
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / 1v1 提問 / Java 學習路線 / 學習打卡 / 每月贈書 / 社群討論
新計畫: 【從零手擼:仿小紅書(微服務架構)】 正在持續爆肝中,基於 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., ;
【從零手擼:前後端分離部落格計畫(全棧開發)】 2期已完結,演示連結: http://116.62.199.48/ ;
截止目前, 累計輸出 48w+ 字,講解圖 2090+ 張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將 Java 領域典型的計畫都整一波,如秒殺系統, 線上商城, IM 即時通訊,Spring Cloud Alibaba 等等,
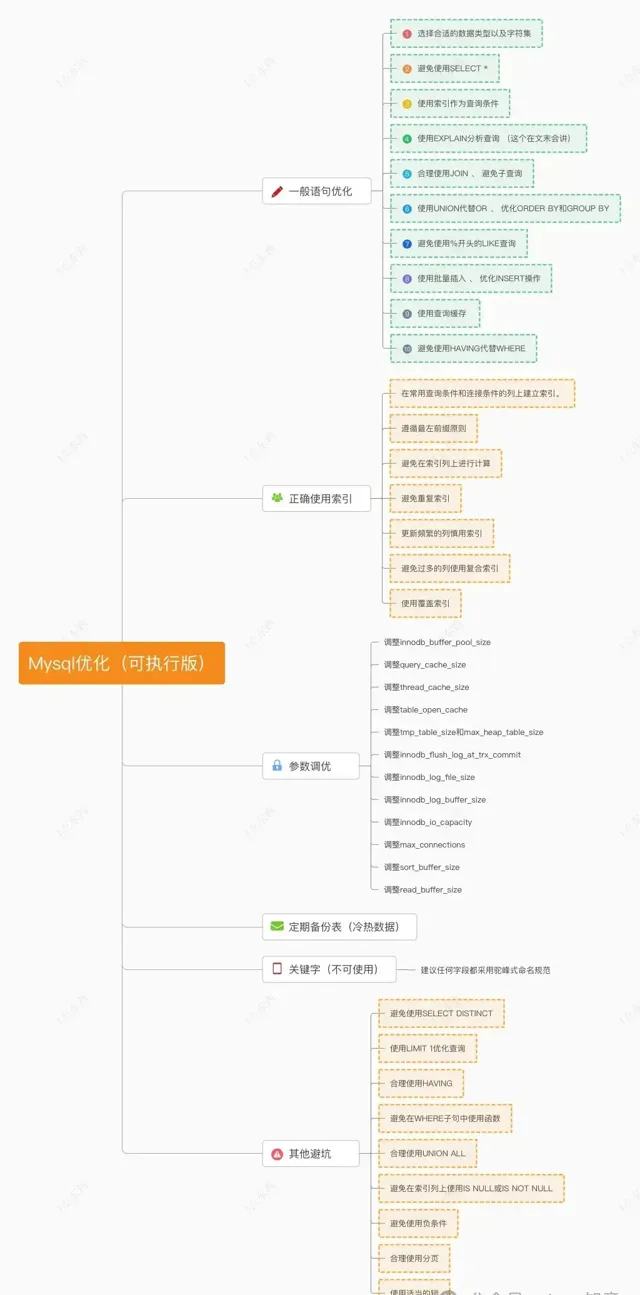
上圖給大家匯總了一份清單,是目前我能想到一些最佳化點以及這麽多年的踩坑總結。雖然大家對此並不陌生,但肯定有你平常想不到的,我盡可能的給大家整理出了一份較全的總結並給大家一一舉例詳解,希望做到溫故而知新。
一般語句最佳化
先從一般的語句最佳化開始,其實對於很多規範大家並不陌生,可就是在用的時候,無法遵從,希望今天大家再過一遍,可以養成一種良好的資料庫編碼習慣。
選擇合適的數據型別及字元集
使用合適的數據型別可以減少儲存空間和提高查詢速度。這個可不能小看,數據量到達一個量級,這個就能看出明顯差異。
例子:對於布爾值使用 TINYINT(1) 而不是 CHAR(1) 比如你有一個欄位是表示業務狀態或者是型別。
CREATE TABLE users (
is_active TINYINT(1)
);
對於僅儲存英文的表,使用 latin1 而不是 utf8mb4。
CREATE TABLE messages (
content VARCHAR(255) CHARACTER SET latin1
);
避免使用SELECT *
僅選擇必要的列,減少數據傳輸量。
例子:避免
SELECT *
,改用具體列名。
SELECT id, name, email FROM users;
合理使用JOIN、避免子查詢
避免過多的 JOIN 操作,盡量減少數據集的大小。
例子:最佳化連線條件,確保連線列上有索引。
SELECT * FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.status = 'active';
盡量使用 JOIN 或者 EXISTS 代替子查詢。
例子:避免使用子查詢,改用 JOIN。
SELECT u.name, o.amount
FROM users u
JOIN orders o ON u.id = o.user_id;
使用UNION代替OR、最佳化ORDER BY和GROUP BY
確保
ORDER BY
和
GROUP BY
的列上有索引。
例子:在排序和分組列上添加索引。
CREATE INDEX idx_order_date ON orders (order_date);
SELECT * FROM orders ORDER BY order_date;
在業務允許的情況下,使用 UNION 代替 OR 條件。
例子:用兩個查詢的 UNION 代替一個帶 OR 的查詢。
SELECT id, name FROM users WHERE status = 'active'
UNION
SELECT id, name FROM users WHERE status = 'pending';
避免使用%開頭的LIKE查詢
避免使用
%
開頭的
LIKE
查詢,因為不能使用索引。
例子:使用全文本搜尋代替
LIKE '%keyword%'
。 也就是讓
%
在最後面
SELECT * FROM products WHERE description LIKE 'keyword%';
這個尤其重要,相信各位在各大平台網站上。很多搜尋只有輸入前面的字才能有結果,你輸入中間的字,會查詢不到,其實就是這個原理。
使用批次插入、最佳化INSERT操作
使用批次插入減少插入操作的開銷。
INSERT INTO users (name, email) VALUES ('Alice', '[email protected]'),
('Bob', '[email protected]');
在批次插入時,關閉唯一性檢查和索引更新,插入完成後再開啟(此種情況大家可根據業務來,比如當查詢很頻繁的時候,這樣操作會影響查詢效率)。
SET autocommit=0;
SET unique_checks=0;
SET foreign_key_checks=0;
-- 批次插入操作
SET unique_checks=1;
SET foreign_key_checks=1;
COMMIT;
使用查詢緩存
使用查詢緩存,減少重復查詢的開銷。
SET GLOBAL query_cache_size = 1048576;
SET GLOBAL query_cache_type = ON;
避免使用HAVING代替WHERE
在可能的情況下,使用 WHERE 代替 HAVING 進行過濾。
例子:避免使用 HAVING 過濾。
SELECT user_id, COUNT(*) FROM orders
WHERE order_date > '2020-01-01'
GROUP BY user_id
HAVING COUNT(*) > 1;
配置參數調優
該部份主要針對Mysql的配置做一些操作,這塊還是相當重要的,雖然是運維領域,但熟悉Mysql的配置是我們研發的不可不會的領域。
調整innodb_buffer_pool_size
innodb_buffer_pool_size
是 InnoDB 儲存引擎最重要的配置參數之一,用於指定 InnoDB 緩沖池的大小。緩沖池用於緩存數據頁、索引頁和 InnoDB 表的其它資訊。合理設定這個參數對資料庫效能有很大影響。
增大 InnoDB 緩沖池大小,提高緩存命中率。
SET GLOBAL innodb_buffer_pool_size = 2G;
但是這裏要註意 該值並不是越大越好。
innodb_buffer_pool_size
應該設定要盡可能大,但要確保為作業系統和其他應用程式留出足夠的記憶體。
一般建議在資料庫專用伺服器上設定為實體記憶體的 60% 到 80%。透過監控資料庫效能和記憶體使用情況,可以進一步調整這個參數以最佳化資料庫效能。
調整query_cache_size
query_cache_size
是用於指定查詢緩存的大小。查詢緩存可以緩存 SELECT 查詢的結果,避免重復執行相同的查詢,從而提高效能。
然而,在 MySQL 8.0 及更高版本中,查詢緩存已經被完全移除。如果你使用的是 MySQL 8.0 及以上版本,可以忽略
query_cache_size
參數。
調整thread_cache_size
增大執行緒緩存大小,減少執行緒建立開銷。
SET GLOBAL thread_cache_size = 100;
調整table_open_cache
增大表緩存大小,減少表開啟的開銷。
SET GLOBAL table_open_cache = 4000;
調整tmp_table_size和max_heap_table_size
增大臨時表和堆表的最大大小,減少磁盤 I/O。
SET GLOBAL tmp_table_size = 64M;
SET GLOBAL max_heap_table_size = 64M;
調整innodb_flush_log_at_trx_commit
根據需求調整日誌重新整理策略,權衡效能和數據安全性。
SET GLOBAL innodb_flush_log_at_trx_commit = 2;
調整innodb_log_file_size
增大日誌檔大小,減少日誌檔切換的開銷。
SET GLOBAL innodb_log_file_size = 256M;
調整innodb_log_buffer_size
增大日誌緩沖區大小,提高寫入效能。
SET GLOBAL innodb_log_buffer_size = 16M;
調整innodb_io_capacity
根據磁盤 I/O 效能調整 InnoDB I/O 容量。
SET GLOBAL innodb_io_capacity = 2000;
調整max_connections
增大最大連線數,支持更多並行連線。
SET GLOBAL max_connections = 500;
調整sort_buffer_size
增大排序緩沖區大小,提高排序操作的效能。
SET GLOBAL sort_buffer_size = 4M;
調整read_buffer_size
增大讀緩沖區大小,提高順序掃描效能。
SET GLOBAL read_buffer_size = 2M;
正確使用索引
這塊是最重要的,因為假如使用不當,那麽建立索引不但沒有效果,反而還會成為負擔。
在常用查詢條件和連線條件的列上建立索引
這塊很清楚,反正只要發現查詢較慢,優先檢查where條件後面,有沒有被建立索引。
遵循最左字首原則
這個是針對復合索引時的要求,遵循最左字首原則。
例子:對於索引 (a, b, c),可以用於 (a),(a, b),(a, b, c) 的查詢。
CREATE INDEX idx_abc ON table_name (a, b, c);
SELECT * FROM table_name WHERE a = 1 AND b = 2;
避免在索引列上進行計算
例子:避免
WHERE YEAR(date) = 2020
,改用範圍查詢。
SELECT * FROM orders WHERE date BETWEEN '2024-06-01' AND '2024-06-30';
避免重復索引
檢查並刪除重復的索引,減少維護開銷。了解mysql底層的都知道,建立索引,就會增加一個頁,重復索引無疑是給增加負擔。
更新頻繁的列慎用索引
對於更新頻繁的列,索引會增加寫操作的開銷,需要慎重使用。
CREATE INDEX idx_update_col ON table_name (update_col);
-- 如果 update_col 更新頻繁,需慎用
避免過多的列使用復合索引
復合索引的列數不要太多,列數過多會增加索引的維護開銷,並且可能導致索引檔過大。對此可以拆分為較少復合索引和單個索引
CREATE INDEX idx_columns ON table_name (col1, col2, col3, col4, col5);
-- 列數太多
使用覆蓋索引
這個什麽意思呢,如果查詢的所有列都在索引中,那麽可以避免回表,提高效能。
CREATE INDEX idx_covering ON orders (order_id, order_date, customer_id);
-- 查詢只涉及索引中的列
SELECT order_id, order_date, customer_id FROM orders WHERE customer_id = 123;
其他避坑
避免使用SELECT DISTINCT
在沒有必要的情況下避免使用
SELECT DISTINCT
,因為它會導致額外的排序操作,增加查詢的開銷。
-- 如果可以確定結果集不會有重復值,避免使用 DISTINCT
SELECT DISTINCT name FROM users WHERE status = 'active';
使用LIMIT 1最佳化查詢
在只需要一條結果的查詢中使用 LIMIT 1 可以提高效能。
SELECT * FROM users WHERE email = '[email protected]' LIMIT 1;
合理使用HAVING
在可能的情況下,使用 WHERE 代替 HAVING 進行過濾,因為 HAVING 是在聚合之後進行過濾,效能較差。
SELECT user_id, COUNT(*) FROM orders
WHERE order_date > '2020-01-01'
GROUP BY user_id
HAVING COUNT(*) > 1;
-- 改為使用 WHERE
SELECT user_id, COUNT(*) AS order_count FROM orders
WHERE order_date > '2020-01-01'
GROUP BY user_id
WHERE order_count > 1;
避免在WHERE子句中使用函式
避免在 WHERE 子句中使用函式,因為會導致索引失效(這個剛才講索引的時候提到了)。
-- 避免
SELECT * FROM users WHERE YEAR(created_at) = 2023;
-- 改為
SELECT * FROM users WHERE created_at BETWEEN '2024-06-01' AND '2024-06-01';
合理使用UNION ALL
在可能的情況下,使用
UNION ALL
代替
UNION
,因為
UNION
會去重,增加開銷。
SELECT name FROM employees WHERE department = 'Sales'
UNION ALL
SELECT name FROM contractors WHERE department = 'Sales';
避免在索引列上使用IS NULL或IS NOT NULL
盡量避免在索引列上使用
IS NULL
或
IS NOT NULL
,因為有些儲存引擎對這類查詢不使用索引。
-- 避免
SELECT * FROM users WHERE email IS NULL;
-- 如果業務允許,考慮使用預設值替代 NULL
SELECT * FROM users WHERE email = '';
避免使用負條件
避免使用 NOT IN、!=、<> 等負條件,因為這些條件不能有效使用索引。
-- 避免
SELECT * FROM orders WHERE status != 'completed';
-- 改為使用正條件
SELECT * FROM orders WHERE status IN ('pending', 'processing');
合理使用分頁
在大數據集分頁時,避免使用
OFFSET
大量偏移,而是使用更高效的方式,如基於唯一鍵的範圍查詢。
-- 避免
SELECT * FROM orders ORDER BY order_id LIMIT 1000000, 10;
-- 改為使用範圍查詢
SELECT * FROM orders WHERE order_id > (SELECT order_id FROM orders ORDER BY order_id LIMIT 999999, 1) LIMIT 10;
使用適當的鎖
在需要釘選的情況下,合理選擇鎖的型別(行鎖、表鎖)以避免效能問題和死結 (死結、 行鎖、表鎖 等問題會開專欄討論,今天不討論)。
-- 行級鎖
SELECT * FROM orders WHERE order_id = 1 FOR UPDATE;
-- 表級鎖
LOCK TABLES orders WRITE;
冷熱數據備份
這個什麽意思呢,簡單來講,什麽是目前業務經常需要的數據,比如5、8年前的數據 是否業務不再進行存取,或者對數據按照(時間、 某一業務)維度拆分,把數據一拆為多,減輕當表的壓力。總之一個原則,存取5千萬的數據量要比存取5百萬的數據速度要慢很多。那就拆。
「
註意:這個和分庫分表還不是一個概念,這個是把冷數據給清理出去,把最新的熱數據放進來。
詳解Explain
最後說一下這個,應該有有一部份人,對這個還不是很熟悉。
當一條查詢語句在經過MySQL查詢最佳化器的各種基於成本和規則的最佳化會後生成一個所謂的執行計劃,這個執行計劃展示了接下來具體執行查詢的方式,比如多表連線的順序是什麽,對於每個表采用什麽存取方法來具體執行查詢等等。設計MySQL的大叔貼心的為我們提供了EXPLAIN語句來幫助我們檢視某個查詢語句的具體執行計劃。
「
我們只用這個為我們服務一個點,那就是看有沒有走索引,比如你加上索引了 可是沒有效果,那就看看執行計劃,把你的sql執行 前面加一個Explain。
編寫查詢語句
首先,編寫你想要最佳化的查詢語句。例如:
SELECT * FROM orders WHERE customer_id = 123 AND order_date > '2023-01-01';
使用 EXPLAIN
在查詢語句前加上
EXPLAIN
關鍵字:
EXPLAIN SELECT * FROM orders WHERE customer_id = 123 AND order_date > '2023-01-01';
執行上述
EXPLAIN
語句,檢視輸出結果。MySQL 會返回一個包含查詢執行計劃的表格(例如下圖)。
+----+-------------+-------+--------+---------------+---------+---------+-------------------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+------+--------------------------+
| 1 | SIMPLE | d | const | PRIMARY | PRIMARY | 4 | const | 1 | |
| 1 | SIMPLE | e | ref | department_id | department_id | 4 | const | 10 | Using where |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+------+--------------------------+
具體解釋:
EXPLAIN
輸出表格包含多個列,每列提供不同的查詢計劃資訊。常見列包括:
id: 查詢的識別元,表示查詢的執行順序。
select_type: 查詢型別,如
SIMPLE(簡單查詢),PRIMARY(主查詢),UNION(聯合查詢的一部份),SUBQUERY(子查詢)。table: 查詢涉及的表。
type: 連線型別,表示MySQL如何尋找行。常見型別按效率從高到低排列為:
system: 表只有一行(常見於系統表)。
const: 表最多有一個匹配行(索引為主鍵或唯一索引)。
eq_ref: 對於每個來自前一個表的行,表中最多有一個匹配行。
ref: 對於每個來自前一個表的行,表中可能有多個匹配行。
range: 使用索引尋找給定範圍的行。
index: 全表掃描索引。
ALL: 全表掃描。
possible_keys: 查詢中可能使用的索引。
key: 實際使用的索引。
key_len: 使用的索引鍵長度。
ref: 使用的列或常量,與索引比較。
rows: MySQL 估計的要讀取的行數。
filtered: 經過表條件過濾後的行百分比。
Extra:
額外的資訊,如
Using index
(覆蓋索引),
Using where
(使用 WHERE 子句過濾),
Using filesort
(檔排序),
Using temporary
(使用臨時表)。
最佳化查詢路徑
根據 EXPLAIN 輸出,采取以下措施最佳化查詢路徑:
確保使用索引
如果 type 列顯示為 ALL 或 index,說明表進行了全表掃描。可以透過建立適當的索引來最佳化查詢。例如:
CREATE INDEX idx_customer_date ON orders (customer_id, order_date);
最佳化查詢條件
避免在索引列上使用函式或進行計算。覆寫查詢條件以利用索引。例如:
-- 避免
SELECT * FROM orders WHERE YEAR(order_date) = 2023;
-- 改為
SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31';
使用覆蓋索引
如果查詢只涉及索引中的列,可以避免回表,提高效能。例如:
CREATE INDEX idx_covering ON orders (customer_id, order_date, order_id);
-- 查詢只涉及索引中的列
SELECT customer_id, order_date, order_id FROM orders WHERE customer_id = 123;
分解復雜查詢
將復雜查詢分解為多個簡單查詢,可以提高效能。例如:
-- 復雜查詢
SELECT * FROM orders o JOIN customers c ON o.customer_id = c.id WHERE c.name = 'John Doe';
-- 分解為兩個簡單查詢
SELECT id FROM customers WHERE name = 'John Doe';
-- 假設查詢結果為 123
SELECT * FROM orders WHERE customer_id = 123;
實際範例
假設有一個 employees 表和一個 departments 表:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
department_id INT,
hire_date DATE,
INDEX (department_id),
INDEX (hire_date)
);
CREATE TABLE departments (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50)
);
查詢所有在某個日期後加入某部門的員工:
EXPLAIN
SELECT e.id, e.first_name, e.last_name
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE d.name = 'Sales' AND e.hire_date > '2023-01-01';
範例
EXPLAIN
輸出:
+----+-------------+-------+--------+---------------+---------+---------+-------------------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+------+--------------------------+
| 1 | SIMPLE | d | const | PRIMARY | PRIMARY | 4 | const | 1 | |
| 1 | SIMPLE | e | ref | department_id | department_id | 4 | const | 10 | Using where |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+------+--------------------------+
從
EXPLAIN
輸出可以看出:
d 表使用了 PRIMARY 索引,型別為 const,表示是一個常量尋找。
e 表使用了 department_id 索引,型別為 ref,表示參照尋找。
進一步最佳化:
如果查詢頻繁,可以為 departments.name 建立索引。
確保 hire_date 上有索引。
最佳化後的索引建立:
CREATE INDEX idx_department_name ON departments (name);
再次執行 EXPLAIN:
EXPLAIN
SELECT e.id, e.first_name, e.last_name
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE d.name = 'Sales' AND e.hire_date > '2023-01-01';
最佳化後的輸出可能顯示更好的執行計劃,減少查詢時間。
總結
透過以下步驟,可以有效使用
EXPLAIN
檢視查詢執行計劃並最佳化查詢路徑:
編寫並執行 EXPLAIN 查詢。
分析 EXPLAIN 輸出,關註 type、possible_keys、key 和 Extra 列。
根據輸出資訊最佳化索引、查詢條件和表結構。
重新執行 EXPLAIN,驗證最佳化效果。
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / 1v1 提問 / Java 學習路線 / 學習打卡 / 每月贈書 / 社群討論
新計畫: 【從零手擼:仿小紅書(微服務架構)】 正在持續爆肝中,基於 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., ;
【從零手擼:前後端分離部落格計畫(全棧開發)】 2期已完結,演示連結: http://116.62.199.48/ ;
截止目前, 累計輸出 48w+ 字,講解圖 2090+ 張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將 Java 領域典型的計畫都整一波,如秒殺系統, 線上商城, IM 即時通訊,Spring Cloud Alibaba 等等,

1.
2.
3.
4.
最近面試BAT,整理一份面試資料【Java面試BATJ通關手冊】,覆蓋了Java核心技術、JVM、Java並行、SSM、微服務、資料庫、數據結構等等。
獲取方式:點「在看」,關註公眾號並回復 Java 領取,更多內容陸續奉上。
PS:因公眾號平台更改了推播規則,如果不想錯過內容,記得讀完點一下「在看」,加個「星標」,這樣每次新文章推播才會第一時間出現在你的訂閱列表裏。
點「在看」支持小哈呀,謝謝啦











