
點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 新智元授權
【導讀】 近日,天才程式設計師Justine Tunney發推表示自己更新了Llamafile的程式碼,透過手搓84個新的矩陣乘法內核,將Llama的推理速度提高了500%!
谷歌的美女程式設計師,將Llama的推理速度提高了500%!
近日,天才程式設計師Justine Tunney發推表示自己更新了Llamafile的程式碼,

她重寫了84個新的矩陣乘法內核,使得Llamafile可以更快地讀取提示和影像。
與llama.cpp相比,新的Llamafile在CPU上的推理速度提升了30%到500%。

其中,ARMv8.2+(如RPI 5)、Intel(如Alderlake)和AVX512(如Zen 4)電腦的改進最為顯著。
另外,對於適合L2緩存的矩陣,新的內核比MKL快2倍!

Justine Tunney表示:負責MKL的大家,你們有事做了!
畢竟,由微軟,英特爾,TI,AMD,HPE,Oracle,Huawei,Facebook,ARM和National Science Foundation資助的BLIS,作為最強大的開源BLAS,輸了就太沒面子了!
Any time somebody outside Intel beats MKL by a nontrivial amount, I report it to the MKL team. It is fantastic for any open-source project to get within 10% of MKL... [T]his is why Intel funds BLIS development.
每當英特爾以外的人以不小的振幅擊敗MKL時,我都會向MKL團隊報告。對於任何開源計畫,超過MKL 10%以內就已經非常厲害了......這就是英特爾為BLIS開發提供資金的原因。
跨平台的「羊駝」
Llamafile作為一個本地LLM計畫,誕生於去年11月,由Justine Tunney與Mozilla團隊合作開發。
他們使用Cosmopolitan Libc,將llama.cpp打包為一個跨平台的單個二進制檔,讓「羊駝」可以在基於AMD64和ARM64的六個作業系統上執行。
而且在GPU短缺的情況下,Llamafile可以不需要昂貴的CUDA內核,——家裏的舊CPU,只要效能還行,再加一點RAM就足夠了,很好地保護了大家的錢包。

計畫地址:https://github.com/Mozilla-Ocho/llamafile/releases
Llamafile程式碼可以在GitHub上找到,使用C++編寫的,沒有外部依賴,可以在Linux、macOS、Windows、FreeBSD,甚至SerenityOS上編譯。
而且,Justine Tunney並沒有就此止步。她已經在努力支持新的數據格式,比如FP16和BF16,以進一步減少記憶體占用,——她甚至在Raspberry Pi上成功執行了TinyLlama!
效能提升
老惠普
Justine Tunney最開始嘗試LLM時,用的是下面這台簡陋的HP主機,執行Alpine,機械硬碟、慢速RAM、AVX2處理器、沒有 GPU。

HP Intel® Core™ i9-9900 ($439) w/ 2200 MT/s RAM
出於對llama.cpp的喜愛,Justine Tunney與人合作為其引入了mmap()支持,使得權重可以立即載入,只使用原來一半的RAM。
之後,Justine又花了很長的時間來最佳化程式碼,讓我來看一下改進後的效果:
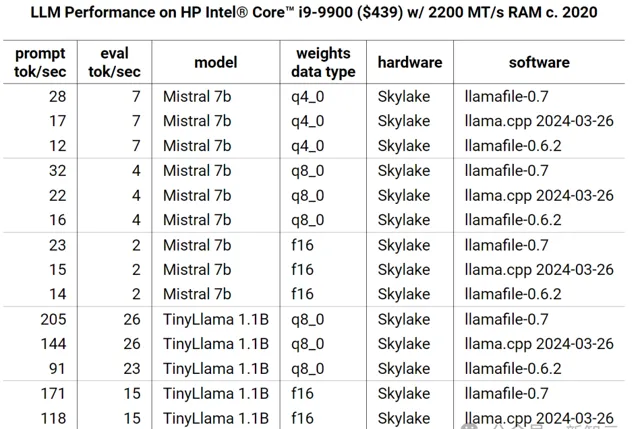
在Skylake上,llamafile實作了2倍的加速,llama.cpp也獲得了50%的效能提升。
到目前為止,Justine為q8_0、f16、q4_1、q4_0和f32數據型別編寫了最佳化的內核。
樹莓派
最新版的樹莓派不僅提升了主頻,還引入了對ARMv8.2 dotprod 和fp16算術ISA的支持,僅這兩個功能就讓llama.cpp在f16權重上實作了10倍效能提升。
因為樹莓派的兩個CPU都有32個向量寄存器,Justine使用為AVX512編寫的內核,使推理速度又提高了2倍。
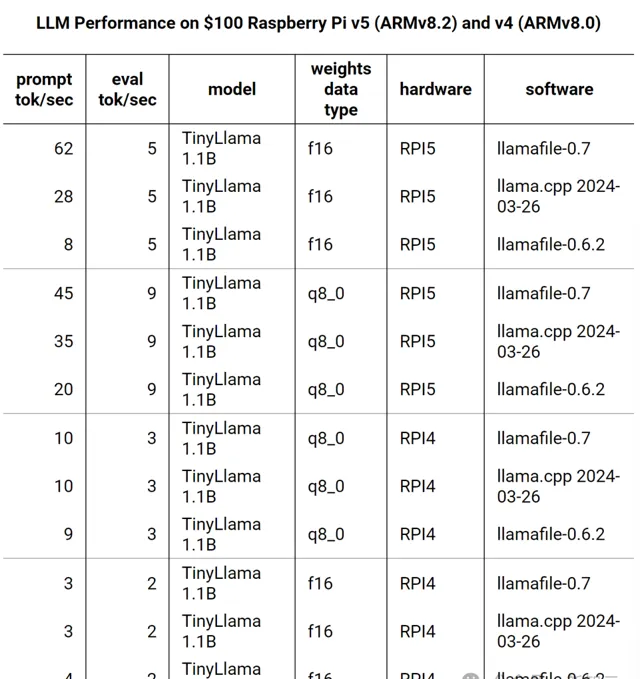
不過值得註意的是,新的ARMv8.2 fp16 ISA可能會引入比平時更多的錯誤,因為它會導致llamafile使用fp16。因此,Q8_0權重實際上的效果更好,因為它使用dotprod ISA。
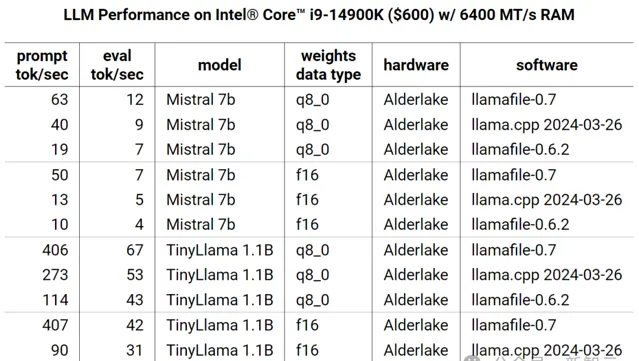
遊戲主機
在Alderlake CPU上,Justine將float16的效能提高了五倍。

與ARMv8.2不同,Alderlake能夠在不引入舍入錯誤的情況下做到這一點,因為內核在內部使用float32計算型別。
另外讓人吃驚的是,當涉及到小工作負載時,這個芯片甚至能夠在CUDA開始之前就完成任務。
蘋果
Mac Studio,作為llama.cpp開發人員最關心的硬體平台,想要在這裏提升效能比較困難。

另一個問題則是蘋果自身的封閉環境:
M2 Ultra將RAM DIMM放在了CPU內部,使得token生成等受延遲限制的操作速度更快,因為CPU不再需要打「長途電話」了。
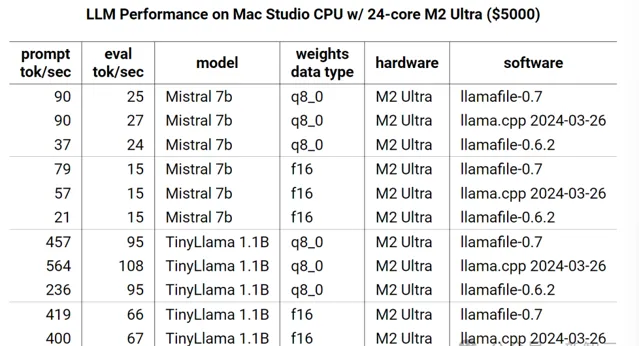
我們可以看到,與便宜得多的英特爾電腦相比,M2 Ultra僅透過ARM ISA暴露了30%的計算能力。
如果開發者想存取更多內容,則需要透過蘋果的專有框架,例如Metal和Accelerate。
AMD
雖然llamafile非常關心幫助缺乏GPU的人,但也為另外1%的人提供了一流的體驗。

AMD Ryzen Threadripper PRO 7995WX,透過花費10,000美元左右,你會得到96個基於Zen4架構的AVX512內核。
盡管價格只有M2 Ultra的兩倍,但7995WX x86 ISA提供的原始計算能力是M2 Ultra ARM ISA的7倍,token生成速度幾乎相同,這可能要歸功於384M的L3緩存。
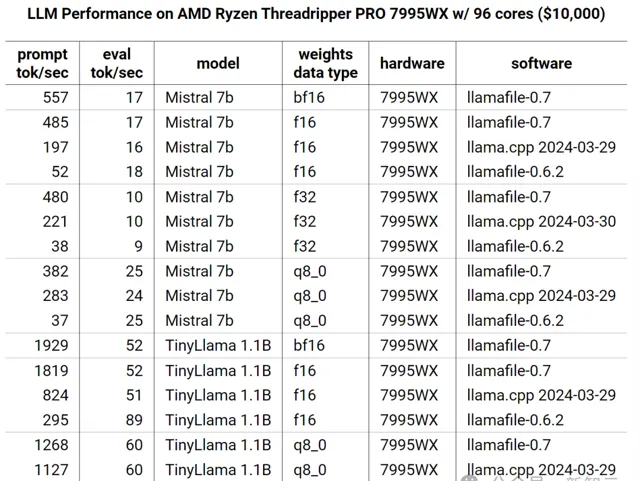
透過Justine的最佳化,現在可以在Zen4上以2.8倍的速度執行LLaMA。
天才程式設計師

Justine Tunney出生於1984年,14歲就開始幫別的黑客開發軟體,當時的綽號是「Oogle」。
我們來淺淺地看一下她這些年的一些工作:
RedBean
一個web伺服器,神奇的是可以跨平台在6種作業系統上執行!

這可不是Java那種疊了一層虛擬機器的機制,Justine開發了一種叫做APE(Acctually Portable Executbale)的檔格式,可以在任何x86-64的作業系統上執行。
「一次編譯,處處執行」——Java:嗯?這不是我嗎?
cosmopolitan libc
為了能夠跨平台呼叫外部程式,比如c標準庫,Justine直接手搓了一個libc,在各種平台上實作了所有需要的核心操作:
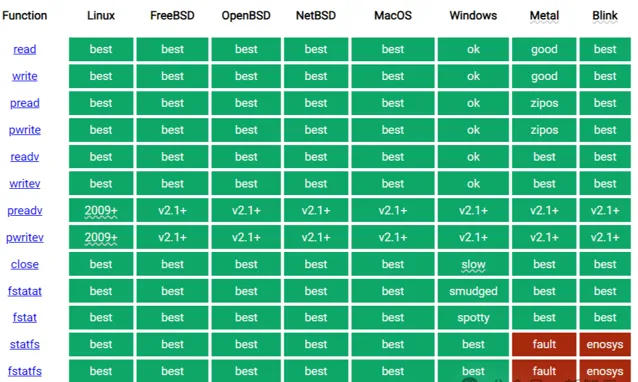
看一下上面的工作量,實在是太炸裂了,而且一般人就算想肝,沒有實力也是不可能的。
sectorLisp
僅有512個字節,最小的Lisp實作,可透過BIOS引導啟動:
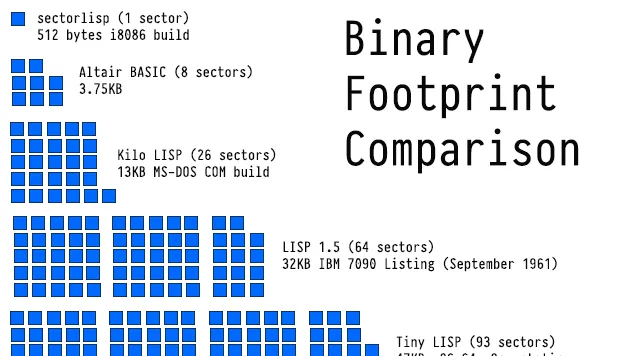
除了上面這幾個,還有諸如Blinkenlights、RoseHub等天才計畫,這裏不再一一列舉。
對於這番成就,有網友感嘆道:
Every time I read something by Justine Tunney, I am continually reminded of my mediocrity.
對於之前提到的mmap工作,網友評價:「有Fabrice Bellard之風」。
Justine Tunney is a true genius. Similar to Fabrice Bellard, a truly unique mind.
Justine or Fabrice are the true 10x engineers, their output is world class and they are much rarer than any hiring article about these gurus want us to believe. With Justine's work, I feel would need to be more than a 1x engineer myself just to find the time to play with all of her creations.
2012年,Justine Tunney開始在谷歌工作,並負責了一些知名計畫的關鍵部份。

比如大名鼎鼎的TensorFlow,Tunney為這個計畫做出了許多貢獻,包括用於儲存數據的摘要系統。
Bazel是谷歌從Make演變而來的PB級構建系統,Tunney的主要貢獻是下載器程式碼部份,用於自動化營運商級公共工件傳輸。
Nomulus是一項用於管理頂級網域名稱的服務,是谷歌的第一個開源生產服務。Tunney負責為其編寫登錄檔數據托管系統。
參考資料:
https://twitter.com/JustineTunney/status/1774621341473489024












