點選「 IT碼徒 」, 關註,置頂 公眾號
每日技術幹貨,第一時間送達!
1.常見表運算式(CTEs)
如果您想要查詢子查詢,那就是CTEs施展身手的時候 - CTEs基本上建立了一個臨時表。
使用常用表運算式(CTEs)是模組化和分解程式碼的好方法,與您將文章分解為幾個段落的方式相同。
請在Where子句中使用子查詢進行以下查詢。
SELECT
name,
salary
FROM
People
WHERE
NAMEIN ( SELECTDISTINCTNAMEFROM population WHERE country = "Canada"AND city = "Toronto" )
AND salary >= (
SELECT
AVG( salary )
FROM
salaries
WHERE
gender = "Female")
這似乎似乎難以理解,但如果在查詢中有許多子查詢,那麽怎麽樣?這就是CTEs發揮作用的地方。
with toronto_ppl as (
SELECTDISTINCTname
FROM population
WHERE country = "Canada"
AND city = "Toronto"
)
, avg_female_salary as (
SELECTAVG(salary) as avgSalary
FROM salaries
WHERE gender = "Female"
)
SELECTname
, salary
FROM People
WHEREnamein (SELECTDISTINCTFROM toronto_ppl)
AND salary >= (SELECT avgSalary FROM avg_female_salary)
現在很清楚,Where子句是在多倫多的名稱中過濾。如果您註意到,CTE很有用,因為您可以將代分碼解為較小的塊,但它們也很有用,因為它允許您為每個CTE分配變量名稱(即
toronto_ppl
和
avg_female_salary
)
同樣,CTEs允許您完成更高級的技術,如建立遞迴表。
2.遞迴CTEs.
遞迴CTE是參照自己的CTE,就像Python中的遞迴函式一樣。遞迴CTE尤其有用,它涉及查詢組織結構圖,檔案系統,網頁之間的連結圖等的分層數據,尤其有用。
遞迴CTE有3個部份:
錨構件:返回CTE的基本結果的初始查詢
遞迴成員:參照CTE的遞迴查詢。這是所有與錨構件的聯盟
停止遞迴構件的終止條件
以下是獲取每個員工ID的管理器ID的遞迴CTE的範例:
with org_structure as (
SELECTid
, manager_id
FROM staff_members
WHERE manager_id ISNULL
UNIONALL
SELECT sm.id
, sm.manager_id
FROM staff_members sm
INNERJOIN org_structure os
ON os.id = sm.manager_id
3.臨時函式
如果您想了解有關臨時函式的更多資訊,請檢查此項,但知道如何編寫臨時功能是重要的原因:
它允許您將程式碼的塊分解為較小的程式碼塊
它適用於寫入清潔程式碼
它可以防止重復,並允許您重用類似於使用Python中的函式的程式碼。
考慮以下範例:
SELECTname
, CASEWHEN tenure < 1THEN"analyst"
WHEN tenure BETWEEN1and3THEN"associate"
WHEN tenure BETWEEN3and5THEN"senior"
WHEN tenure > 5THEN"vp"
ELSE"n/a"
ENDAS seniority
FROM employees
相反,您可以利用臨時函式來捕獲案例子句。
CREATETEMPORARYFUNCTION get_seniority(tenure INT64) AS (
CASEWHEN tenure < 1THEN"analyst"
WHEN tenure BETWEEN1and3THEN"associate"
WHEN tenure BETWEEN3and5THEN"senior"
WHEN tenure > 5THEN"vp"
ELSE"n/a"
END
);
SELECTname
, get_seniority(tenure) as seniority
FROM employees
透過臨時函式,查詢本身更簡單,更可讀,您可以重復使用資歷函式!
4.使用CASE WHEN樞轉數據
您很可能會看到許多要求在陳述時使用CASE WHEN的問題,這只是因為它是一種多功能的概念。如果要根據其他變量分配某個值或類,則允許您編寫復雜的條件語句。
較少眾所周知,它還允許您樞轉數據。例如,如果您有一個月列,並且您希望為每個月建立一個單個列,則可以使用語句追溯數據的情況。
範例問題:編寫SQL查詢以重新格式化表,以便每個月有一個收入列。
Initial table:
+------+---------+-------+
| id | revenue | month |
+------+---------+-------+
| 1 | 8000 | Jan |
| 2 | 9000 | Jan |
| 3 | 10000 | Feb |
| 1 | 7000 | Feb |
| 1 | 6000 | Mar |
+------+---------+-------+
Result table:
+------+-------------+-------------+-------------+-----+-----------+
| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue |
+------+-------------+-------------+-------------+-----+-----------+
| 1 | 8000 | 7000 | 6000 | ... | null |
| 2 | 9000 | null | null | ... | null |
| 3 | null | 10000 | null | ... | null |
+------+-------------+-------------+-------------+-----+-----------+
5.EXCEPT vs NOT IN
除了幾乎不相同的操作。它們都用來比較兩個查詢/表之間的行。所說,這兩個人之間存在微妙的細微差別。
首先,除了過濾刪除重復並返回不同的行與不在中的不同行。
同樣,除了在查詢/表中相同數量的列,其中不再與每個查詢/表比較單個列。
6.自聯結
一個SQL表自行連線自己。你可能會認為沒有用,但你會感到驚訝的是這是多麽常見。在許多現實生活中,數據儲存在一個大型表中而不是許多較小的表中。在這種情況下,可能需要自我連線來解決獨特的問題。
讓我們來看看一個例子。
範例問題:給定下面的員工表,寫出一個SQL查詢,了解員工的薪資,這些員工比其管理人員薪資更多。對於上表來說,Joe是唯一一個比他的經理薪資更多的員工。
+----+-------+--------+-----------+
| Id | Name | Salary | ManagerId |
+----+-------+--------+-----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
+----+-------+--------+-----------+Answer:
SELECT
a.Name as Employee
FROM
Employee as a
JOIN Employee as b on a.ManagerID = b.Id
WHERE a.Salary > b.Salary
7.Rank vs Dense Rank vs Row Number
它是一個非常常見的套用,對行和價值進行排名。以下是公司經常使用排名的一些例子:
按購物,利潤等數量排名最高值的客戶
排名銷售數量的頂級產品
以最大的銷售排名頂級國家
排名在觀看的分鐘數,不同觀眾的數量等觀看的頂級視訊。
在SQL中,您可以使用幾種方式將「等級」分配給行,我們將使用範例進行探索。考慮以下Query和結果:
SELECTName
, GPA
, ROW_NUMBER() OVER (ORDERBY GPA desc)
, RANK() OVER (ORDERBY GPA desc)
, DENSE_RANK() OVER (ORDERBY GPA desc)
FROM student_grades

ROW_NUMBER()
返回每行開始的唯一編號。當存在關系時(例如,BOB vs Carrie),
ROW_NUMBER()
如果未定義第二條標準,則任意分配數位。
Rank()
返回從1開始的每行的唯一編號,除了有關系時,
Rank()
將分配相同的數位。同樣,差距將遵循重復的等級。
dense_rank()
類似於
Rank()
,除了重復等級後沒有間隙。請註意,使用
dense_rank()
,Daniel排名第3,而不是第4位元。
8.計算Delta值
另一個常見應用程式是將不同時期的值進行比較。例如,本月和上個月的銷售之間的三角洲是什麽?或者本月和本月去年這個月是什麽?
在將不同時段的值進行比較以計算Deltas時,這是
Lead()
和
LAG()
發揮作用時。
這是一些例子:
# Comparing each month's sales to last month
SELECTmonth
, sales
, sales - LAG(sales, 1) OVER (ORDERBYmonth)
FROM monthly_sales
# Comparing each month's sales to the same month last year
SELECTmonth
, sales
, sales - LAG(sales, 12) OVER (ORDERBYmonth)
FROM monthly_sales
9.計算執行總數
如果你知道關於
row_number()
和
lag()
/
lead()
,這可能對您來說可能不會驚喜。但如果你沒有,這可能是最有用的視窗功能之一,特別是當您想要視覺化增長!
使用具有
SUM()
的視窗函式,我們可以計算執行總數。請參閱下面的範例:
SELECTMonth
, Revenue
, SUM(Revenue) OVER (ORDERBYMonth) AS Cumulative
FROM monthly_revenue
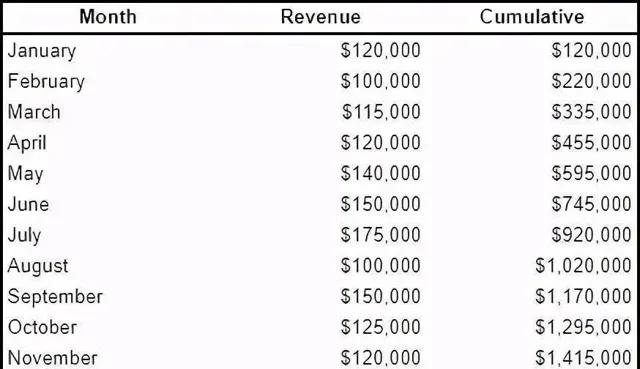
10.日期時間操縱
您應該肯定會期望某種涉及日期時間數據的SQL問題。例如,您可能需要將數據分組組或將可變格式從
DD-MM-Yyyy
轉換為簡單的月份。
範例問題:給定天氣表,寫一個SQL查詢,以尋找與其上一個(昨天)日期相比的溫度較高的所有日期的ID。
+---------+------------------+------------------+
| Id(INT) | RecordDate(DATE) | Temperature(INT) |
+---------+------------------+------------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+---------+------------------+------------------+Answer:
SELECT
a.Id
FROM
Weather a,
Weather b
WHERE
a.Temperature > b.Temperature
ANDDATEDIFF(a.RecordDate, b.RecordDate) = 1
就這樣!我希望這有助於您在面試準備中 - 我相信,如果您知道這10個內部概念,那麽在那裏大多數SQL問題時,你會做得很好。
本文由聞數起舞轉譯自Dimitris Poulopoulos的文章
【Ten Advanced SQL Concepts You Should Know for Data Science Interviews】
原文連結:
https://towardsdatascience.com/ten-advanced-sql-concepts-you-should-know-for-data-science-interviews-4d7015ec74b0
—
END
—
PS:防止找不到本篇文章,可以收藏點贊,方便翻閱尋找哦。
往期推薦











