LangChain 是一個開源框架,旨在簡化使用大型語言模型 (LLM) 建立應用程式的過程。可以將其想象成一套使用高級語言工具進行搭建的樂高積木。
它對於想要構建復雜的基於語言的應用程式而又不必管理直接與語言模型互動的復雜性的開發人員特別有用。它簡化了將這些模型整合到應用程式中的過程,使開發人員能夠更加專註於應用程式邏輯和使用者體驗。
unset unset LLMs unset unset
「LLM」 代表「大型語言模型」,這是一種旨在大規模理解、生成和與人類語言互動的人工智慧模型。這些模型在大量文本數據上進行訓練,可以執行各種與語言相關的任務。
這些模型最初透過辨識和解釋單詞與更廣泛概念之間的關系來建立基礎理解。這一初始階段為進一步的微調奠定了基礎。微調過程涉及監督學習,其中使用有針對性的數據和特定反饋對模型進行微調。此步驟可提高模型在各種情況下的準確性和相關性。
unset unset Transformer unset unset
訓練數據透過一種稱為 Transformer 的專門神經網路架構進行處理。這是大型語言模型 (LLM) 開發的關鍵階段。
從非常高層次的概述來看,編碼器處理輸入數據(例如一種語言的句子)並將資訊壓縮為上下文向量。然後解碼器獲取此上下文向量並生成輸出(例如將句子轉譯成另一種語言)。
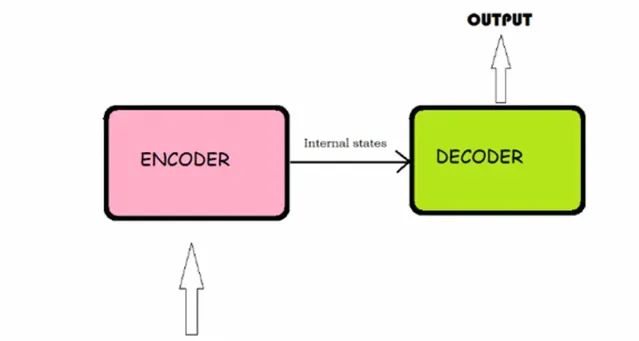
編碼器和解碼器具有「自註意力」機制,這使得模型可以對輸入數據的不同部份的重要性賦予不同的權重。
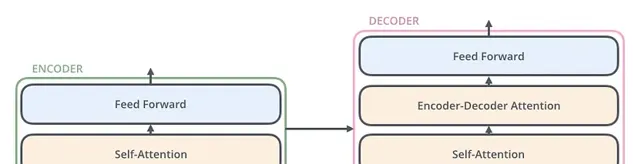
自註意力機制讓模型在處理特定單詞或短語時能夠關註輸入文本的不同部份。對於每個單詞,模型會評估句子中所有其他單詞與其的相關性,並為這些關系分配權重。這些權重有助於模型更全面地理解句子結構和含義,從而生成更準確、更符合語境的回復或轉譯。
unset unset 大模型(LLM) unset unset
專有模型:這些是由公司開發和控制的 AI 模型。它們通常提供高效能,並得到大量資源和研究的支持。然而,它們的使用成本可能很高,可能具有限制性授權證,並且其內部工作原理通常不透明(閉源)。
開源模型:相比之下,開源 AI 模型可供任何人免費使用、修改和分發。它們促進社群內的協作和創新,並提供更大的靈活性。然而,它們的效能可能並不總是與專有模型相匹配,而且它們可能缺乏大公司提供的廣泛支持和資源。

這些模型之間的選擇涉及效能、成本、易用性和靈活性方面的權衡。開發人員必須決定是選擇可能更強大但限制更多的專有模型,還是更靈活但可能不夠完善的開源替代方案。這一選擇反映了軟體開發中早期的決策點,例如 Linux 所呈現的決策點,標誌著 AI 技術及其可存取性發展的重要階段。
unset unset Langchain unset unset
Langchain 有助於存取和合並來自各種來源(例如資料庫、網站或其他外部儲存庫)的數據到使用 LLM 的應用程式中。
unset unset VectorStore向量儲存 unset unset
它將文件轉換為向量儲存。文件中的文本被轉換為稱為向量的數學表示,向量的表示稱為嵌入。
當 Langchain 處理文件時,它會為文本內容生成嵌入。
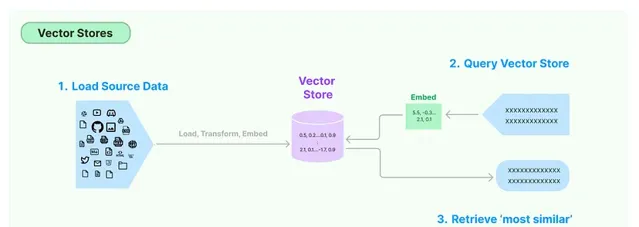
從文件建立的嵌入填充了 Vector Store。文件中的每段文本都表示為該儲存中的一個向量(嵌入)。因此,Vector Store 成為這些嵌入的儲存庫,以數學和語意豐富的格式表示原始文件的內容。
當您有「Transformer 是什麽?」這樣的問題時,大型語言模型 (LLM) 首先會將此問題轉換為嵌入。這意味著 LLM 將問題轉換為與儲存在向量儲存中的數據相同的向量格式。此轉換可確保問題和儲存的資訊具有可比的格式。
現在問題已變成向量格式,LLM 可以有效地搜尋向量儲存。此查詢過程的核心是相似性搜尋。LLM 評估問題的向量與向量儲存中的每個向量的相似程度。
進行相似性搜尋後,LLM 會辨識向量庫中與問題向量最相似的向量。然後,這些向量會被重新轉譯成文本形式,從而檢索出與問題最相關、最相似的資訊。
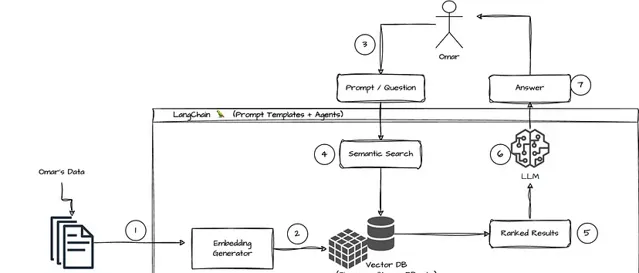
unset unset 元件 unset unset
Langchain 提供各種元件,使得在不同套用環境中整合和管理模型變得更加容易。
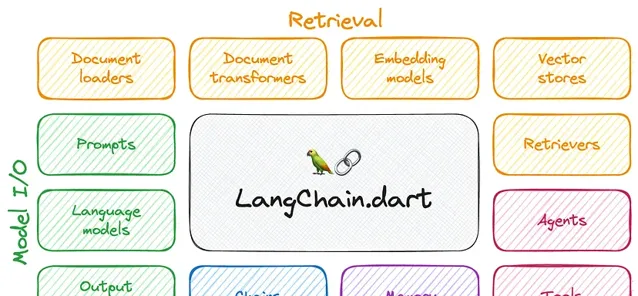
文件載入器 是旨在簡化從各種來源匯入和處理文本數據的實用程式。
文件轉換器 對文本數據進行各種轉換,使其格式更有利於大型語言模型 (LLM) 進行分析和處理。
文本嵌入模型 專註於將文本數據轉換為嵌入。
向量儲存 作為用於儲存和管理嵌入的專用資料庫。
檢索器 旨在根據給定的查詢從向量儲存中有效地檢索相關資訊。
工具 執行特定任務和操作。例如,Bing 搜尋工具是一個 API,用於將 Bing 搜尋與 LLM 結合使用。
代理 代表一種高級抽象,用於協調不同 Langchain 元件與終端使用者之間的互動。它充當 LLM 和工具之間的中介,處理使用者查詢,使用 Langchain 中的適當模型和工具進行處理,然後將結果返回給使用者。
記憶 元件提供了一種記住和參考過去的互動或資訊的機制。
鏈 透過將 LLM 可以執行的各種任務連結在一起,有助於構建多步驟工作流或流程。此元件允許按順序執行不同的語言任務,例如資訊檢索,然後是文本摘要或問答。透過建立這些任務鏈,Langchain 可以與 LLM 進行更復雜、更細致的互動和操作。
Langchain 的LLM和聊天模型元件提供了一個框架,用於在應用程式內整合和管理各種大型語言模型(LLM),包括專門的聊天模型。
提示 和 解析器 簡化了模型的輸入和輸出。
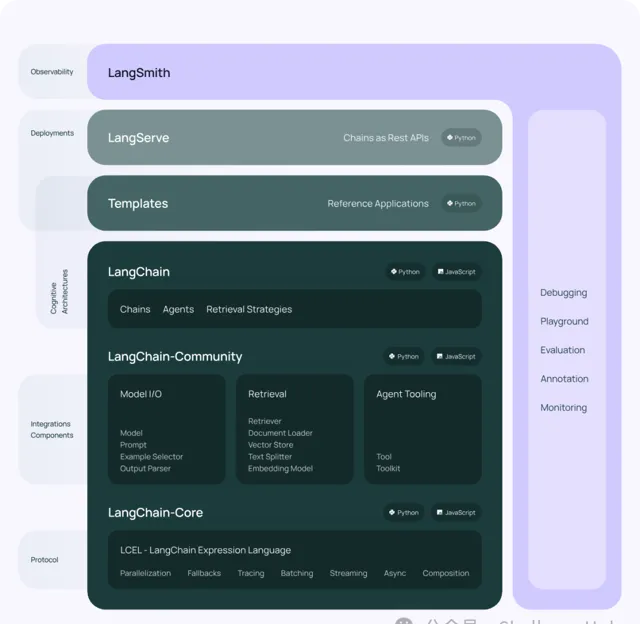
unset unset LangChain 的核心元件 unset unset
模型 I/O 封裝
LLMs:大語言模型
Chat Models:一般基於 LLMs,但按對話結構重新封裝
PromptTemple:提示詞樣版
OutputParser:解析輸出
數據連線封裝
Document Loaders:各種格式檔的載入器
Document Transformers:對文件的常用操作,如:split, filter, translate, extract metadata, etc
Text Embedding Models:文本向量化表示,用於檢索等操作
Verctorstores: (面向檢索的)向量的儲存,保存了向量索引以及文件資訊
Retrievers: 向量的檢索
記憶封裝
Memory:這裏不是實體記憶體,從文本的角度,可以理解為「上文」、「歷史記錄」或者說「記憶力」的管理
架構封裝
Chain:實作一個功能或者一系列順序功能組合
Agent:根據使用者輸入,自動規劃執行步驟,自動選擇每步需要的工具,最終完成使用者指定的功能
Tools:呼叫外部功能的函式,例如:調 google 搜尋、檔 I/O、Linux Shell 等等
Toolkits:操作某軟體的一組工具集,例如:操作 DB、操作 Gmail 等等
Callbacks

功能模組:https://python.langchain.com/docs/get_started/introduction
API 文件:https://api.python.langchain.com/en/latest/langchain_api_reference.html
三方元件整合:https://python.langchain.com/docs/integrations/platforms/
官方套用案例:https://python.langchain.com/docs/use_cases
偵錯部署等指導:https://python.langchain.com/docs/guides/debuggin
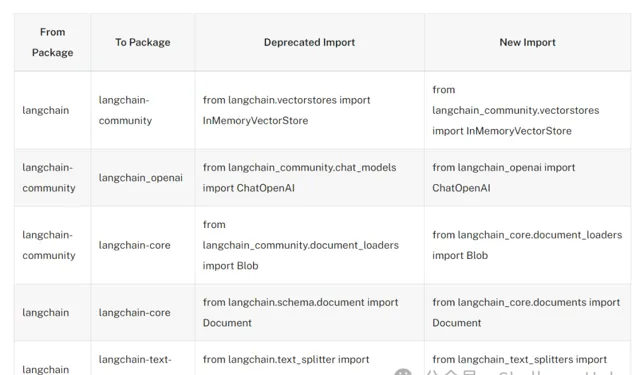
unset unset langchain v0.2升級 unset unset
langchain v0.2匯入方式發生了變化,具體模組可以參考以下API文件
https://api.python.langchain.com/en/latest/langchain_api_reference.html
使用前用下面命令進行安裝:
pip install langchain
pip install langchain-core
pip install langchain-text-splitters
pip install langchain-huggingface
pip install langchain_openai==0.1.8
unset unset 參考資料 unset unset
LangChain框架介紹
LangChain in Chains #1: A Closer Look










