計畫簡介
DBRX是Databricks推出的最新一代開源大型語言模型(LLM),在多個標準基準測試中創下新的最高記錄,超越了GPT-3.5並與Gemini 1.0 Pro具有競爭力。它特別擅長編程任務,比專門的編程模型CodeLLaMA-70B還要優秀。DBRX采用細粒度混合專家(MoE)架構,使得訓練和推理效能大幅提升,推理速度比LLaMA2-70B快2倍,模型大小只有Grok-1的40%。
掃碼加入交流群
獲得更多技術支持和交流
(請註明自己的職業)

效能
這種最先進的品質伴隨著在訓練和推理效能上的顯著改進。DBRX在開放模型中以其細粒度的混合專家(MoE)架構,推進了效率的最先進水平。與LLaMA2-70B相比,推理速度提高了2倍,而且DBRX的總參數量和活躍參數量約為Grok-1的40%。
當部署在Mosaic AI Model Serving上時,DBRX可以實作每秒最多150個token的文本生成速率。與訓練相同最終模型品質的密集模型相比,訓練MoEs的FLOP效率也提高了約2倍。從端到端來看,DBRX總體配方(包括預訓練數據、模型架構和最佳化策略)幾乎可以用不到4倍的計算量匹配上一代MPT模型的品質。
DBRX是什麽
DBRX是一個基於Transformer的僅解碼器大型語言模型(LLM),透過下一個token的預測進行訓練。它采用了一個細粒度的混合專家(MoE)架構,總共有1320億個參數,其中360億個參數在任何輸入上都是活躍的。它在12T個文本和程式碼數據的token上進行了預訓練。
與其他開放的MoE模型如Mixtral和Grok-1相比,DBRX是細粒度的,這意味著它使用了更多數量但更小的專家。DBRX擁有16個專家並選擇4個,而Mixtral和Grok-1有8個專家並選擇2個。這提供了65倍更多可能的專家組合,發現這提高了模型品質。DBRX使用旋轉位置編碼(RoPE)、門控線性單元(GLU)和分組查詢註意力(GQA)。它使用的是tiktoken倉庫提供的GPT-4分詞器。基於詳盡的評估和規模實驗做出了這些選擇。
DBRX在12T個精心策劃的數據上進行了預訓練,最大上下文長度為32k個token。估計這些數據的token對token的品質至少比用於預訓練MPT系列模型的數據好2倍。這個新數據集是使用Databricks的全套工具開發的,包括Apache Spark™和Databricks筆記本進行數據處理,Unity Catalog進行數據管理和治理,以及MLflow進行實驗跟蹤。使用了課程學習進行預訓練,在訓練過程中改變數據混合,發現這在顯著提高模型品質方面很有幫助。
對比
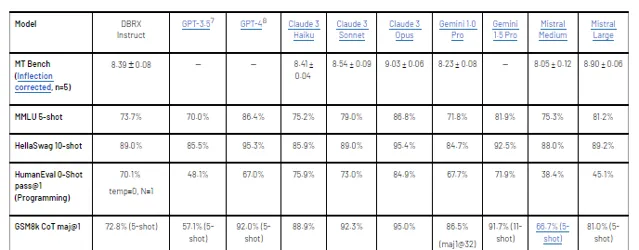
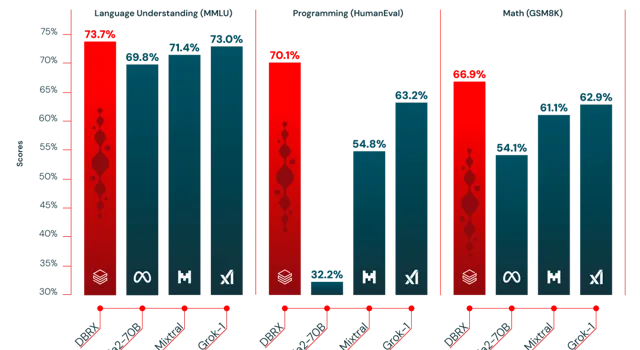
根據每個模型建立者報告的分數,DBRX Instruct超過了GPT-3.5(如GPT-4論文所描述),並且與Gemini 1.0 Pro和Mistral Medium具有競爭力。
在考慮的幾乎所有基準測試中,DBRX Instruct要麽超過要麽至少與GPT-3.5持平。在由MMLU測量的通用知識上,DBRX Instruct的表現超過了GPT-3.5(73.7%對70.0%),在由HellaSwag和WinoGrande測量的常識推理上,也超過了GPT-3.5(分別為89.0%對85.5%和81.8%對81.6%)。特別是在由HumanEval和GSM8k測量的編程和數學推理上,DBRX Instruct表現尤為出色(分別為70.1%對48.1%和72.8%對57.1%)。
DBRX Instruct與Gemini 1.0 Pro和Mistral Medium具有競爭力。在Inflection Corrected MTBench、MMLU、HellaSwag和HumanEval上,DBRX Instruct的分數高於Gemini 1.0 Pro,而Gemini 1.0 Pro在GSM8k上更強。DBRX Instruct與Mistral Medium在HellaSwag上的分數相似,而在Winogrande和MMLU上Mistral Medium更強,DBRX Instruct則在HumanEval、GSM8k和Inflection Corrected MTBench上更強。
推理速度
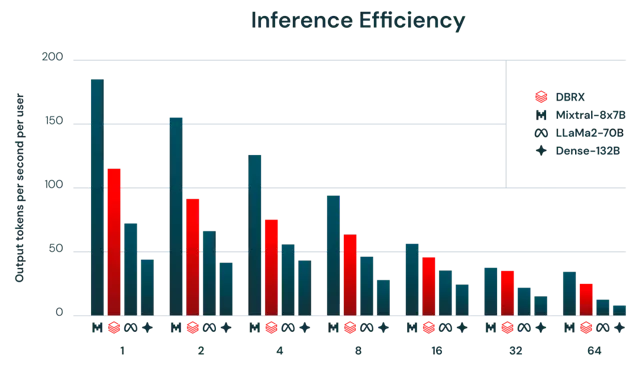
一般來說,MoE模型的推理速度比其總參數數量所暗示的要快。這是因為它們對每個輸入使用相對較少的參數。我們發現DBRX在這方面也不例外。DBRX的推理吞吐量比一個132B非MoE模型高2-3倍。
推理效率和模型品質通常存在緊張關系:更大的模型通常能達到更高的品質,但較小的模型在推理時更高效。使用MoE架構可以實作在模型品質和推理效率之間比密集模型通常能達到的更好的權衡。例如,DBRX不僅品質高於LLaMA2-70B,而且由於活躍參數數量大約減半,DBRX的推理吞吐量可達到2倍(圖2所示)。
Mixtral是MoE模型達到的改進帕累托最前沿的另一個範例:它比DBRX小,並且相應地在品質上較低,但達到了更高的推理吞吐量。使用Databricks基礎模型API的使用者可以期待在最佳化的模型服務平台上使用8位元量化的DBRX達到每秒最多150個token。
計畫連結
https://github.com/databricks/dbrx
關註「 開源AI計畫落地 」公眾號











