計畫簡介
ID-Animator 是一個無需重新訓練就能生成身份特定的人類視訊的框架。利用單張面部參考影像,它可以生成高品質的個人化視訊。此框架采用基於擴散的視訊生成技術,並結合面部介面卡來編碼與身份相關的嵌入式表示。它還引入了一個面向身份的數據集構建流程,以及一個基於隨機面部參考的訓練方法,從而在不需要精細調整的情況下,有效提高視訊的身份保真度和模型的泛化能力。
掃碼加入交流群
獲得更多技術支持和交流
(請註明自己的職業)

Demo
·重新語境化
· 使用社群模型進行推理
·身份混合
·與 ControlNet 結合
技術方案
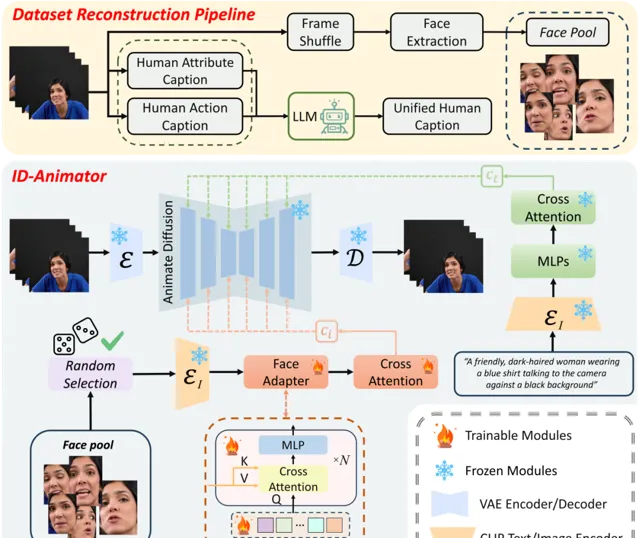
生成高保真人物視訊並指定身份在內容生成社群引起了廣泛關註。然而,現有技術在訓練效率和身份保留之間難以取得平衡,要麽需要繁瑣的逐例微調,要麽在視訊生成過程中通常無法保留身份細節。
在本研究中,提出了一種名為ID-Animator的零樣本人物視訊生成方法,該方法能夠使用單個參考面部影像進行個人化視訊生成,無需進一步訓練。
ID-Animator繼承了現有基於擴散的視訊生成骨幹網路,並增加了一個面部介面卡,用以從可學習的面部潛在查詢中編碼與身份相關的嵌入。
為了在視訊生成中便於提取身份資訊,我們引入了一個面向身份的數據集構建流程,該流程采用從構建的面部影像池中解耦的人類內容和行為標題技術。
基於此流程,進一步設計了一種隨機面部參考訓練方法,以精確捕獲參考影像中與身份相關的嵌入,從而提高模型在特定身份視訊生成中的保真度和泛化能力。
廣泛的實驗表明,ID-Animator在生成個人化人物視訊方面優於之前的模型。此外,此方法與流行的預訓練T2V模型如animatediff以及各種社群支持的骨幹模型高度相容,顯示出在現實世界套用中的高擴充套件性,特別是在需要高度身份保留的視訊生成場景中。
計畫連結
https://github.com/id-animator/id-animator
論文連結
https://arxiv.org/abs/2404.15275
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點











