點選上方藍字關註我們
❝
OpenVINO™ C# API 是一個 OpenVINO™ 的 .Net wrapper,套用最新的 OpenVINO™ 庫開發,透過 OpenVINO™ C API 實作 .Net 對 OpenVINO™ Runtime 呼叫。Segment Anything Model(SAM)是一個基於Transformer的深度學習模型,主要套用於影像分割領域。在本文中,我們將演示如何在C#中使用OpenVINO™部署 Segment Anything Model 實作任意目標分割。
OpenVINO™ C# API計畫連結:
https://github.com/guojin-yan/OpenVINO-CSharp-API.git
使用 OpenVINO™ C# API 部署 Segment Anything Model 全部源碼:
https://github.com/guojin-yan/segment-anything-csharp/blob/master/src/segment_anything_openvino/Program.cs
1. 前言
1.1 OpenVINO™ C# API
英特爾發行版 OpenVINO™ 工具套件基於 oneAPI 而開發,可以加快高效能電腦視覺和深度學習視覺套用開發速度工具套件,適用於從邊緣到雲的各種英特爾平台上,幫助使用者更快地將更準確的真實世界結果部署到生產系統中。透過簡化的開發工作流程,OpenVINO™ 可賦能開發者在現實世界中部署高效能應用程式和演算法。
2024年4月25日,英特爾釋出了開源 OpenVINO™ 2024.1 工具包,用於在各種硬體上最佳化和部署人工智慧推理。更新了更多的 Gen AI 覆蓋範圍和框架整合,以最大限度地減少程式碼更改。同時提供了更廣泛的 LLM 模型支持和更多的模型壓縮技術。透過壓縮嵌入的額外最佳化減少了 LLM 編譯時間,改進了采用英特爾®高級矩陣擴充套件 (Intel® AMX) 的第 4 代和第 5 代英特爾®至強®處理器上 LLM 的第 1 令牌效能。透過對英特爾®銳炫™ GPU 的 oneDNN、INT4 和 INT8 支持,實作更好的 LLM 壓縮和改進的效能。最後實作了更高的可移植性和效能,可在邊緣、雲端或本地執行 AI。
OpenVINO™ C# API 是一個 OpenVINO™ 的 .Net wrapper,套用最新的 OpenVINO™ 庫開發,透過 OpenVINO™ C API 實作 .Net 對 OpenVINO™ Runtime 呼叫,使用習慣與 OpenVINO™ C++ API 一致。OpenVINO™ C# API 由於是基於 OpenVINO™ 開發,所支持的平台與 OpenVINO™ 完全一致,具體資訊可以參考 OpenVINO™。透過使用 OpenVINO™ C# API,可以在 .NET、.NET Framework等框架下使用 C# 語言實作深度學習模型在指定平台推理加速。
1.2 Segment Anything Model (SAM)
Segment Anything Model(SAM)是一個基於Transformer的深度學習模型,主要套用於影像分割領域。SAM采用了Transformer架構,主要由編碼器和解碼器組成,編碼器負責將輸入的影像資訊編碼成上下文向量,而解碼器則將上下文向量轉化為具體的分割輸出。

SAM的核心思想是「自適應分割」,即能夠根據不同影像或視訊中的物件,自動學習如何對其進行精確分割;並且具有零樣本遷移到其他任務中的能力,這意味著它可以對訓練過程中未曾遇到過的物體和影像型別進行分割;SAM被視為視覺領域的通用大模型,其泛化能力強,可以涵蓋廣泛的用例,並且可以在新的影像領域上即時套用,無需額外的訓練。

總的來說,Segment Anything Model(SAM)是一個先進的影像分割模型,以其強大的自適應分割能力、零樣本遷移能力和通用性而著稱。然而,在實際套用中仍需註意其泛化能力和域適應方面的挑戰。
2. 模型下載與轉換
2.1 安裝環境
該程式碼要求「python>=3.8」,以及「pytorch>=1.7」和「torchvision>=0.8」。請按照此處的說明操作(https://pytorch.org/get-started/locally/)以安裝PyTorch和TorchVision依賴項。
pip install git+https://github.com/facebookresearch/segment-anything.git
然後安裝一些其他的依賴項:
pip install opencv-python pycocotools matplotlib onnxruntime onnx
2.2 下載模型
此處直接下載官方訓練好的模型:
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
2.3 模型轉換
此處模型轉換使用Python實作,上面我們已經安裝好了模型轉換環境,下面首先匯入所需要的程式包,如下所示:
import torch
from segment_anything import sam_model_registry
from segment_anything.utils.onnx import SamOnnxModel
然後匯出編碼器模型,編碼器負責將輸入的影像資訊編碼成上下文向量,因此其模型輸入輸出結構相對較為簡單,轉換程式碼如下所示:
torch.onnx.export(
f="vit_b_encoder.onnx",
model=sam.image_encoder,
args=torch.randn(1, 3, 1024, 1024),
input_names=["images"],
output_names=["embeddings"],
export_params=True)
接下來轉換解碼器模型,解碼器則將上下文向量轉化為具體的分割輸出,因此在輸入時需要指定分割的位置資訊,所以其輸入比較多,,分別為:
image_embeddings: 編碼器模型對圖片編碼後的輸出內容,在使用時直接將編碼器模型執行後的輸出載入到該模型輸入節點即可。
point_coords: 輸入的提示座標或位置,對應點輸入和框輸入。方框使用兩個點進行編碼,一個用於左上角,另一個用於右下角。座標必須已轉換為長邊1024。具有長度為1的批索引。
point_labels: 稀疏輸入提示的標簽,0是負輸入點,1是正輸入點,2是輸入框左上角,3是輸入框右下角,-1是填充點。如果沒有框輸入,則應連線標簽為-1且座標為(0.0,0.0)的單個填充點。
mask_input: 形狀為1x1x256x256的模型的掩碼輸入,如果沒有掩碼輸入,也必須提供全為0的輸入。
has_mask_input: 掩碼輸入的指示符。1表示掩碼輸入,0表示沒有掩碼輸入。
orig_im_size: 表示原始圖片形狀大小,輸入格式(H,W)。
模型轉換程式碼如下所示:
checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
onnx_model = SamOnnxModel(sam, return_single_mask=True)
embed_dim = sam.prompt_encoder.embed_dim
embed_size = sam.prompt_encoder.image_embedding_size
mask_input_size = [4 * x for x in embed_size]
dummy_inputs = {
"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float),
"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float),
"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float),
"mask_input": torch.randn(1, 1, *mask_input_size, dtype=torch.float),
"has_mask_input": torch.tensor([1], dtype=torch.float),
"orig_im_size": torch.tensor([1500, 2250], dtype=torch.float),
}
output_names = ["masks", "iou_predictions", "low_res_masks"]
torch.onnx.export(
f="vit_b_decoder.onnx",
model=onnx_model,
args=tuple(dummy_inputs.values()),
input_names=list(dummy_inputs.keys()),
output_names=output_names,
dynamic_axes={
"point_coords": {1: "num_points"},
"point_labels": {1: "num_points"}
},
export_params=True,
opset_version=17,
do_constant_folding=True
)
3. 模型部署程式碼
3.1 編碼器模型部署程式碼
staticfloat[] ImageEmbeddings(Mat img, string model_path)
{
Core core = new Core();
Model model = core.read_model(model_path);
OvExtensions.printf_model_info(model);
CompiledModel compiled = core.compile_model(model, "CPU");
Console.WriteLine("Compile Model Sucessfully!");
InferRequest request = compiled.create_infer_request();
Mat mat = new Mat();
Cv2.CvtColor(img, mat, ColorConversionCodes.BGR2RGB);
float factor = 0;
mat = Resize.letterbox_img(mat, 1024, out factor);
mat = Normalize.run(mat, newfloat[] { 123.675f, 116.28f, 103.53f }, newfloat[] { 1.0f / 58.395f, 1.0f / 57.12f, 1.0f / 57.375f }, false);
Tensor input_tensor = request.get_input_tensor();
float[] input_data = Permute.run(mat);
input_tensor.set_data(input_data);
Stopwatch sw = new Stopwatch();
sw.Start();
request.infer();
sw.Stop();
Console.WriteLine("Inference time: " + sw.ElapsedMilliseconds);
Tensor output_tensor = request.get_output_tensor();
Console.WriteLine(output_tensor.get_shape().to_string());
return output_tensor.get_data<float>((int)output_tensor.get_size());
}
3.2 解碼器模型部署程式碼
staticbyte[] ImageDecodings(string model_path, float[] image_embeddings, float[] onnx_coord,
float[] onnx_label, float[] onnx_mask_input, float[] onnx_has_mask_input, float[] img_size)
{
Core core = new Core();
Model model = core.read_model(model_path);
OvExtensions.printf_model_info(model);
CompiledModel compiled = core.compile_model(model, "CPU");
Console.WriteLine("Compile Model Sucessfully!");
InferRequest request = compiled.create_infer_request();
Tensor tensor1 = request.get_tensor("image_embeddings");
tensor1.set_data(image_embeddings);
Tensor tensor2 = request.get_tensor("point_coords");
tensor2.set_shape(new Shape(1, 3, 2));
tensor2.set_data(onnx_coord);
Tensor tensor3 = request.get_tensor("point_labels");
tensor3.set_shape(new Shape(1, 3));
tensor3.set_data(onnx_label);
Tensor tensor4 = request.get_tensor("mask_input");
tensor4.set_data(onnx_mask_input);
Tensor tensor5 = request.get_tensor("has_mask_input");
tensor5.set_data(onnx_has_mask_input);
Tensor tensor6 = request.get_tensor("orig_im_size");
tensor6.set_data(img_size);
Stopwatch sw = new Stopwatch();
sw.Start();
request.infer();
sw.Stop();
Console.WriteLine("Inference time: " + sw.ElapsedMilliseconds);
Tensor output_tensor = request.get_tensor("masks");
float[] mask_data = output_tensor.get_data<float>((int)output_tensor.get_size());
byte[] mask_data_byte = newbyte[mask_data.Length];
for (int i = 0; i < mask_data.Length; i++)
{
mask_data_byte[i] = (byte)(mask_data[i] > 0 ? 255 : 0);
}
return mask_data_byte;
}
4. 模型部署測試程式碼
下面是模型部署案例測試程式碼,透過呼叫
staticvoidMain(string[] args)
{
string embedding_model = "./../../../../../model/vit_b_encoder/vit_b_encoder.onnx";
string decoding_model = "./../../../../../model/vit_b_decoder.onnx";
string image_path = "./../../../../../images/dog.jpg";
string image_embedding_path = "./../../../../../images/dog.bin";
Mat img = Cv2.ImRead(image_path);
float factor = 0;
Resize.letterbox_img(img, 1024, out factor);
if (!File.Exists(image_embedding_path))
{
float[] data = ImageEmbeddings(img, embedding_model);
SaveToFile(data, image_embedding_path);
}
float[] image_embedding_data = LoadFromFile(image_embedding_path);
float[] onnx_coord = newfloat[6] { 600f / factor, 200f / factor, 480 / factor, 130 / factor, (480 + 190)/factor, (130 + 140)/factor };
float[] onnx_label = newfloat[3] { 1f, 2f, 3f };
float[] onnx_mask_input = newfloat[256 * 256];
float[] onnx_has_mask_input = newfloat[1] { 0 };
float[] img_size = newfloat[2] { img.Height, img.Width };
byte[] result = ImageDecodings(decoding_model, image_embedding_data, onnx_coord, onnx_label, onnx_mask_input, onnx_has_mask_input, img_size);
Cv2.Rectangle(img, new Rect(600, 200, 20, 20), new Scalar(0, 0, 255), -1);
Cv2.Rectangle(img, new Rect(480, 130, 190, 140), new Scalar(0, 255, 255), 2);
Mat mask = new Mat(img.Rows, img.Cols, MatType.CV_8UC1, result);
Mat rgb_mask = Mat.Zeros(new Size(img.Cols, img.Rows), MatType.CV_8UC3);
Cv2.Add(rgb_mask, new Scalar(255.0, 144.0, 37.0, 0.6), rgb_mask, mask);
Mat new_mat = new Mat();
Cv2.AddWeighted(img, 0.5, rgb_mask, 0.5, 0.0, new_mat);
Cv2.ImShow("mask", new_mat);
Cv2.WaitKey(0);
}
5. 預測效果
下面展示了幾個預測效果情況:

該圖在輸入時指定了兩個標記點,同時標註在了車身和車窗上,那麽就會根據所標記的點提取,兩個點都是在車上,因此最後分割出來的結果是車身。

與上一張圖片不同的shi,在這張圖片中我們只標記了車窗位置,因此分割結果只分割了車窗位置。

同樣地在這張圖片中我們標記了狗狗,因此他最終分割出來了狗狗的位置。
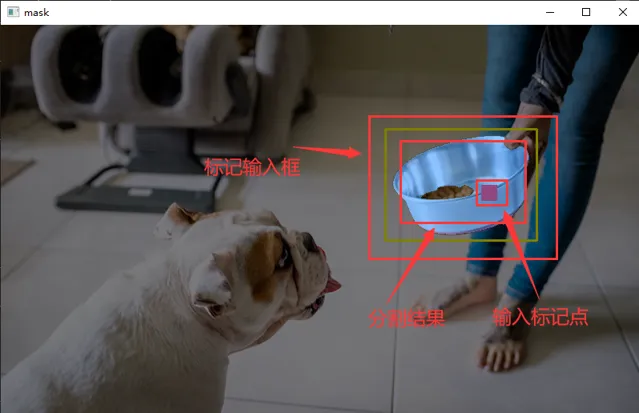
下面我們對圖片中的飯盆進行分割,我們標記了飯盆,並輸入了一個範圍框,這樣模型在這個範圍裏分割出了飯盆。
6. 總結
在該計畫中,我們演示了如何在C#中使用OpenVINO™部署 Segment Anything Model 實作任意目標分割。最後如果各位開發者在使用中有任何問題,以及對該介面開發有任何建議,歡迎大家與我聯系。

推薦閱讀
●
●
●
●
●
●










