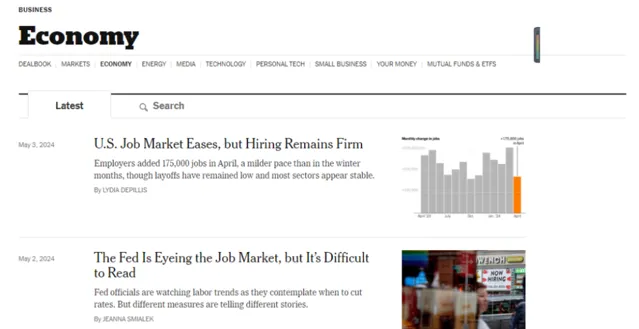
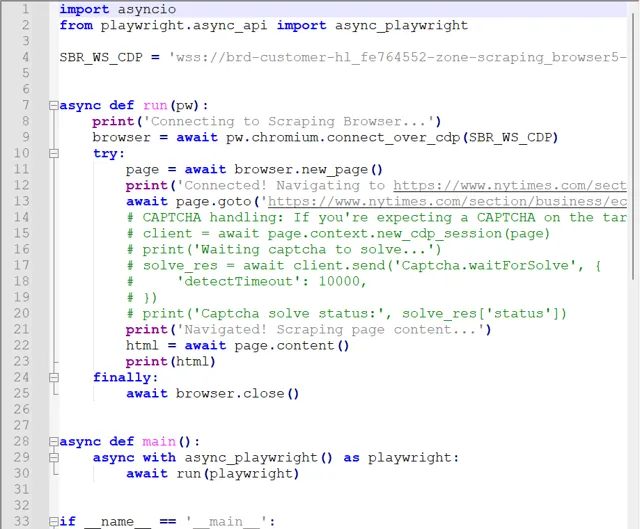
輸出:

以上只是簡單的範例,更復雜的數據抓取也都可以實作。
官網地址(點選原文連結也可檢視):
https://get.brightdata.com/weijun
有數據抓取需求的可以試試,非常簡單,能節省大量時間和精力!!!











