點選關註公眾號,Java幹貨 及時送達 👇

首先,說明一下問題:CPU飆升200% 以上是生產容易發生的場景
場景:1:MySQL行程飆升900%
大家在使用MySQL過程,想必都有遇到過CPU突然過高,或者達到200%以上的情況。
資料庫執行查詢或數據修改操作時,系統需要消耗大量的CPU資源維護從儲存系統、記憶體數據中的一致性。
並行量大並且大量SQL效能低的情況下,比如欄位是沒有建立索引,則會導致快速CPU飆升,如果還開啟了慢日誌記錄,會導致效能更加惡化。生產上有MYSQL 飆升900% 的惡劣情況。
場景2:Java行程飆升900%
一般來說Java 行程不做大量 CPU 運算,正常情況下,CPU 應該在 100~200% 之間,
但是,一旦高並行場景,要麽走到了死迴圈,要麽就是在做大量的 GC, 容易出現這種 CPU 飆升的情況,CPU飆升900%,是完全有可能的。
其他場景:其他的類似行程飆升900%的場景
比如Redis、Nginx等等。
陳某提示:大家介紹場景的時候,就說自己主要涉及了兩個場景, Java行程飆升900%、MySQL行程飆升900%兩種場景,其實,這兩個場景就足夠講半天了, 其他的,使用規避技巧規避一下就行。
場景一:MySQL行程CPU飆升到900%,怎麽處理?
定位過程:
使用top 命令觀察,確定是mysqld導致還是其他原因。
如果是mysqld導致的,show processlist,檢視session情況,確定是不是有消耗資源的sql在執行。
找出消耗高的 sql,看看執行計劃是否準確, index 是否缺失,或者實在是數據量太大造成。
處理過程:
kill 掉這些執行緒(同時觀察 cpu 使用率是否下降), 一般來說,肯定要 kill 掉這些執行緒(同時觀察 cpu 使用率是否下降),等進行相應的調整(比如說加索引、改 sql、改記憶體參數)之後,再重新跑這些 SQL。
進行相應的調整(比如說加索引、改 sql、改記憶體參數)
index 是否缺失,如果是,則 建立索引。也有可能是每個 sql 消耗資源並不多,但是突然之間,有大量的 session 連進來導致 cpu 飆升,這種情況就需要跟套用一起來分析為何連線數會激增,再做出相應的調整,比如說限制連線數等;
最佳化的過程,往往不是一步完成的,而是一步一步,執行一項最佳化措辭,再觀察,再最佳化。
場景1的真實案例:MySQL資料庫最佳化的真實案例
陳某提示:以下案例,來自互聯網。大家參考一下,準備一個自己的案例。
本問題親身經歷過。
之前開發同事編寫的SQL語句,就導致過線上CPU過高,MySQL的CPU使用率達到900%+,透過最佳化最後降低到70%~80%。下面說說個人在這個過程中的排查思路。
首先,我們要對問題定位而不是盲目的開啟什麽 慢日誌,在並行量大並且大量SQL效能低的情況下,開啟慢日誌無意是將MySQL推向崩潰的邊緣。
當時遇到這個情況,分析了當前的數據量、索引情況、緩存使用情況。目測數據量不大,也就幾百萬條而已。接下來就去定位索引、緩存問題。
經過詢問,發現很多查詢都是走MySQL,沒有用到緩存。
既然沒有用到緩存,則是大量請求全部查詢MySQL導致。透過下面的命令檢視:
show processlist;
發現類似很多相同的SQL語句,一直處於query狀態中。
select id form user where user_code = 'xxxxx';
初步分析可能是 user_code 欄位沒有索引導致。接著查詢user表的索引情況:
show index form user;
發現這個欄位是沒有建立索引。增加索引之後,該條SQL查詢能夠正常執行。
3、沒隔一會,又發生大量的請求超時問題。接著進行分析,發現是開啟了 慢日誌查詢。大量的SQL查詢語句超過慢日誌設定的閥值,於是將慢日誌關閉之後,速度瞬間提升。CPU的使用率基本保持在300%左右。但還不是理想狀態。
4、緊接著將部份即時查詢數據的SQL語句,都透過緩存(redis)讀寫實作。觀察一段時間後,基本維持在了70%~80%。
總結:其實本次事故的解決很簡單,就是添加索引與緩存結合使用。
不推薦在這種CPU使用過高的情況下進行慢日誌的開啟。因為大量的請求,如果真是慢日誌問題會發生日誌磁盤寫入,效能賊低。
直接透過MySQL show processlist命令檢視,基本能清晰的定位出部份查詢問題嚴重的SQL語句,在針對該SQL語句進行分析。一般可能就是索引、鎖、查詢大量欄位、大表等問題導致。
再則一定要使用緩存系統,降低對MySQL的查詢頻次。
對於記憶體調優,也是一種解決方案。
場景2展開:Java行程CPU飆升到900%,怎麽處理?
定位過程:
CPU飆升問題定位的一般步驟是:
首先透過top指令檢視當前占用CPU較高的行程PID;
檢視當前行程消耗資源的執行緒PID:top -Hp PID
透過print命令將執行緒PID轉為16進制,根據該16進制值去打印的堆疊日誌內查詢,檢視該執行緒所駐留的方法位置 。
透過jst ack命令,檢視棧資訊,定位到執行緒對應的具體程式碼。
分析程式碼解決問題。
處理過程:
如果是空迴圈,或者空自旋。
處理方式:可以使用Thread.sleep或者加鎖,讓執行緒適當的阻塞。
在迴圈的程式碼邏輯中,建立大量的新物件導致頻繁GC。比如,從mysql查出了大量的數據,比如100W以上等等。
處理方式:可以減少物件的建立數量,或者,可以考慮使用 物件池。
其他的一些造成CPU飆升的場景,比如 selector空輪訓導致CPU飆升 。
處理方式:參考Netty源碼,無效的事件查詢到了一定的次數,進行 selector 重建。
Java的CPU 飆升700%最佳化的真實案例
提示:以下案例,來自互聯網。大家參考一下,準備一個自己的案例。
最近負責的一個計畫上線,執行一段時間後發現對應的行程竟然占用了700%的CPU,導致公司的物理伺服器都不堪重負,頻繁宕機。
那麽,針對這類java行程CPU飆升的問題,我們一般要怎麽去定位解決呢?、
采用top命令定位行程
登入伺服器,執行top命令,檢視CPU占用情況,找到行程的pid
top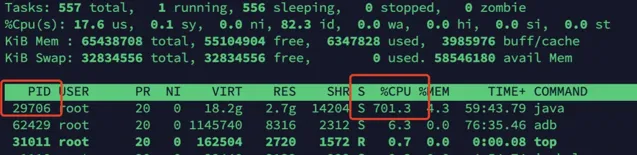
很容易發現,PID為29706的java行程的CPU飆升到700%多,且一直降不下來,很顯然出現了問題。
使用top -Hp命令定位執行緒
使用 top -Hp命令(為Java行程的id號)檢視該Java行程內所有執行緒的資源占用情況(按shft+p按照cpu占用進行排序,按shift+m按照記憶體占用進行排序)
此處按照cpu排序:
top -Hp 23602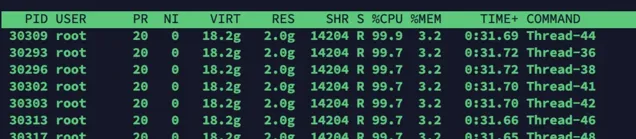
很容易發現,多個執行緒的CPU占用達到了90%多。我們挑選執行緒號為30309的執行緒繼續分析。
使用jstack命令定位程式碼
1.執行緒號轉換5為16進制
printf 「%x\n」 命令(tid指執行緒的id號)將以上10進制的執行緒號轉換為16進制:
printf"%x\n" 30309
轉換後的結果分別為7665,由於匯出的執行緒快照中執行緒的nid是16進制的,而16進制以0x開頭,所以對應的16進制的執行緒號nid為0x7665
2.采用jstack命令匯出執行緒快照
透過使用dk內建命令jstack獲取該java行程的執行緒快照並輸入到檔中:
jstack -l 行程ID > ./jstack_result.txt
命令(為Java行程的id號)來獲取執行緒快照結果並輸入到指定檔。
jstack -l 29706 > ./jstack_result.txt
3.根據執行緒號定位具體程式碼
在jstack_result.txt 檔中根據執行緒好nid搜尋對應的執行緒描述
cat jstack_result.txt |grep -A 100 7665
根據搜尋結果,判斷應該是ImageConverter.run()方法中的程式碼出現問題
當然,這裏也可以直接采用
jstack <pid> |grep -A 200 <nid>
來定位具體程式碼
$jstack 44529 |grep -A 200 ae24
"System Clock"#28 daemon prio=5 os_prio=0 tid=0x00007efc19e8e800 nid=0xae24 waiting on condition [0x00007efbe0d91000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrentC.TimeUnit.sleep(TimeUnit.java:386)
at com.*.order.Controller.OrderController.detail(OrderController.java:37) //業務程式碼阻塞點
分析程式碼解決問題
下面是ImageConverter.run()方法中的部份核心程式碼。
邏輯說明:
/儲存minicap的socket連線返回的數據 (改用訊息佇列儲存讀到的流數據) ,設定阻塞佇列長度,防止出現記憶體溢位
//全域變量
private BlockingQueue<byte[]> dataQueue = new LinkedBlockingQueue<byte[]>(100000);
//消費執行緒
@Override
public void run() {
//long start = System.currentTimeMillis();
while (isRunning) {
//分析這裏從LinkedBlockingQueue
if (dataQueue.isEmpty()) {
continue;
}
byte[] buffer = device.getMinicap().dataQueue.poll();
int len = buffer.length;
}
在while迴圈中,不斷讀取堵塞佇列dataQueue中的數據,如果數據為空,則執行continue進行下一次迴圈。
如果不為空,則透過poll()方法讀取數據,做相關邏輯處理。
初看這段程式碼好像每什麽問題,但是如果dataQueue物件長期為空的話,這裏就會一直空迴圈,導致CPU飆升。
那麽如果解決呢?
分析LinkedBlockingQueue阻塞佇列的API發現:
//取出佇列中的頭部元素,如果佇列為空則呼叫此方法的執行緒被阻塞等待,直到有元素能被取出,如果等待過程被中斷則丟擲InterruptedException
E take() throws InterruptedException;
//取出佇列中的頭部元素,如果佇列為空返回null
E poll();
這兩種取值的API,顯然take方法更時候這裏的場景。
程式碼修改為:
while (isRunning) {
/* if (device.getMinicap().dataQueue.isEmpty()) {
continue;
}*/
byte[] buffer = new byte[0];
try {
buffer = device.getMinicap().dataQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
……
}
重新開機計畫後,測試發現計畫執行穩定,對應計畫行程的CPU消耗占比不到10%。
END
看完本文有收獲?請轉發分享給更多人
關註「Java編程鴨」,提升Java技能
關註Java編程鴨微信公眾號,後台回復:碼農大禮包可以獲取最新整理的技術資料一份。涵蓋Java 框架學習、架構師學習等!
文章有幫助的話,在看,轉發吧。
謝謝支持喲 (*^__^*)











