
日常開發中,我們經常需要寫查詢SQL。但是,大家知道一條查詢SQL在mysql內部是如何執行的嘛?比如這條簡單的SQL:
select * from test_db.user_info_tab where user_id =123;
我們知道在mySQL客戶端,輸入一條查詢SQL,然後看到返回查詢的結果。這條查詢語句在 MySQL 內部到底是如何執行的呢?本文跟大家探討一下哈,我們先來看下MySQL基本架構~
MySQL 基本架構
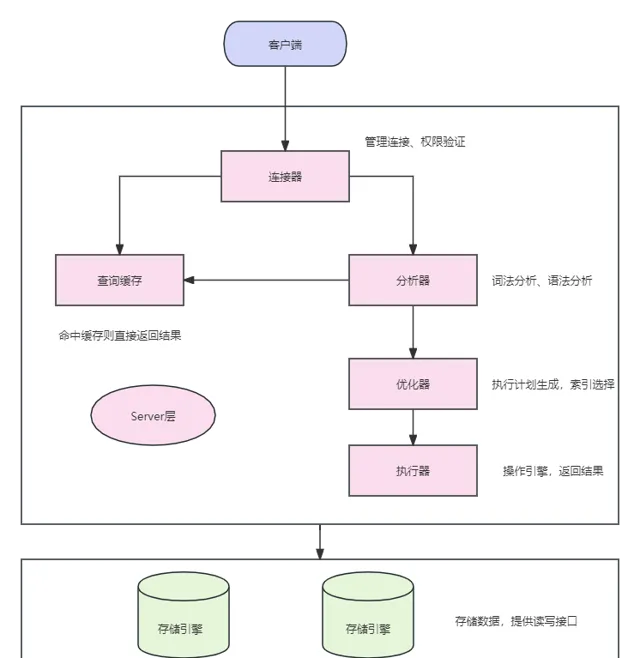
總體來說,MySQL大體分為兩部份,分別是 Server 層和儲存引擎層 。
Server 層
它包括 連結器、查詢緩存、分析器、最佳化器、執行器 等。比如 儲存過程,觸發器,檢視 都是在這一層實作的。
連結器 (Connection Manager) :負責處理客戶端與伺服器之間的連線。它接受來自客戶端的請求,並進行身份驗證和許可權檢查,建立和管理連線。
查詢緩存(Query Cache) :在舊版 MySQL 中有,但在較新的版本中已不推薦使用。它能夠緩存查詢和對應的結果,以提高查詢效能。然而,在高並行和大型資料庫中,它反而可能成為效能瓶頸,因為它在某些情況下會引起鎖和不必要的開銷。
分析器(Parser) :負責分析 SQL 查詢語句,驗證其語法和語意,確保查詢的正確性。它將 SQL 語句轉換成內部數據結構供最佳化器和執行器使用。
最佳化器(Optimizer) :接收來自分析器的查詢請求,並決定如何最有效地執行查詢。最佳化器的目標是找到最佳的執行路徑,選擇合適的索引、連線順序和存取方法,以提高查詢效能。
執行器(Executor) :負責執行最佳化器生成的執行計劃,獲取儲存引擎返回的數據,並處理客戶端請求。它與儲存引擎互動,執行查詢並返回結果給使用者。
儲存引擎層: 它負責數據的儲存和提取。Mysql支持InnoDB、MyISAM、Memory 等多個儲存引擎。我們日常開發中,一般用的儲存引擎就是InnoDB。從 MySQL 5.5 版本開始,InnoDB 就成為了預設的儲存引擎。
介紹完MySQL基本架構,帶大家看一下,每個元件,一條查詢SQL主要做什麽事~~
連結器
我們要執行查詢SQL,一般在MySQL客戶端, 需要輸入連線命令,連線到MySQL伺服端。在MySQL伺服端,就是 連結器 負責跟你的客戶端 建立連線、獲取許可權、維持和管理連線 。
連線命令如下:
mysql -h(ip地址) -P(埠) -u(使用者名稱) -p
輸入完連線命令之後,我們接著輸入正確的密碼,經過經典的TCP握手之後,就可以成功 連線 到MySQL伺服器啦,如下:
C:\MySQL\MySQL Server 8.0\bin>mysql -h 127.0.0.1 -P 3306 -u root -p
Enter password: ******
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 50
Server version: 8.0.31 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h'forhelp. Type '\c' to clear the current input statement.
mysql>
如果輸入密碼錯誤,則會收到一個
Access denied
的錯誤資訊,如下:
C:\Program Files\MySQL\MySQL Server 8.0\bin>mysql -h 127.0.0.1 -P 3306 -u root -p
Enter password: *****
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
連線成功之後,大家就可以直接輸入查詢SQL,就可以看到結果啦。
mysql> select * from test_db.user_info_tab where user_id =123;
+---------+----------------+------+------+--------+---------+--------------------------+
| id | user_name | age | city | status | user_id | password |
+---------+----------------+------+------+--------+---------+--------------------------+
| 1570091 | 撿田螺的小男孩 | 28 | 深圳 | 活躍 | 123 | 523da7ne+yndc5nb1zWWlA== |
+---------+----------------+------+------+--------+---------+--------------------------+
1 row inset (0.01 sec)
大家註意一下哈,如果連線成功後,沒有後續的輸入查詢SQL等其他操作。這時候,這個連線是空閑的哈,可以用
show processlist
檢視。
查詢緩存
在 老版本的MySQL 中,連線成功後,我們執行查詢SQL,會先執行 查詢緩存 。
也就是說MySQL接受到一個查詢SQL請求時,會先去查詢緩存看看,如果緩存有這條SQL的查詢結果,會直接返回。如果查詢緩存沒有,就繼續往下執行,執行完之後,把結果寫入緩存。其中,這個查詢緩存是key-value的結果,你可以把它理解為一個map吧,其中key就是這個查詢SQL,value則是這個查詢的結果。
同時,如果你查詢的表進行更新的時候,會清空緩存的。
一個表更新比較頻繁的話,使用查詢緩存命中率會很低
,你剛查完放到緩存,更新SQL又清空了,就很不劃算。有些時候,一些靜態配置表,很少更新的,才建議使用查詢緩存。其他更新頻繁的表,則不建議使用查詢緩存,你可以透過這個參數
query_cache_type
設值是否走查詢緩存。
其實,MySQL 比較新的版本,如8.0 已經廢棄了查詢緩存,並且相應的參數
query_cache_type
也不再存在。因為在高並行和大型資料庫環境下,查詢緩存可能導致效能問題,並且在實際測試中發現,禁用查詢緩存可能會提高整體效能和可伸縮性。
分析器
如果查詢SQL沒有命中查詢緩存的話,繼續往下執行,就到分析器上場了。它負責分析 SQL 查詢語句, 驗證其語法和語意,確保查詢的正確性 。
你扔個SQL給MySQL伺服器,它肯定需要先解析,才知道這個SQL是做什麽的,對吧。它會派出分析器,先做 詞法分析 。你送出過來的查詢SQL是由很多個字元創和空格組成的,MySQL會先解析出這些字串表示什麽意思。
select * from test_db.user_info_tab where user_id =123;
它先把關鍵字
select
解析出來,然後把
user_info_tab
解析成表,
user_id
解析成列名。做完詞法分析之後,開始做
語法分析
。語法分析主要就是判斷,你的SQL是否滿足MYSQL的語法。
如果你的SQL寫錯了,語法分析就會報錯誤提示:
ERROR 1064 (42000): You have an error in your SQL syntax;
mysql> select * rom test_db.user_info_tab where user_id =123;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'rom test_db.user_info_tab where user_id =123' at line 1
平時大家看到這個錯誤的時候,只需要,關註關鍵詞
syntax to use near
就可以快速知道哪裏寫錯啦。比如這個例子,就是我的
from
寫錯了,少了
f
。
最佳化器
經過分析器之後,MySQL已經知道需要做什麽了。但是在經過執行器之前,還會 先經過最佳化器 。最佳化器做的事情就是,怎麽去做才是最好的。對於一條查詢SQL來說就是:怎麽去查是最佳效率的。
比如這個查詢SQL:
select * from test_db.user_info_tab where user_id =123 and user_name='田螺';
其中,在
user_info_tab
表中,
user_id
為索引欄位,
user_name
也是索引欄位。
這條SQL執行的時候,可能使用索引
user_id
,也可能使用使用
user_name
。選擇不同的索引,執行效率是不一樣的。具體怎麽選擇,就是最佳化器所做的事情。
大家是否還記得
explain
。我們使用它加在我們查詢的SQL,就可以幫助了解最佳化器在執行查詢時,選擇的執行計劃和相應的最佳化策略。
經過最佳化器之後,就來到了執行器階段。也就是真正執行查詢SQL了。
執行器
select * from test_db.user_info_tab where user_id =123 ;
在要開始執行時候,會判斷一下,該使用者是否對這個SQL有查詢的許可權,如果沒有,則會報許可權錯誤。如果有許可權的時候,開啟表直接執行。執行的過程,其實類似於 執行呼叫引擎提供的介面 。
我們現在假設
user_id
不是索引欄位,我們使用的是
InnoDb
儲存引擎,這個查詢SQL執行過程就是這樣:
呼叫
InnoDb儲存引擎提供的介面,獲取user_info_tab表的 第一行 。判斷
user_id是不是為123,如果不是,跳過這一行。如果是,把這一行放到結果集。呼叫
InnoDb儲存引擎提供的介面,獲取user_info_tab表的 下一行 。判斷
user_id是不是為123,如果不是,跳過這一行。如果是,把這一行放到結果集。重復3、4步驟,一直掃描完
user_info_tab表的所有行。最後把結果集返回客戶端。
聊到這裏,其實一條查詢SQL的執行過程,已經講完啦,是不是很簡單呀~~
來源:網路
>>
END
精品資料, 超贊福利, 免費領
微信 掃碼 / 長按辨識 添加【 技術交流群 】
群內每天分享精品學習資料

最近開發整理了一個用於速刷面試題的小程式 ;其中收錄了 上千道 常見面試題及答案(包含 基礎 、 並行 、 JVM 、 MySQL 、 Redis 、 Spring 、 SpringMVC 、 SpringBoot 、 SpringCloud 、 訊息佇列 等多個型別),歡迎您的使用。
👇👇
👇 點選" 閱讀原文 ",獲取更多資料( 持續更新中 )











