本文主要介紹離線上資料倉儲建設在攜程旅遊團隊的落地與實踐,將從業務痛點、業務目標、計畫架構、計畫建設等維度展開。
一、業務痛點
隨著數據即時化需求增多,離線數倉暴露出來的業務痛點也越來越多,例如:
即時需求煙囪開發模式
中間數據可復用性差
離線上數據開發割裂
數據生產→服務周期長
即時表/任務雜亂、無法管理
即時血緣/基本資訊/監控等缺失
即時數據:品質監控無工具
即時任務:運維門檻高 品質體系弱
這類典型的問題,會對我們的人效、品質、管理等方面帶來較大考驗,亟待一個體系化的平台來解決。
二、業務目標
圍繞已知業務痛點,依托於公司現有的計算資源、儲存資源、離線數倉標準規範等,我們的目標是在人效、品質、管理這幾個層面進行系統建設。如下圖:
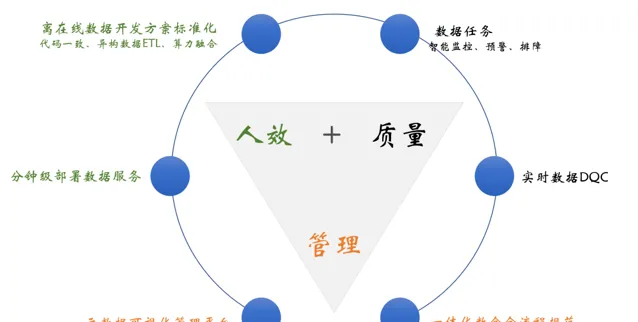
1.人效層面
實作離線上數據開發方案標準化,如標準化數據處理、離線上程式碼相容、算力融合等
分鐘級數據部署,實作BI同學層面的數據介面註冊、釋出、偵錯等視覺化操作
2.品質層面
數據內容DQC,如內容對不對、全不全、是否及時、是否離線上一致等
數據任務預警,如有無延遲、有無反壓、吞吐怎麽樣、系統資源夠不夠等
3.管理層面
視覺化管理平台,如全鏈路血緣、數據表/任務、品質覆蓋率等基本資訊
一體化數倉全流程規範,如數據建模規範、數據品質規範、數據治理規範、儲存選型規範等
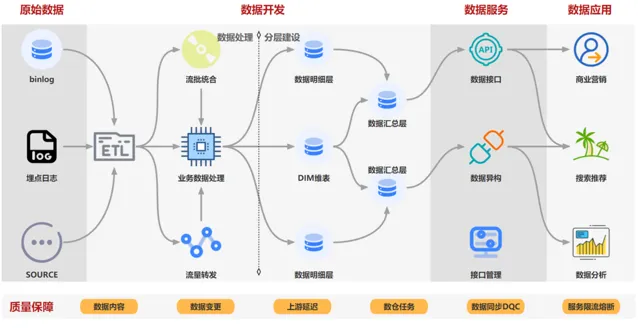
三、計畫架構
計畫架構如下圖,該系統主要包括:原始數據→數據開發 → 數據服務 → 數據品質 → 數據管理等模組,提供即時數據秒級處理、數據服務分鐘級部署的能力,供即時數據開發同學、後端數據服務開發使用。
不同數據來源的數據首先經過標準化ETL元件進行數據標準化,並經過流量轉發工具進行數據預處理,使用流批融合工具以及業務數據處理模組進行分層分域建設,生產好的數據使用數據服務模組直接將數據進行數據api部署,最終供業務套用使用,整個鏈路會有對應的品質和運維保障體系。
四、計畫建設
1.數據開發
該模組主要包含數據預處理工具、數據開發方案選型。
1)流量轉發工具
由於入口多、流量大,主要存在如下問題:
同維度的數據來源、解析方式可能有多種;
使用到的埋點數據占總量的比例大約20%,全量消費資源浪費嚴重,且每個下遊都會重復操作;
新增埋點後,數據處理需要開發介入(極端情況下涉及到全部使用方);
如下圖,流量轉發工具,具備動態接入多個資料來源,並且做簡單的數據處理,並且將有效數據進行標準化後寫入下遊,可解決上述問題。

2)業務數據處理方案演進
① 方案1-離線上數據簡單融合
背景
由於最開始的時候業務需求比較單一,如計算使用者歷史的即時訂單量、聚合使用者歷史購買過的景點資訊等。這類簡單需求可以抽象成離線數據和即時數據簡單聚合,如數值型的加減乘除、字元型的append、去重匯總等。
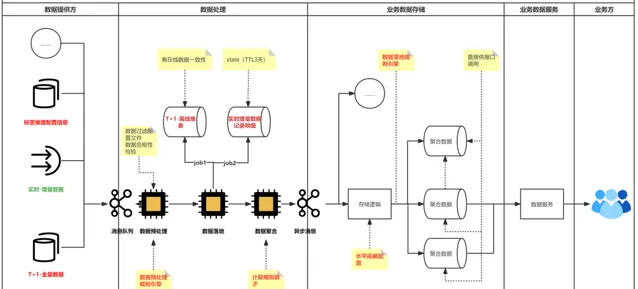
解決方案
如下圖,其中數據提供方:提供標準化的T+1和即時數據接入;數據處理:T+1與即時數據融合;一致性校驗;動態規則引擎處理等;數據儲存:支持聚合數據水平擴充套件;標簽對映等。
② 方案2 - 支持SQL
背景
雖然說方案1有如下優勢:
分層簡單,時效性強
規則配置響應迅速,可承接大量的復雜UDF
規則引擎等處理
相容整個java生態
但是也存在明顯劣勢:
BI SQL開發人員基本無法介入、強依賴開發
SQL很多場景,使用java開發成本高,穩定性差
沒有有效的數據分層
過程數據基本不可用,如果要保存過程數據,需要重復計算,浪費計算資源
解決方案
如下圖,kafka承載數據分層功能,Flink SQL的計算引擎,OLAP承載數據儲存、分層查詢,完成典型的數倉系統分層建設。

但是由於kafka和olap儲存引擎是兩個個體,可能會存在數據不一致的情況,比如kafka正常,資料庫異常,會導致中間分層的數據異常,但是最終結果正常。為了解決上述問題,如下圖,采用了傳統資料庫使用的binlog模式開發,kafka數據強依賴DB的數據變更,這樣最終結果強依賴中間分層結果,還是不能避免元件big導致的數據不一致問題,但大部份場景已經基本可用。

③方案3
背景
雖然說方案2有如下優勢:
SQL化
天然分層查詢
但是也存在明顯劣勢:
數據不一致的問題
binlog在insert的時候沒啥問題,但是更新和刪除不好搞,而且更新的時候要做大量的去重操作,sql很不友好
長時間數據聚合,部份算子如max、min等flink狀態大,容易不穩定
還要考慮kafka數據亂序,導致的數據覆蓋問題
解決方案
如下圖借用儲存引擎的計算能力,kafka的binlog只是作為數據計算的觸發邏輯,直接使用Flink UDF進行直連DB查詢。

優勢:
SQL化
天然分層查詢
數據一致
FLink狀態小
可支持長時間的持久化數據聚合
無需關心binlog亂序、update等帶來的問題
劣勢:
並行扛不起來,強依賴olap引擎效能,我們在資料來源的時候會window限流,或者水平擴容db;
sink時與回撤流結合被打斷,比如:group by,其實就是無腦的upsert,udf的聚合沒法替代flink原生的聚合;
各個方案都有適用場景,需要根據不同的業務場景和延遲需求,進行方案選型。目前我們86%的場景都可以使用方案3進行承接,並且由於Flink 1.16各類離線上一體的特性加持,後期基本可覆蓋全部場景。
2.數據服務
該模組提供了數據同步 → 數據儲存 → 數據查詢 → 數據服務等能力,簡單場景可實作分鐘級的數據服務部署能力,可節約90%的開發工時。實作了離線數據DQC強依賴、工程側DQC異常兜底、客戶端->介面級別的資源隔離/限流/熔斷、全鏈路血緣(客戶端 → 伺服端 → 表 → hive表 → hive血緣)管理等,提供了按需進行各類效能要求介面部署和運維保障能力。
架構如下:

3.數據品質
該模組主要分為數據內容品質和數據任務品質。
1)數據內容
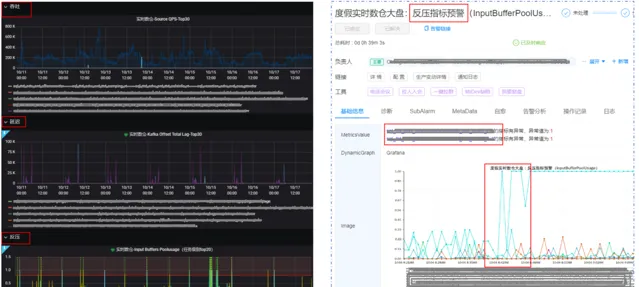
①正確性/及時性/穩定性
該部份又分為數據操作變化、數據內容一致性、數據讀取一致性、數據正確性/及時性等。如下圖所示,數據變更:如果異常,可將數據打入公司的hickwall告警中台,並根據預警規則告警。數據內容:會有定時任務,執行使用者自訂的sql語句,將數據寫入告警中台,可實作秒級和分鐘級預警。

②讀取一致性
如下圖,數據讀取時,如果存在跨表的聯合查詢,如果其中某張表出現問題,大多數情況下不會展示錯誤數據,只會展示歷史上的正確數據,待該表恢復後才會全部展示。

如:外露需要將表1和表2的數據做除法(表1/表2),如果表2數據生產異常,最近2小時沒數據,在外露給使用者時,業務需要只是展示2小時之前的數據,異常數據給出前端異常提醒 參照flink watermark的概念,將正確數據對其進行外顯。
③離線上一致性
關於離線和即時的數據一致性。如下圖,我們采用較為簡單的方法,直接將即時數據同步至hudi,並且使用hudi進行離線和即時數據對比,打入告警中台。

2)數據任務
①上遊任務
依托公司自訂預警埋點、告警中台、計算平台等工具,可將上遊的訊息佇列是否延遲、量是否異常等關鍵指標進行監控預警。

②當前任務
可將數據處理任務的吞吐、延遲、反壓、資源等關鍵指標進行監控預警,避免數據任務長時間異常。
4.數據管理
該模組可將數據處理、品質等各模組進行串聯,提供視覺化的管理平台,如:表血緣/基本資訊、DQC配置、任務狀態、監控等。
下圖為各數據表上下遊數據生產任務血緣關系。

下圖為數據表品質資訊詳情。

下圖為各類UDF表的基本資訊匯總。

五、展望
目前該系統基本上已經能承接團隊絕大多數數據開發需求,後期我們會在可靠性、穩定性、易用性等層面繼續探索,如完善整個數據治理體系、建設自動數據恢復工具、排障運維智慧元件、服務分析一體化探索等。
作者丨Chengrui
來源丨公眾號:攜程技術(ID:ctriptech)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱:[email protected]












