一、引入緩存後給業務帶來的問題
業務系統引入緩存之後,架構由原來的兩層架構變成了三層架構:
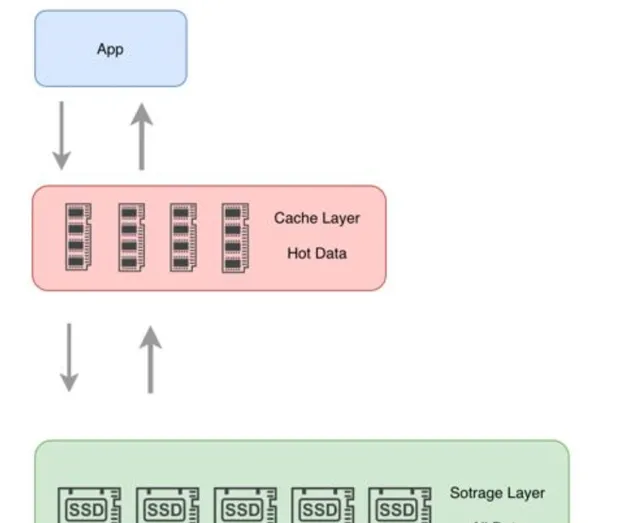
由此,帶來了三個問題需要解決,分別是緩存讀取、緩存更新和緩存淘汰。
1.緩存讀取

緩存讀取比較簡單,查詢數據時首先查詢緩存,如果緩存命中,則從緩存中讀取數據。如果緩存不命中,則查詢資料庫,並且更新緩存。
2.緩存更新
緩存更新時,在更新儲存和更新緩存的先後關系上,有以下幾種策略:
1)先更新資料庫再更新緩存
首先,這種方案會有執行緒安全的問題:
例如,同時有執行緒A和執行緒B對數據進行更新操作,可能會出現下面的執行順序。
①執行緒A更新了資料庫
②執行緒B更新了資料庫
③執行緒B更新了緩存
④執行緒A更新了緩存
此時就會出現資料庫中的數據與緩存的數據不一致的情況,這是因為執行緒A先更新了資料庫,可能因為網路等異常情況,執行緒B更新完資料庫進而更新了緩存,當執行緒B更新完緩存後,執行緒A才更新緩存,這就導致了資料庫數據與緩存數據的不一致。
其次,這種方案也有其不適用的業務場景:
首先一個業務場景就是資料庫寫多讀少的場景,這種場景下采用先更新資料庫再更新緩存的策略,就會導致緩存並未被讀取就會被頻繁的更新,極大的浪費了伺服器的效能。
再一個業務場景就是資料庫中的數據不是直接寫入緩存的,而是需要大量的復雜運算,將運算結果寫入緩存。如果這種場景下使用先更新資料庫再更新緩存的策略,也會造成伺服器資源的浪費。
2)先刪除緩存,再更新資料庫
先刪除緩存再更新資料庫的方案也存在著執行緒安全的問題,例如,執行緒A更新緩存,同時,執行緒B讀取緩存的數據。可能會出現下面的執行順序:
①執行緒A刪除緩存
②執行緒B查詢緩存,發現緩存中沒有想要的數據
③執行緒B查詢資料庫中的舊數據
④執行緒B將查詢到的舊數據寫入緩存
⑤執行緒A將新數據寫入資料庫
此時,就出現了資料庫中的數據和緩存中的數據不一致的情況。如果刪除緩存失敗,也會出現資料庫數據和緩存數據不一致的現象。
3)先更新資料庫,再刪除緩存
首先,這種方式也有極小的機率發生資料庫數據和緩存數據不一致的情況,例如,執行緒A做查詢操作,執行緒B執行更新操作,其執行的順序如下所示:
①緩存剛好失效
②請求A查詢資料庫,獲取到資料庫中的舊值
③請求B將新值寫入資料庫
④請求B刪除緩存
⑤請求A將查到的舊值寫入緩存
如果上述順序一旦發生,就會造成資料庫中的數據和緩存中的數據不一致的情況發生。但是,先更新資料庫再刪除緩存的策略發生資料庫和緩存數據不一致的機率很低,原因就是:③的寫資料庫操作比步驟②的讀資料庫操作耗時更短,才有可能使得步驟④先於步驟⑤執行。
但是,往往資料庫的讀操作的速度遠快於寫操作,因此步驟③耗時比步驟②更短這一場景很難出現。因此, 先更新資料庫,再刪除緩存是一種值得推薦的做法 。
4)異常情況
上面的討論與對比都是在刪除緩存和更新資料庫這兩步操作都成功的情況下敘述的。當然系統正常執行時的操作基本上都是成功的,那麽如果兩步操作有其中一步操作失敗了呢?以先更新資料庫再刪除緩存舉例:
更新資料庫失敗: 這種情況很簡單,不會影響第二步操作,也不會影響數據一致性,直接拋異常出去就好了;
更新緩存失敗: 這種情況需要繼續嘗試刪除緩存,直到緩存刪除成功,可以用一個訊息佇列完成,如下圖所示:
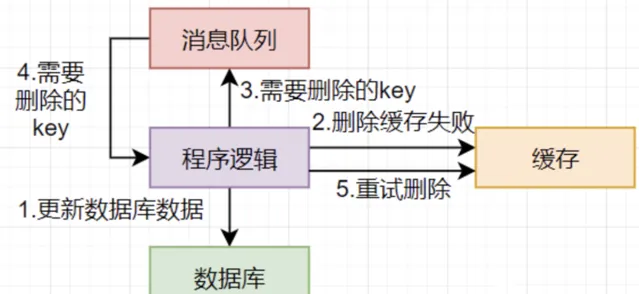
①更新資料庫數據;
②刪除緩存數據失敗;
③將需要刪除的key發送至訊息佇列;
④自己消費訊息,獲得需要刪除的key;
⑤繼續重試刪除操作,直到成功。
3.緩存淘汰
主要有兩種策略,分別是主動淘汰和被動淘汰:
主動淘汰: 給鍵值對設定TTL時間,到期自動淘汰(推薦),這種方式可以達到緩存熱數據的目的;
被動淘汰: 記憶體達到最大限制時,透過LRU、LFU演算法淘汰(不推薦),這種方式影響緩存效能,緩存品質不可控。
二、緩存的三座大山
1.一致性
一致性主要解決以下幾個問題:
1)並列更新如何解決隔離性問題
序列更新: 單個Key更新序列需要序列更新,保證時序
並列更新: 不同的key可以放到不同的Slot中,在Slot維度可以進行並列更新,提升效能
2)原子性更新時如何解決部份更新的問題
系統聯動: 緩存&儲存即時同步更新狀態,透過revision同步狀態
部份成功: 緩存更新成功,儲存更新失敗,觸發HA,保障寫入成功(日誌冪等)
3)如何解決讀一致的問題
revision: 每個Key都帶有一個revision,透過revision辨識數據新舊
淘汰控制: Redis不淘汰儲存未更新的數據(Redis不淘汰revision < 4的數據),保證Redis不緩存舊版本數據
2.緩存擊穿
緩存擊穿指的是存取數據時直接繞過緩存,存取資料庫。可能會有兩種原因造成這種現象:
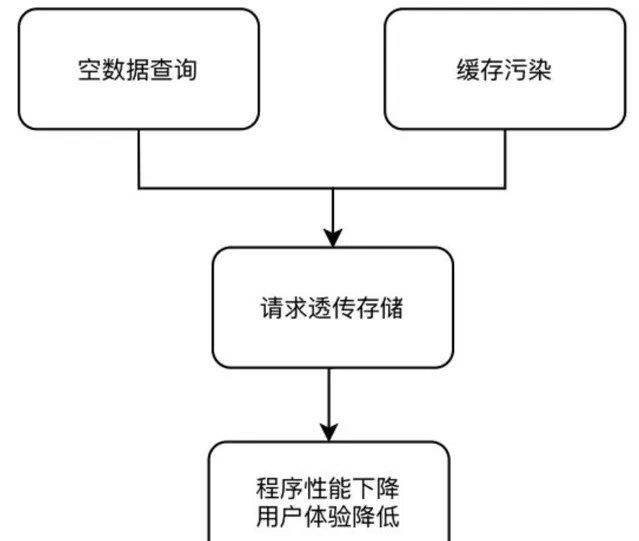
一種是大量的空查詢,比如黑客攻擊;另外一種是緩存汙染,比如大量的網路爬蟲造成的。
1)為了解決空查詢帶來的緩存擊穿,主要有兩種方案:
第一種是在緩存層前面再加一層布隆過濾器 ,布隆過濾器是一種數據結構,比較巧妙的機率型數據結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你 「某樣東西一定不存在或者可能存在」。布隆過濾器是一個 bit 向量或者說 bit 陣列,長這樣:

如果我們要對映一個值到布隆過濾器中,我們需要使用多個不同的哈希函式生成多個哈希值,並對每個生成的哈希值指向的 bit 位置 1,例如針對值 「baidu」 和三個不同的哈希函式分別生成了哈希值 1、4、7,則上圖轉變為:
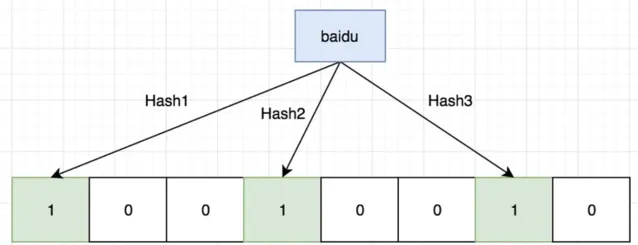
我們現在再存一個值 「tencent」,如果哈希函式返回 3、4、8 的話,圖繼續變為:
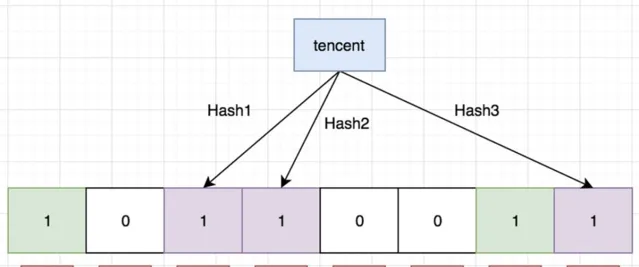
值得註意的是,4 這個 bit 位由於兩個值的哈希函式都返回了這個 bit 位,因此它被覆蓋了。現在我們如果想查詢 「dianping」 這個值是否存在,哈希函式返回了 1、5、8三個值,結果我們發現 5 這個 bit 位上的值為 0, 說明沒有任何一個值對映到這個 bit 位上 ,因此我們可以很確定地說 「dianping」 這個值不存在。
而當我們需要查詢 「baidu」 這個值是否存在的話,那麽哈希函式必然會返回 1、4、7,然後我們檢查發現這三個 bit 位上的值均為 1,那麽 我們可以說 「baidu」 存在了麽?答案是不可以,只能是 「baidu」 這個值可能存在。
這是為什麽呢?答案很簡單,因為隨著增加的值越來越多,被置為 1 的 bit 位也會越來越多,這樣某個值 「taobao」 即使沒有被儲存過,但是萬一哈希函式返回的三個 bit 位都被其他值置位了 1 ,那麽程式還是會判斷 「taobao」 這個值存在。
很顯然,過小的布隆過濾器很快所有的 bit 位均為 1,那麽查詢任何值都會返回「可能存在」,起不到過濾的目的了。布隆過濾器的長度會直接影響誤報率,布隆過濾器越長其誤報率越小。另外,哈希函式的個數也需要權衡,個數越多則布隆過濾器 bit 位置位 1 的速度越快,且布隆過濾器的效率越低;但是如果太少的話,那我們的誤報率會變高。
第二種是把所有的key和熱數據value加入緩存,在緩存層攔截空數據查詢。
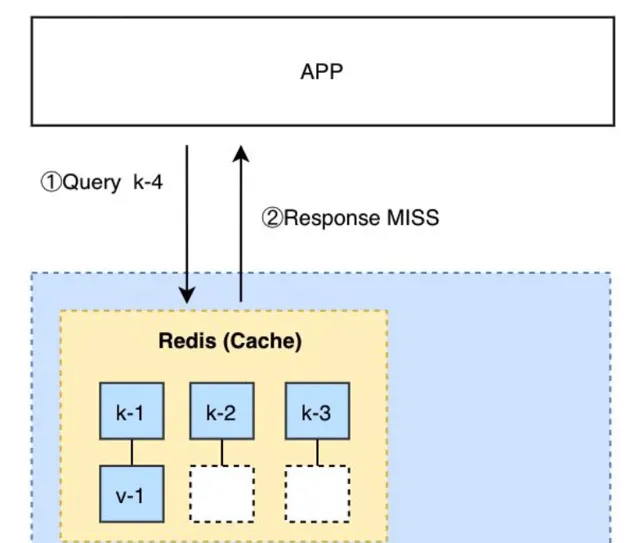
2)為了解決爬蟲帶來的緩存擊穿問題,可以設定緩存策略:
針對更新的操作,需要立即緩存
針對讀的操作,可以在設定是否立即緩沖還是延遲緩存,以及在規定的時間窗內命中的次數是否達到一定的次數才進行緩存
3.緩存雪崩
緩存雪崩指的是熱數據集中淘汰,大量請求瞬間透傳到儲存層,導致儲存層過載。
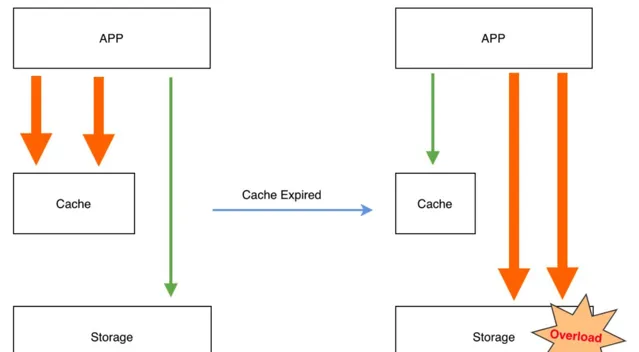
造成緩存雪崩的原因主要是TTL機制過於簡單造成的,解決方案主要有以下:
設定TTL時給過期時間加上一個隨機的時間值
每一次的存取都會重新更新TTL,此外業務可以更精準地指定熱數據緩存時間
作者丨蓬萊道人
來源丨 blog.csdn.net/MOU_IT/article/details/116427814
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]
活動推薦
2024 XCOPS智慧運維管理人年會·廣州站將於5月24日舉辦 ,深究大模型、AI Agent等新興技術如何落地於運維領域,賦能企業智慧運維水平提升,構建全面運維自治能力!












