一、儲存高可用
對於需要儲存數據的系統來說,整個系統的高可用設計關鍵點和難點就在於「儲存高可用」,儲存與計算相比,有一個本質上的區別:將數據從一台機器同步到另一台機器,需要經過路線進行傳輸。傳輸的速度,同一機房能夠做到毫秒級,分布在不同地方的機房,傳輸耗時需要幾十甚至上百毫秒。
雖然毫秒級對人來說幾乎沒有什麽感覺,但對於要求高可用的系統來說,就是本質上的區別。
以最經典的銀行儲蓄業務為例,假設使用者的數據存在北京機房,使用者存了1萬塊錢,然後它查詢的時候被路由到了上海機房,此時使用者肯定後背一涼,馬上懷疑自己的錢被盜了,然後趕緊打客戶電話投訴,甚至打110報警,即使最後發現只是因為傳輸延遲導致的問題,使用者的體驗也是極差的。
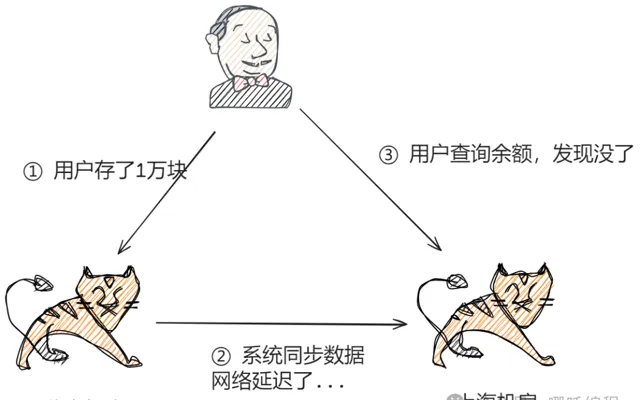
除了物理上的傳輸速度限制,傳輸路線本身也存在可用性問題,傳輸路線可能中斷、可能擁塞、可能異常,並且傳輸路線的故障時間一般都特別長,短的十幾分鐘,長的幾個小時。
例如,2015年支付寶因為光纜被挖斷,業務影響超過4個小時,2016年中美海底光纜中斷3小時。
在傳輸路線中斷的情況下,就意味著儲存無法進行同步,在這段時間內整個系統的數據是不一致的。
因此,儲存高可用的難點不在於如何備份數據,而在於如何減少或規避數據不一致對業務造成的影響。
分布式領域有一個著名的CAP定理,從理論上論證了儲存高可用的復雜度。儲存高可用不可能同時滿足「一致性、可用性、分區容錯性」,最多滿足其中2個,這就要求我們在做架構設計的時候結合業務進行取舍了。
二、讀寫分離
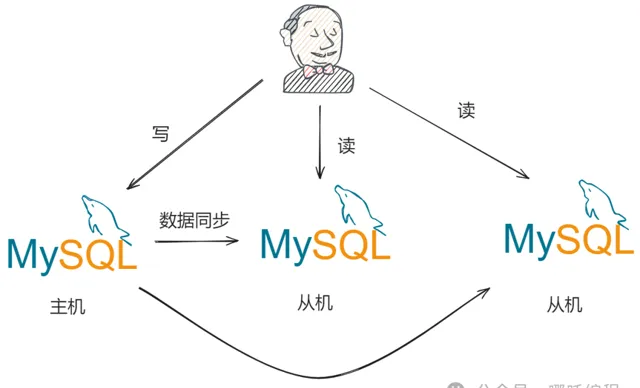
讀寫分離的基本實作原理:
資料庫伺服器搭建主從集群,一主二從
資料庫主機負責寫操作,從機負責讀操作
資料庫主機透過復制將數據同步到從機,每台資料庫伺服器都儲存了所有的業務數據
業務伺服器將寫操作發給資料庫主機,將讀操作發給資料庫從機
讀寫分離的實作邏輯並不復雜,但在實際套用過程中需要應對復制延遲帶來的復雜性。
以MySQL為例,主從復制延遲可能達到1S,如果有大量數據同步,延遲1分鐘也是有可能的。
主從復制延遲會帶來一個問題,如果業務伺服器將數據寫入到資料庫主伺服器後立刻(1S)內進行讀取,此時讀操作存取的是從機,從機還沒有將數據復制過來,此時使用者讀取的就不是最新數據,業務上可能會存在問題。
例如,使用者剛註冊完後立刻登入,業務伺服器會提示「你還沒有註冊」,而使用者剛才已經註冊成功了。
三、解決主從復制延遲問題的幾種方案
1、寫操作後的讀操作指定發給資料庫主伺服器
2、讀從機失敗後再讀一次主機
這就是大家常說的二次讀取,二次讀取和業務無繫結,只需要對底層資料庫存取的API進行封裝即可,實作代價較小,不足之處在於如果有很多二次讀取,將大大增加主機的讀操作壓力。
3、關鍵業務讀寫操作全部指向主機,非關鍵業務采用讀寫分離
對於不要求即時性的操作,可以透過異步處理,將一些耗時的操作延後執行。
4、壓縮與批次傳輸
透過開啟Binlog壓縮功能,減少傳輸數據量,降低網路負擔。
在可能的情況下,批次傳輸數據,而不是逐條記錄傳輸,以提高傳輸效率。
5、最佳化從庫的查詢效能
在從庫上建立合理的索引結構,以減少查詢的響應時間。
6、最佳化網路延遲
確保主從資料庫之間的網路頻寬充足,並且網路延遲盡可能低。可以透過提高頻寬、最佳化網路拓撲結構,或者使用專線等方式減少延遲。
使用網路監控工具監控網路品質,及時發現並解決網路異常問題。
7、調整復制參數
使用半同步復制(Semi-Synchronous Replication)替代完全同步復制,以減少主庫等待從庫確認的時間。
MySQL 5.6及以上版本支持多執行緒復制,可以透過增加slave_parallel_workers的值來啟用多執行緒復制,從而加速從庫的並行執行。
增加sync_binlog與innodb_flush_log_at_trx_commit的值:這些參數影響主庫的Binlog重新整理頻率,適當調整可以減少延遲。
8、監控與報警機制
透過SHOW SLAVE STATUS命令監控從庫的復制延遲情況,並設定報警機制,及時處理復制延遲問題。
配置MySQL的自動故障轉移(Failover)機制,在主庫出現問題時自動切換到從庫。
9、提高從庫的硬體效能
為從庫配置更高效能的CPU和記憶體,以提高SQL執行效率。
使用SSD替代HDD以提高磁盤讀寫速度,從而減少I/O等待時間。
四、半同步復制是什麽
半同步復制是MySQL的一種復制模式,它介於全同步復制和異步復制之間,旨在在保證數據一致性和系統效能之間取得平衡。
在傳統的異步復制模式中,主庫在執行完一條事務後,只需將二進制日誌(Binlog)寫入本地檔並立即返回給客戶端,表示事務送出成功。隨後,這些日誌會異步地發送到從庫,從庫再進行重放。這種方式效能較好,但在主庫故障時可能會導致部份事務遺失,因為這些事務還沒有被從庫接收到。
而在半同步復制中,當主庫執行完一條事務並寫入Binlog後,不會立即返回給客戶端,而是會等待至少一個從庫確認已經接收到這個Binlog。只有在收到從庫的確認訊號後,主庫才會返回事務送出成功的響應給客戶端。如果在設定的超時時間內沒有收到從庫的確認,主庫會回退到異步復制模式,以保證系統的可用性。
五、半同步復制的優缺點
1、半同步復制的優點
(1)數據安全性增強
由於主庫在返回事務送出成功之前,至少要確認一個從庫已經接收到了該事務的Binlog,因此可以減少數據遺失的風險。
(2)更快的故障恢復
即使主庫發生故障,從庫已經接收到的事務數據可以使從庫迅速接替主庫角色,減少數據恢復的時間。
2、半同步復制的缺點
(1)效能開銷
半同步復制需要等待從庫的確認,會增加事務的送出時間,導致延遲增大,尤其是在網路延遲較大的情況下。
(2)依賴網路
如果網路狀況不好,可能頻繁超時回退到異步模式,降低整體系統的效率。
六、半同步復制的流程
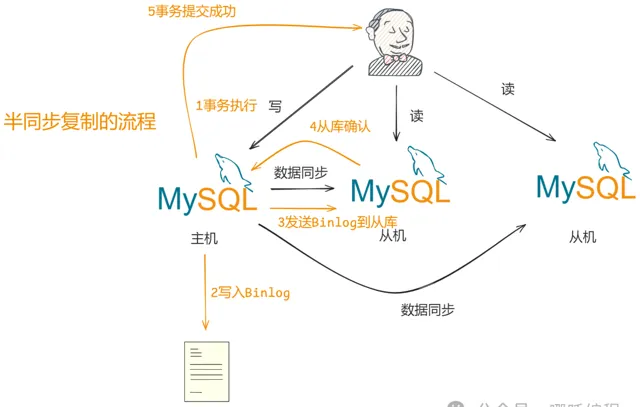
事務執行:客戶端在主庫上執行事務,事務在主庫的儲存引擎層完成。
寫入Binlog:主庫將事務記錄寫入二進制日誌(Binlog)。
發送Binlog到從庫:主庫將Binlog發送到至少一個從庫。
從庫確認:從庫接收到Binlog後,會立即返回一個確認訊號給主庫,表示已經接收到並寫入Relay Log。
事務送出成功:主庫在收到至少一個從庫的確認後,返回事務送出成功的響應給客戶端。
如果主庫在一定時間內沒有收到從庫的確認訊號,會回退到異步模式繼續執行,以避免系統停滯。
半同步復制適用於那些對數據一致性要求較高,但又不能接受全同步復制帶來的高延遲的場景。
常見套用場景包括:
金融系統:交易數據需要盡可能保證一致性,但仍需要一定的效能。
高可用集群:在保證一定程度的數據一致性的同時,允許快速故障切換。
透過配置半同步復制,MySQL可以在效能和數據一致性之間取得一定的平衡,減少數據遺失的風險。
如此浪潮下,作為程式設計師的你,還沒用過ChatGPT4o嗎?還沒用過Copilot嗎?
國內直接使用ChatGPT4o:
谷歌瀏覽器直接使用:https://www.nezhasoft.cn
無需魔法,同時支持手機、電腦
個人獨享
ChatGPT4o mini永久免費
支持Copilot、DALLE AI繪畫、上傳檔等
長按辨識下方二維碼,備註ai,發給你


回復gpt,獲取ChatGPT4o直接使用地址
點選閱讀原文,國內直接使用ChatGpt4o











